
 NOAA’s National Climatic Data Center (NCDC) is responsible for preserving, monitoring, assessing, and providing public access to weather data.
NOAA’s National Climatic Data Center (NCDC) is responsible for preserving, monitoring, assessing, and providing public access to weather data.
NCDC provides access to daily data from the U.S. Climate Reference Network / U.S. Regional Climate Reference Network (USCRN/USRCRN) via anonymous ftp at:
Datasets : ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/products/daily01
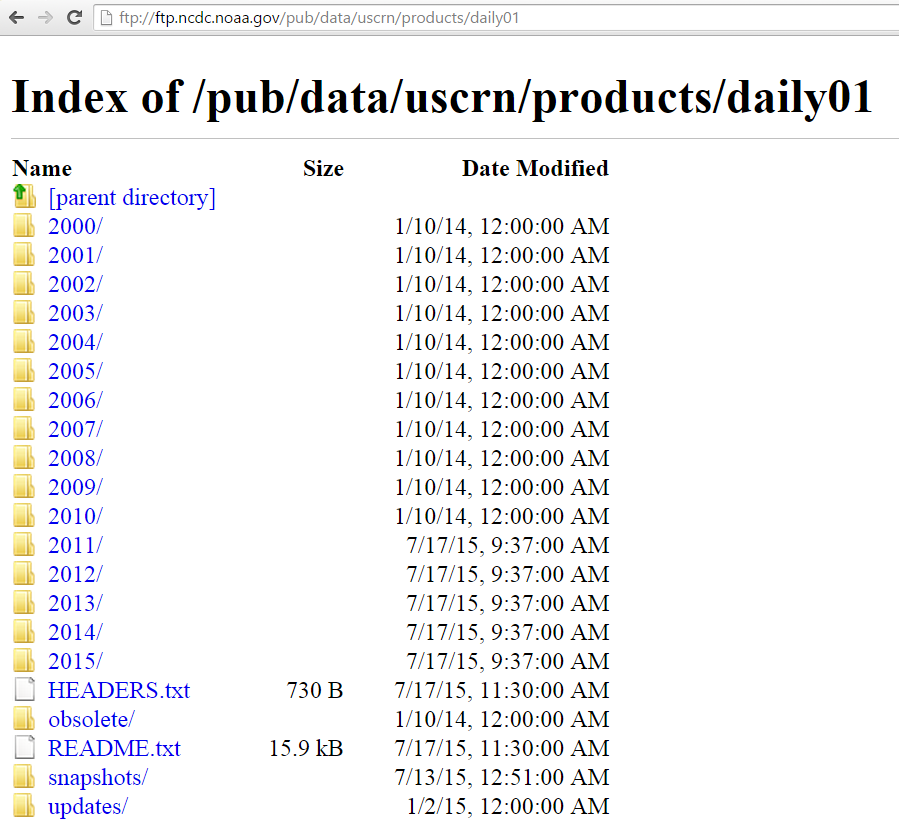
Readme : ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/products/daily01/README.txt
All daily data are calculated over the station’s 24-hour LST day.
Field# Name Units
———————————————
1 WBANNO XXXXX
2 LST_DATE YYYYMMDD
3 CRX_VN XXXXXX
4 LONGITUDE Decimal_degrees
5 LATITUDE Decimal_degrees
6 T_DAILY_MAX Celsius
7 T_DAILY_MIN Celsius
8 T_DAILY_MEAN Celsius
9 T_DAILY_AVG Celsius
10 P_DAILY_CALC mm
11 SOLARAD_DAILY MJ/m^2
12 SUR_TEMP_DAILY_TYPE X
13 SUR_TEMP_DAILY_MAX Celsius
14 SUR_TEMP_DAILY_MIN Celsius
15 SUR_TEMP_DAILY_AVG Celsius
16 RH_DAILY_MAX %
17 RH_DAILY_MIN %
18 RH_DAILY_AVG %
19 SOIL_MOISTURE_5_DAILY m^3/m^3
20 SOIL_MOISTURE_10_DAILY m^3/m^3
21 SOIL_MOISTURE_20_DAILY m^3/m^3
22 SOIL_MOISTURE_50_DAILY m^3/m^3
23 SOIL_MOISTURE_100_DAILY m^3/m^3
24 SOIL_TEMP_5_DAILY Celsius
25 SOIL_TEMP_10_DAILY Celsius
26 SOIL_TEMP_20_DAILY Celsius
27 SOIL_TEMP_50_DAILY Celsius
28 SOIL_TEMP_100_DAILY Celsius
After going through wordcount mapreduce guide, you now have the basic idea of how a mapreduce program works. So, let us see a complex mapreduce program on weather dataset. Here I am using one of the dataset of year 2015 of Austin, Texas . We will do analytics on the dataset and classify whether it was a hot day or a cold day depending on the temperature recorded by NCDC.
NCDC gives us all the weather data we need for this mapreduce project.
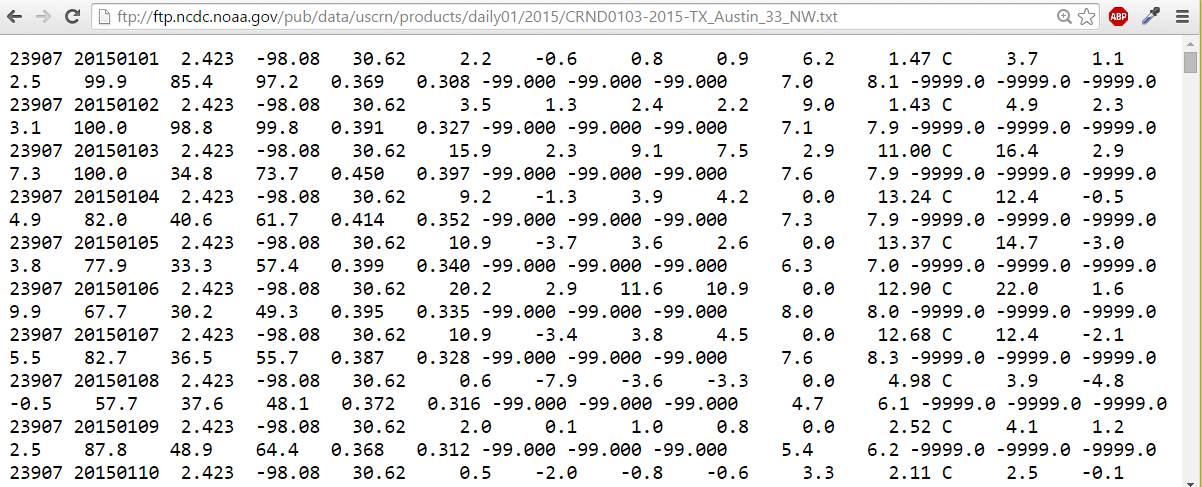
The dataset which we will be using looks like below snapshot.
ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/products/daily01/2015/CRND0103-2015-TX_Austin_33_NW.txt
Step 1
Download the complete project using below link.
https://drive.google.com/file/d/0B2SFMPvhXPQ5bUdoVFZsQjE2ZDA/view?usp=sharing
Below is the complete code
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
public class MyMaxMin {
//Mapper
/**
*MaxTemperatureMapper class is static and extends Mapper abstract class
having four hadoop generics type LongWritable, Text, Text, Text.
*/
public static class MaxTemperatureMapper extends
Mapper<LongWritable, Text, Text, Text> {
/**
* @method map
* This method takes the input as text data type.
* Now leaving the first five tokens,it takes 6th token is taken as temp_max and
* 7th token is taken as temp_min. Now temp_max > 35 and temp_min < 10 are passed to the reducer.
*/
@Override
public void map(LongWritable arg0, Text Value, Context context)
throws IOException, InterruptedException {
//Converting the record (single line) to String and storing it in a String variable line
String line = Value.toString();
//Checking if the line is not empty
if (!(line.length() == 0)) {
//date
String date = line.substring(6, 14);
//maximum temperature
float temp_Max = Float
.parseFloat(line.substring(39, 45).trim());
//minimum temperature
float temp_Min = Float
.parseFloat(line.substring(47, 53).trim());
//if maximum temperature is greater than 35 , its a hot day
if (temp_Max > 35.0) {
// Hot day
context.write(new Text("Hot Day " + date),
new Text(String.valueOf(temp_Max)));
}
//if minimum temperature is less than 10 , its a cold day
if (temp_Min < 10) {
// Cold day
context.write(new Text("Cold Day " + date),
new Text(String.valueOf(temp_Min)));
}
}
}
}
//Reducer
/**
*MaxTemperatureReducer class is static and extends Reducer abstract class
having four hadoop generics type Text, Text, Text, Text.
*/
public static class MaxTemperatureReducer extends
Reducer<Text, Text, Text, Text> {
/**
* @method reduce
* This method takes the input as key and list of values pair from mapper, it does aggregation
* based on keys and produces the final context.
*/
public void reduce(Text Key, Iterator<Text> Values, Context context)
throws IOException, InterruptedException {
//putting all the values in temperature variable of type String
String temperature = Values.next().toString();
context.write(Key, new Text(temperature));
}
}
/**
* @method main
* This method is used for setting all the configuration properties.
* It acts as a driver for map reduce code.
*/
public static void main(String[] args) throws Exception {
//reads the default configuration of cluster from the configuration xml files
Configuration conf = new Configuration();
//Initializing the job with the default configuration of the cluster
Job job = new Job(conf, "weather example");
//Assigning the driver class name
job.setJarByClass(MyMaxMin.class);
//Key type coming out of mapper
job.setMapOutputKeyClass(Text.class);
//value type coming out of mapper
job.setMapOutputValueClass(Text.class);
//Defining the mapper class name
job.setMapperClass(MaxTemperatureMapper.class);
//Defining the reducer class name
job.setReducerClass(MaxTemperatureReducer.class);
//Defining input Format class which is responsible to parse the dataset into a key value pair
job.setInputFormatClass(TextInputFormat.class);
//Defining output Format class which is responsible to parse the dataset into a key value pair
job.setOutputFormatClass(TextOutputFormat.class);
//setting the second argument as a path in a path variable
Path OutputPath = new Path(args[1]);
//Configuring the input path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
//Configuring the output path from the filesystem into the job
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//deleting the context path automatically from hdfs so that we don't have delete it explicitly
OutputPath.getFileSystem(conf).delete(OutputPath);
//exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Step 2
Import the project in eclipse IDE in the same way it was told in earlier guide and change the jar paths with the jar files present in the lib directory of this project.
Step 3
When the project is not having any error, we will export it as a jar file, same as we did in wordcount mapreduce guide. Right Click on the Project file and click on Export. Select jar file.
Give the path where you want to save the file.
Select the mail file by clicking on browse.

Click on Finish to export.
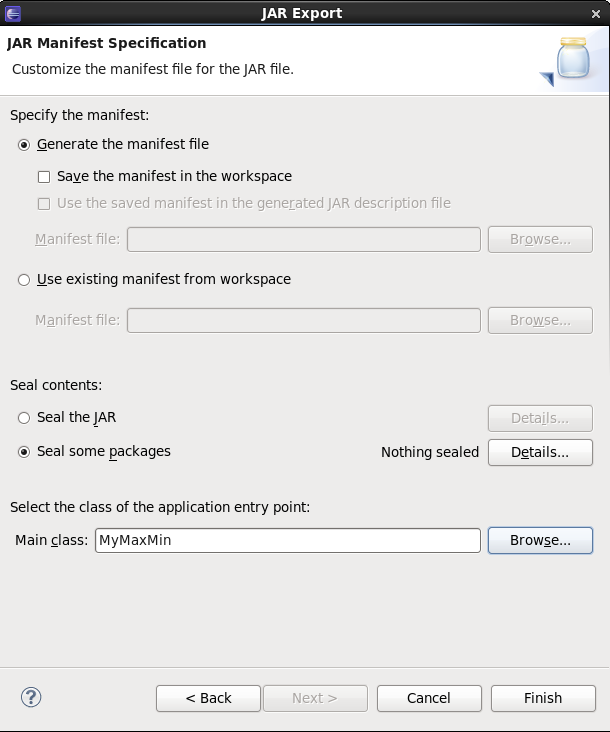
Step 4
You can download the jar file directly using below link
temperature.jar
https://drive.google.com/file/d/0B2SFMPvhXPQ5RUlZZDZSR3FYVDA/view?usp=sharing
Download Dataset used by me using below link
weather_data.txt
https://drive.google.com/file/d/0B2SFMPvhXPQ5aFVILXAxbFh6ejA/view?usp=sharing
Step 5
Before running the mapreduce program to check what it does, see that your cluster is up and all the hadoop daemons are running.
Command: jps
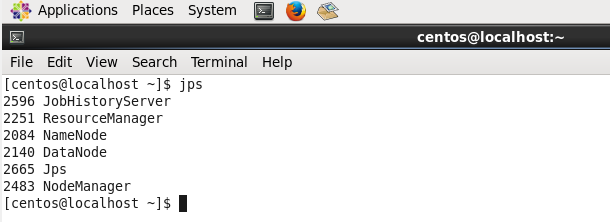
Step 6
Send the weather dataset on to HDFS.
Command: hdfs dfs -put Downloads/weather_data.txt /
Command: hdfs dfs -ls /
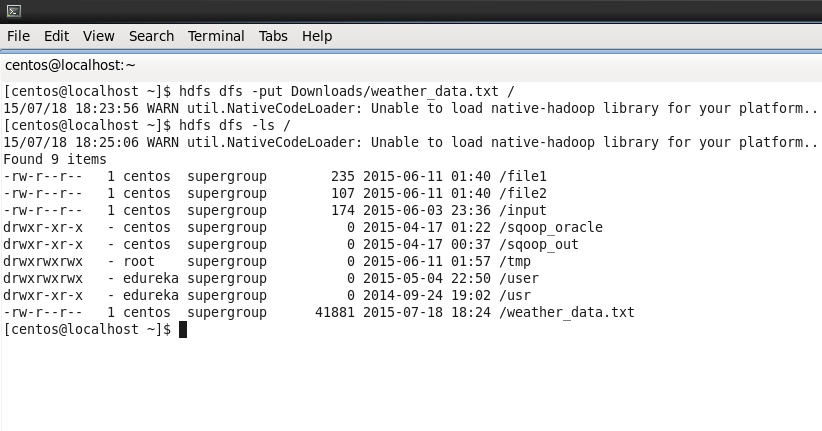
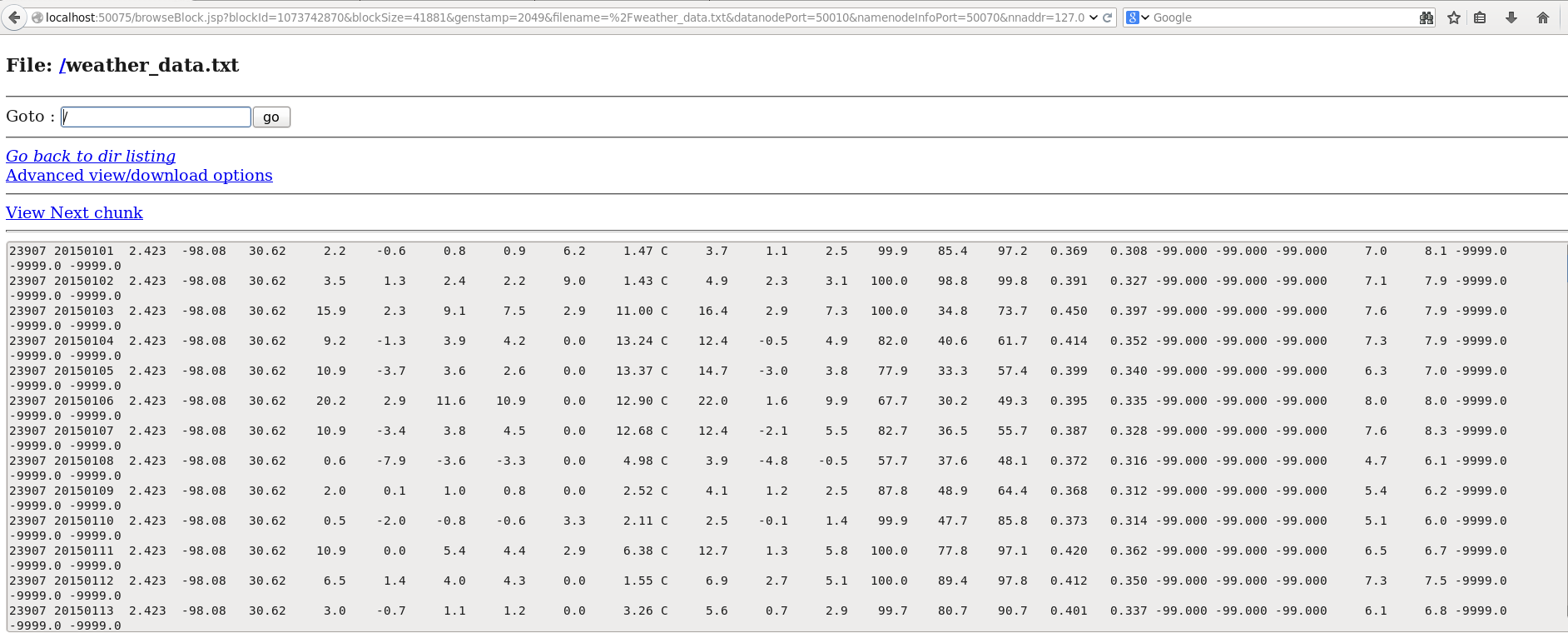
Step 7
Run the jar file.
Command: hadoop jar temperature.jar /weather_data.txt /output_hotandcold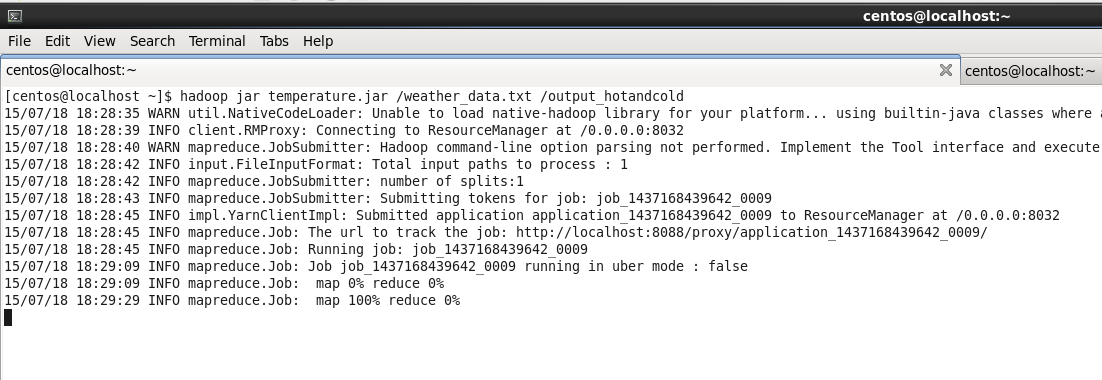
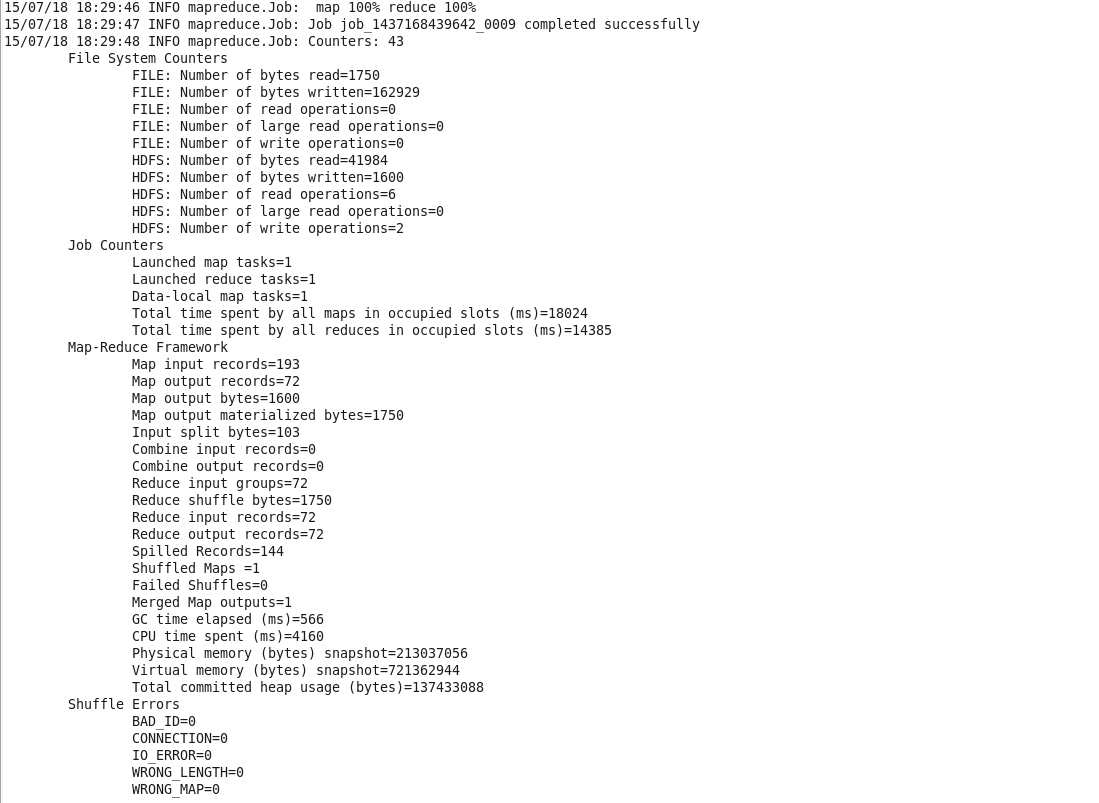

Step 8
Check output_hotandcold directory in HDFS.

Now inside part-r-00000 you will get your output.
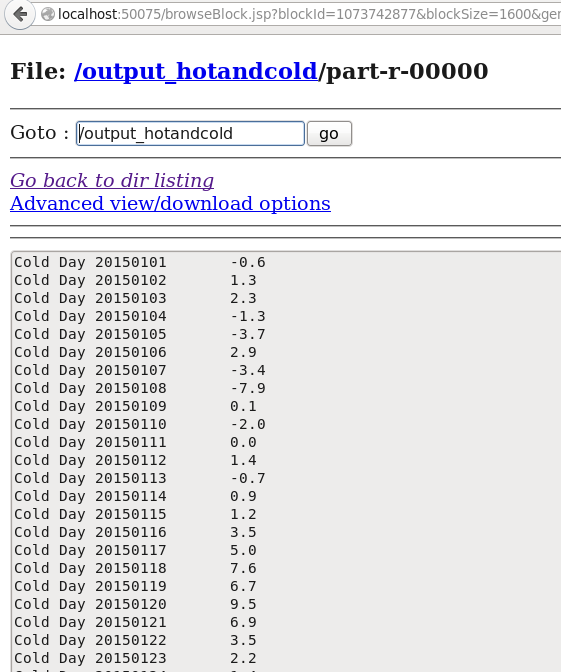
Depending my dataset , only two days crossed 35 in max temperature.

The Project has been successfully executed!!


 Dataset){kind=link}
thanks
Think this code will have a problem with negative, so the date 20150303 should be classified as a cold day as both the max and min temp are -9999. However post running the map phase, the -9999 becomes 9999 and hence is classified as a hot day. I am not sure if anyone else encountered this as well?
do we need to firstly create an hadoop cluster before running the mapreduce program. and how to create that sir please help me out
#add this line in the mapper class:
public static final int MISSING=9999;
#append to the if statements in the mapper class
if (temp_Max > 35.0 && temp_Max !=MISSING)
if (temp_Min < 10 && temp_Max !=MISSING)
Many thanks. 🙂
Need a synopsis of this project. Can anyone help me out with synopsis.?