

Hadoop Hadoop everywhere!
Companies like Microsoft, IBM and Oracle are building business solutions for unstructured data analysis similar to Apache Hadoop (used for complex data sets) in an attempt to solve business issues like predictive analysis.
Hadoop has changed the perspective of many industries in the automotive sector, healthcare sector and insurance sector. It has accelerated and forced industry giants to move for big data analysis and has also resulted in a substantial increment of big data projects and helping businesses to translate information into competitive advantage. There are many real time examples of how Hadoop has changed operations for many business organizations and those who have used Hadoop have frequently accelerated their business.
We frequently find various organizations using open source apache Hadoop (sometimes other products of Hadoop provided by many of the software giants). This enables them to have a thorough data knowledge and data discovery, where they will find a mono perception of customers across multiple and complex data sets. One of the real world examples includes a digital marketing powerhouse that uses Hadoop for their business improvement.
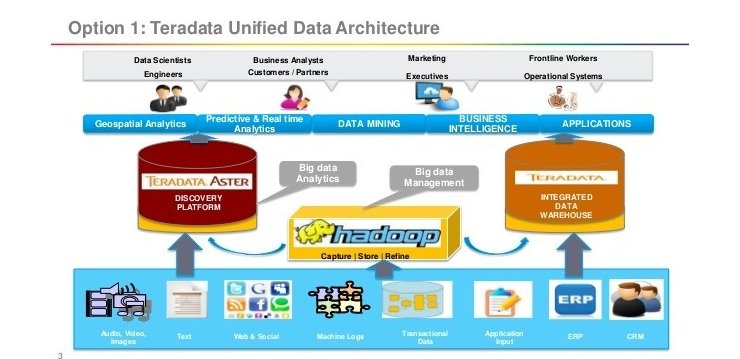
Hadoop meeting customer’s requirement
The biggest benefit of using Hadoop is its ability to cater to the constantly changing needs of various different customers and still manage to provide efficient results. The increasing demand of big data has intensified and motivated people to use this technology and has also made it possible for market leaders such as Cloudera and Hortonworks (who develop the Hadoop stacks pre-installed for different sets of works) to offer additional Hadoop related technologies .
One of the most prominent reasons of Hadoop being popular amongst the customers and developers is its ability to incorporate many new tools and techniques that emblazes this framework for advance techniques and analysis. One of the most remarkable open source project produced by Apache Foundation is Apache Spark that is 100 times faster than a normal map reduce job (traditional technique used for data analytics) and it incorporates advanced directed acyclic graph for its execution engine and supports cyclic data flow (calculating dependencies) and in memory cluster computing (just like SAP HANA).
Apache Spark (a step ahead from map reduce) is developer friendly and comes with a prominent support for languages like Java, Python and C++. It is written in Scala (a language similar to Java) and supports many machine learning libraries used for business intelligence.
Apache Hadoop yarn: A step ahead for business improvement
Hadoop Yarn is an efficient approach for many data scientists. It is known for its resource management and also as another resource negotiator incorporated into Hadoop as a sub project, declared as Hadoop 2.0. Apache Yarn has boosted the capabilities of Hadoop, using its resource scheduler for enhancing data processing capabilities and better visualization of data.
Challenges faced during data analysis
Most of the big data strategies are still slowing down, as many IT organizations are struggling to cope with challenges faced during data analysis phase. These include velocity of data, variety of data, complexity of data to understand it, data collection, data storage and data management. Most organizations are spending hours on making strategies for identifying technical issues to promote the use of big data for various sectors (prominently health care and insurance, while many companies in the banking sector are using Hadoop for risk profiling).

How Hadoop is successful for data analytics
Hadoop has been designed for data processing and data management, while making it suitable for data management, Hadoop uses tools like H catalog, which is mainly a table for managing and maintaining a record of services. It provides a centralized mechanism for processing unstructured data and complex data sets. It also understands the structure of the system with the data locality optimization principle, for processing the execution tasks within Apache Hadoop framework.
Hadoop helping business to leverage with a greater extent
Many solution providers pull and generate huge amounts of data, aka data sets, which are the combination of structured and unstructured data. Subsequently, organizations are processing information in to a more manageable and a platform for storing the data securely into Hadoop distributed file system. Another step in this approach is to maximize the business value of the data stored in Hadoop storage (usually hdfs). Traditional approaches like data warehousing (used with data mining) and BI solutions often take months to conclude a point. However, it is not possible for a process to take so long for a business decision. Often, it is possible to analyze data in Apache Hadoop without much complexity (due to its stack based approaches and various tools). Hadoop is very powerful tool and reduces the complexity of integrating the multiple Hadoop components to communicate with each other, whereas existing data structure is still a challenge. Organizations are blending small data sets with large data sets for their extensive use of data analytics tool, but besides this Hadoop is still a challenging task when analyzing a small data set. Experts are working to make Hadoop a successful tool for the best performing analysis tool for unstructured and raw data as well.
Conclusion
In this article we have thoroughly described trends and opportunities of Hadoop. We have kept in mind all the possible uses of Hadoop for business intelligence and performance enhancement of big data analysis especially in regards to unstructured data. There are many future possibilities for Hadoop and it is incorporating many supportive technologies for gaining an insight into data.


{kind=link}