

Nowadays people heavily rely on push notifications, quick reads, summaries, and abstracts in their day to day lives. Most of them start their days by getting informed – be it the headline for the day or the minutes of the previous meeting at work. Generating such summaries solves a lot of challenges. Text summarization is the technique of shortening long documents or texts into crisp, coherent and fluent abstracts while carrying all the important information. For a machine to be able to do so, it needs to comprehend and absorb the information given to it and learn to output the important words while maintaining the sequence.
What Are the Types of Automatic Text Summarization Methods?
Summarization methods can be broadly classified into two ways based on the type of output. They are – Extractive summarization and Abstractive summarization. In the former, the generated summary is the concatenation of important parts of the input text. It often contains words, especially pronouns, which are carried along as they are, making it obscure to what it’s referring to. In the latter, the machine searches the space of all possible summaries to find the most likely sequence of words and hence generates entirely new phrases. This approach is more challenging but also gives better results as compared to the former.
Extractive Summarization
Words can be represented as vectors using the word2vec library. These vectors collectively form a sentence which is also a vector of a fixed dimension called ‘length’. Group of such sentences is bundled together as a page and the whole document is divided into pages. Null padding is done for pages where the number of sentences is less than ‘length’.
Most of the summarization methods consider it as a binary classification problem, that is, whether a sentence/ phrase vector should be included in the summary or not, with the help of a Standard Naive Bayes classifier, an SNM or MLP. However, best results have been reported to be obtained by unsupervised graph-based methods as discussed below.
LexRank and TextRank, variations of Google’s PageRank algorithm, have often been cited about giving best results for extractive summarization and can be easily implemented in Python using the Gensim library. LexRank is an unsupervised approach to text summarization based on weighted-graph based centrality scoring of sentences, similar to TextRank. LexRank uses TF-IDF (Term Frequency-Inverse Document Frequency) modified cosine as the similarity measure between two sentences which is used as the weight of the graph-edge between two sentences. TextRank sometimes tends to give better results as it incorporates Named Entity Recognition, Part of Speech tagging and lemmatization instead of stemming.
Abstractive Summarization
Recent deep learning techniques have been observed to work well for abstractive summarization like the effective encoder-decoder architecture used for translation tasks, variational encoders, semantic segmentation, etc. to name a few. To generate an abstractive summary, a model’s encoding layer as well as the language model both need to be trained together.
- ‘Neural Attention’ by Facebook AI utilizes a local attention-based encoder-decoder model that generates each word of the summary conditioned on the input sentence;
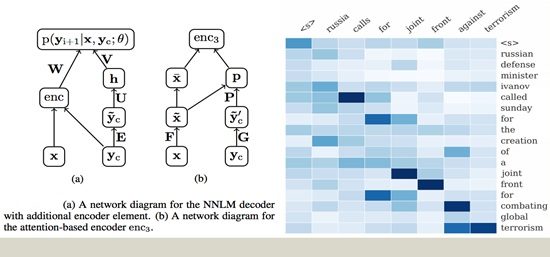
- ‘Textsum’ by Google is an open-source sequence-to-sequence model with attention architecture which can create headlines for news articles based on their first two sentences;
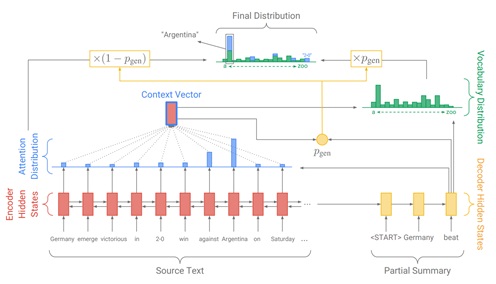
- ‘Pointer-generator’ by Google Brain, an encoder-decoder model with coverage popular for machine translation tasks can be directly used for summarization too
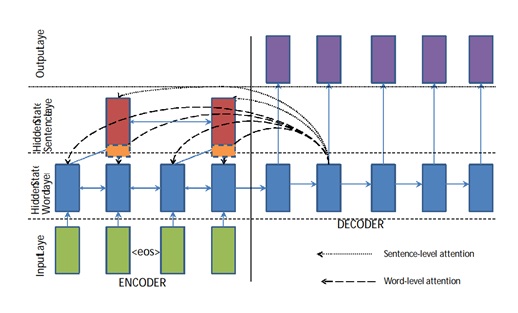
- ‘Sequence-sequence RNN and beyond’ by IBM uses an architecture similar to the previous one along with hierarchical attention, and a bidirectional network;
Datasets
Automatic text summarization tasks can be trained with the following publicly available free datasets:
- The Opinosis dataset which contains 51 articles formed with sentences extracted from user reviews on a given topic with each having 5 manually written ground-truth summaries.
- ‘DUC’ (Document Understanding Conferences) dataset which includes document-summary pairs, with each document having 2 extractive summaries.
- News article data set ‘CNN and DailyMail’ which contains 320k articles and vocabulary.
Apart from these, the English Gigaword dataset which contains around 10 million articles and an equal amount of well-organized vocabulary can also be used. But this dataset costs $3000 for a non-member.
How to evaluate a summary?
ROUGE-N is a widely used metric for evaluating a summary. ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation. It is the ratio of the count of N-gram phrases which occur in the model summary, to the count of all N-gram phrases that are present in the ground truth summary.
BLEU is another metric which stands for Bilingual Evaluation Understudy. It is a modified version of the precision of the word N-gram measure. It is the ratio of the count of N-gram phrases which occur in both the model and ground truth summary, to the count of all N-gram phrases that are present in the ground truth summary.
How Much Computation is Required?
TextSum takes around a week to get trained on the Gigaword dataset with 10 machines each with 4 GPUs according to Google, which is equivalent to around 7000 GPU hours. It is advised to train it for at least a million time-steps to get satisfactory results. This training time can also be reduced to a couple of days using the relatively small dataset mentioned above.
“Summarizing” for Now
Organizations are in immense need of tools for automating summarization process, given the amount of information we have available through the internet. For domain-specific tasks, extractive methods have worked fine. Due to the growing access to cloud platforms and multiple GPUs, there has been a shift of trend towards the abstractive techniques. Applications of newer techniques like GANs and Deep Reinforcement Learning for abstractive summarization have recently been published.


{kind=link}