

Introduction
Hadoop is well known for its batch processing capability and most of the time Hadoop is used for historical analysis, especially in airlines and weather forecasting sector. Although Hadoop is suited for working in a batch processing fashion, it is not limited to batch processing and sometimes it is also used for extracting a real time data for stream analysis. In this article, we will focus on some advance tools used within the Hadoop framework for extracting real time data from social websites like twitter and see if we can use the data to easily analyze the popularity of a person.
Running Apache Flume (an incorporated tool for real time analysis) on CDH3 (Cloudera distribution for Hadoop 3)
Implementing Apache Flume for a real time testing is a long and lengthy process and we will go step by step to implement it. The platform used will be apache Hadoop on Cloudera distribution for Hadoop version 3 and Ubuntu Linux 12. The system for the functionality is tested on a 32-bit based processor. We will straight away start implementing a real time system for a social networking site, known as Twitter.
Step 1: Downloading Apache Flume from the mirror link and check for its availability on Linux file system once it is downloaded.
Step 2: Create a directory of the following path /user/lib/flume-ng as depicted

Step 3: Copy the recently downloaded file i.e. apache-flume-1.4.0-bin.tar.gz to recently created directory i.e. /usr/lib/flume-ng
Step 4: After copying the directory to correct destination just unzip the .gz file to use its contents; we can do this using the following command –
sudo tar –xvf /usr/lib/flume-ng/apache-flume-1.4.0-bin.tar.gz
After extracting the file, check for its content by using ls command
Step 5: Copy the .jar file with the name flume-sources-1.0-SNAPSHOT.jar (contains an API for connecting with twitter) to the location /usr/lib/flume-ng/apache-flume-1.4.0-bin.tar.gz
Step 6: The most important step in terms of configuration of Hadoop is to configure some important files. The same goes for Apache Flume, it also needs some configuration editing in the flume.env.sh file.
Step7: here is how flume.env.sh will look like
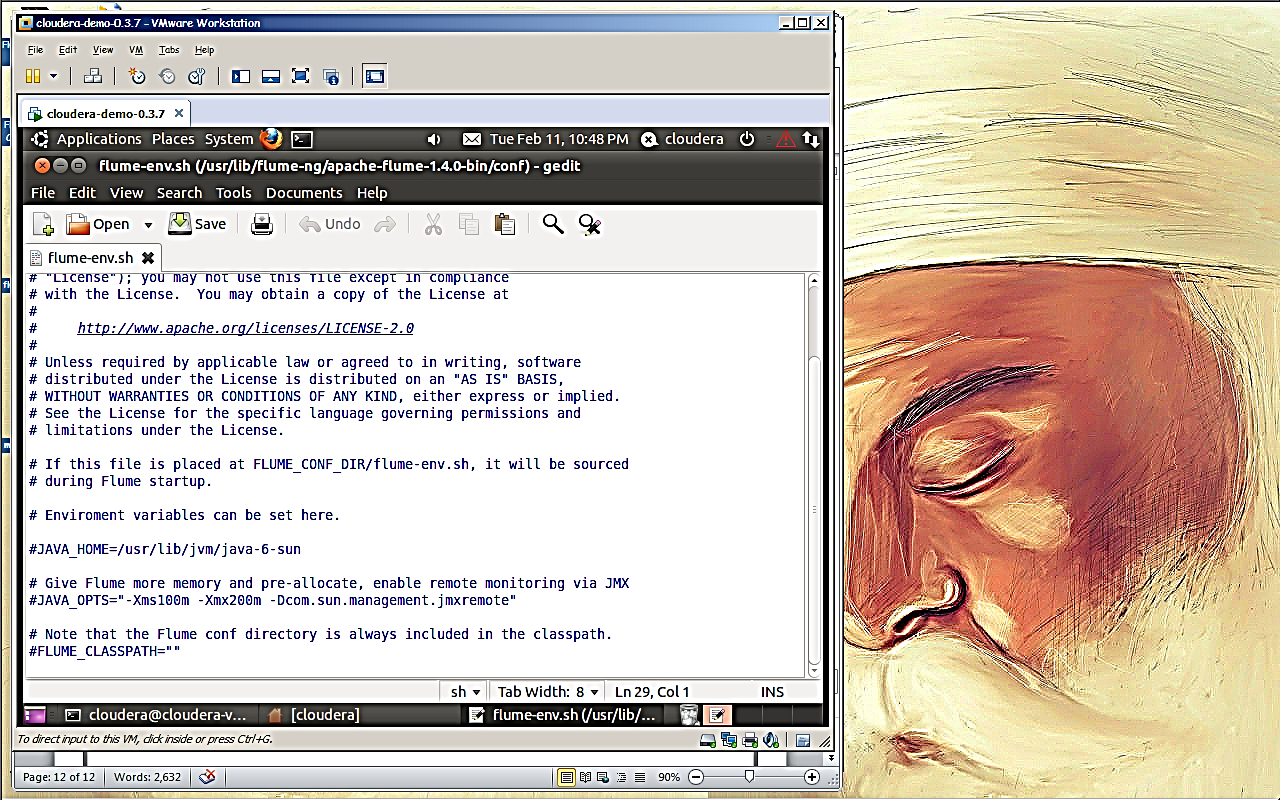
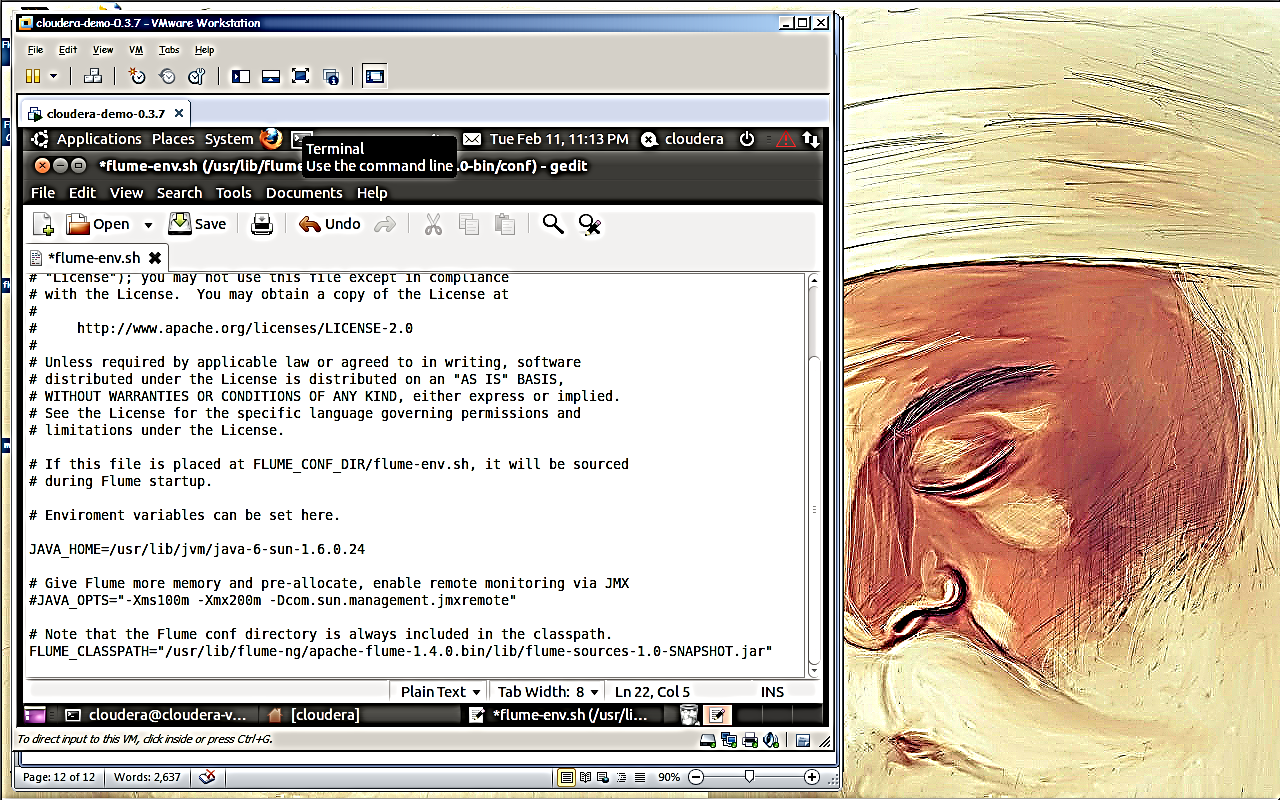
Step 8: We just need to do few changes in Flume’s configuration file
Setting Java home path i.e. JAVA_HOME variable
Setting Flume class path using variable FLUME_CLASSPATH
Step 9: Now it’s time to do some steps over Twitter.com, by creating an app we will try to connect our framework to the twitter app by signing up for a twitter account.
- Create twitter account
- Go to dev.twitter.com and log in with the credentials
- Now create a new app
Step 10: Create an app by giving it an app name, a short description, a website URL and a callback URL (optional)
Step 11: After creating the application, go to agreement and check the box – agree for accepting terms and conditions for signing up and creating an app.
Step 12: After signing up for the Twitter App and accepting the terms and conditions, the next step is to generate an access token that will be helpful in making connectivity with API. Just go to the application settings and click on generate access token.

Step 13: Now open and edit the flume.conf file. Append a few lines by adding:
TwitterAgent.sources.Twitter.consumerKey= “access key that will be given by Twitter”
TwitterAgent.sources.Twitter.consumerSecret= ”Id will be provided by Twitter”
TwitterAgent.sources.Twitter.accessToken= ”Id will be provided by Twitter”
TwitterAgent.sources.Twitter.accessTokenSecret= ”Id will be provided by Twitter”
For sinking data from Twitter, we have to write the same script as mentioned in this figure with the HDFS path as localhost and port 8020 in this case, but in a fully distributed cluster mode we have to write an IP address.
Make sure to set the JAVA_HOME properly TwitterAgent.sources.Twitter.keywords=””
This will sync the keywords from Twitter, whatever the keywords mentioned will be synced form Twitter to HDFS.
Now carefully change the directory to sync the data followed by the command, change the directory to bin else the command won’t work
Step 14: Run the command to start syncing
./flume-ng agent –n TwitterAgent –c conf –f /usr/lib/flume-ng/apache-flume-1.4.0-bin/conf/flume.conf
It might give an error that JAVA_HOME is not set!
But the program will run with warning
Once the connection is established, the data will start syncing and it will quickly start dumping the data in a Hadoop distributed file system and for that the data will be stored in chunks and analysis will be performed on that data using machine learning.
Step 15: Once the data is synced we need to check whether the data is actually dumped on HDFS or not and for this we need to go to web browser and type the URL, for example:
https://localhost:50070/dfshealth.jsp
After accessing this address (in this case it is a local host) go to browse file system and then access the directory where the data is actually stored i.e. / user/ flume /tweets
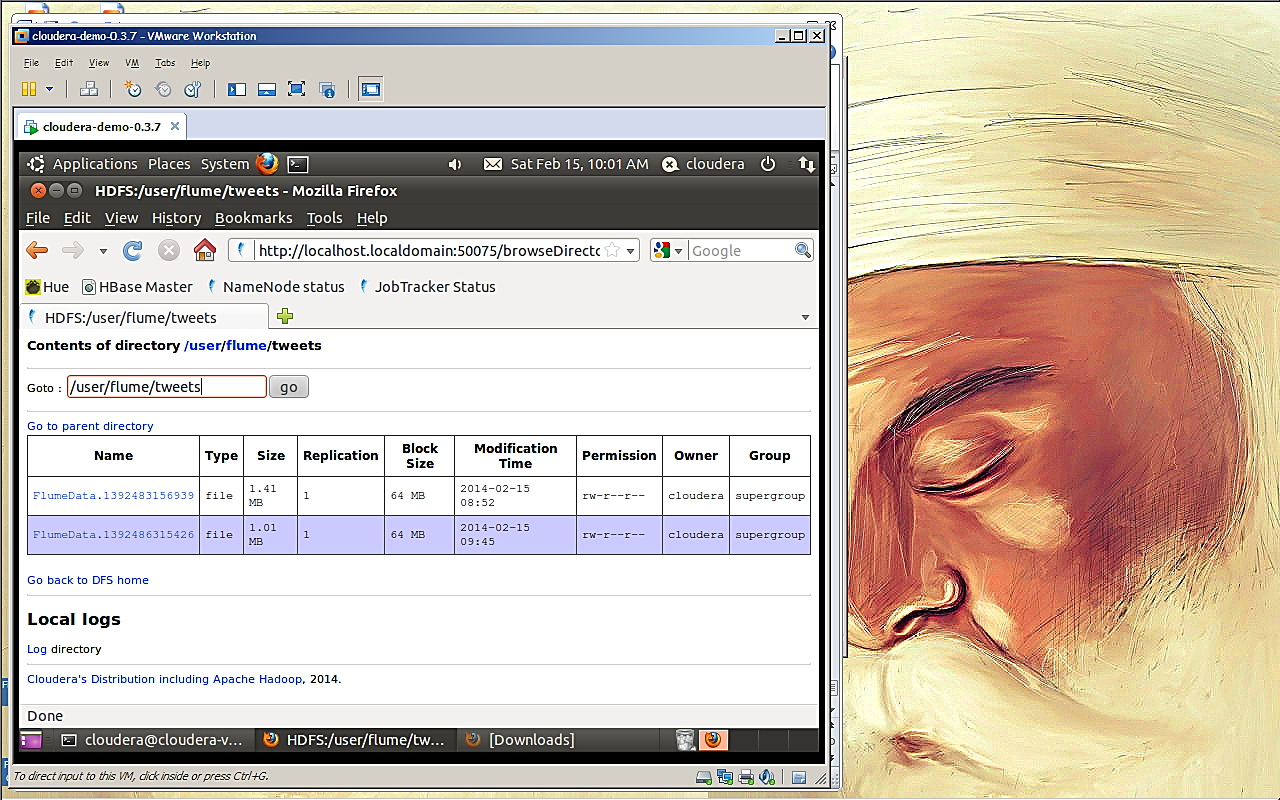
It will show you the file with their attributes and we can easily view the contents of these files
Click on flumeData.1392483156939
This is the synced data into the HDFS (on viewing this file we will see random Tweets by users and with this data the analysis can be performed)
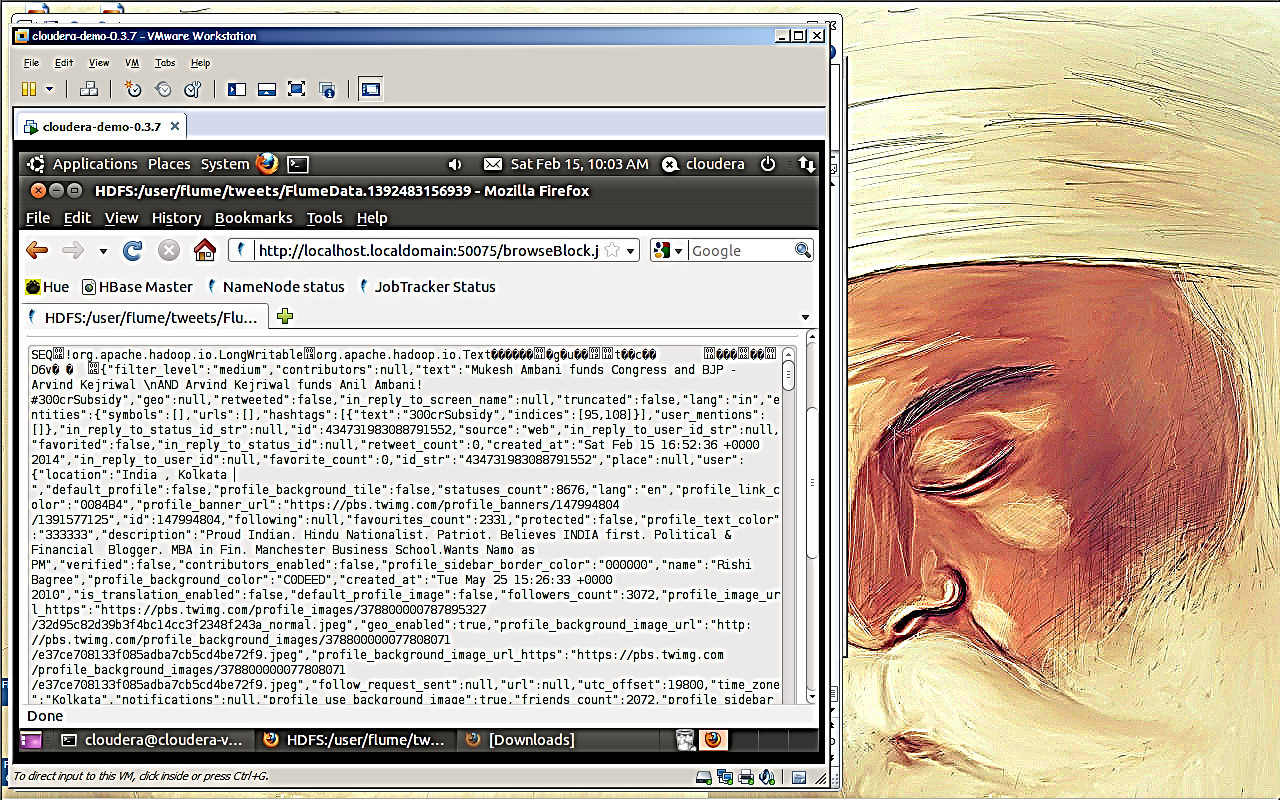
Though the data is pretty much random and unorganized, we have some other methods to clean up this data before analysis. Most of the time the data is organized using AWK and this is a basic but the best tool provided by Linux itself. Further if we need to analyze the data using hive, scoop or PIG Latin (usually for analysis and mining purpose), then additional tools are also provided by the systems to cleanse the data.
Conclusion
This article is a great sample for all those who want to test a real time application for analysis using Apache Hadoop. Hadoop Framework has incorporated numerous tools such as Apache Flume that can help in real time trend analysis for big data problem. Anyone who is dealing with big data can implement these technologies using the step by step method provided in this blog.


{kind=link}
Thanks for such a valuable informative post on Hadoop. By going through it most of my ongoing doubts regarding Hadoop have been cleared. Looking forward to more of such informative posts.
Hi nice to see your post here I had such a valuable information about Hadoop
Thanks for sharing such a grateful information with us on Data Science.
we are also providing best Data Science Training, so for more details please visit our website http://www.analyticspath.com/