

Introduction to HDFS
Hadoop Distributed file system is a distributed storage system used for storing large scale data sets and real time streaming data, setting up a streaming parameter at high bandwidth. HDFS provides high performance, high reliability and high availability. It does this by using replication mechanism, by default it stores three copies of single data file it simply means that a file, named abc.txt will be stored at three different locations and with the help of this feature of HDFS, the hadoop framework becomes highly reliable, highly available and highly fault tolerant.
HDFS uses a uniform triplication policy that improves the data locality ensuring data availability. Though we can change some .xml configuration files inside hadoop to change the by default replication factor. Suppose if we need replication factor from 3 to 4, then we can easily proceed with that, and this is the reason that critical data should be assigned larger replication factor so that it can be stored in multiple locations and thus making critical data fault tolerant and highly available. But this is a generic approach of increasing the replication factor, we need to increase it dynamically because in such a large cluster it won’t be possible every time to look for configuration files and then change the replication number.
System Architecture overview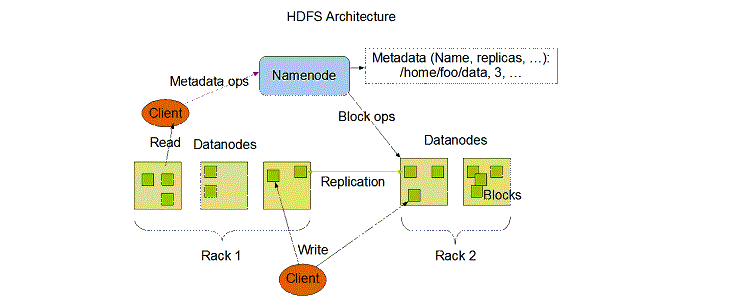
The Name Node and Data Nodes are the backbone of Hadoop Distributed File System; they are pieces of software that coordinate with each other to run on commodity hardware (probably a non-high end machine). Name Node keeps the track of the each data block that is stored in Data Node (actual data is stored in Data Node). Name Node also keeps the track of each replication file and Stores this information, often recognized as Meta Data or Meta File.
Increasing the replication factor dynamically
In this section we will discuss of how we can implement a methodology of dynamically increasing the replication factor, without changing the existing xml file. This article introduces a data judge methodology that explains the functionality, making HDFS cluster resource aware and replication aware.
System Architecture Details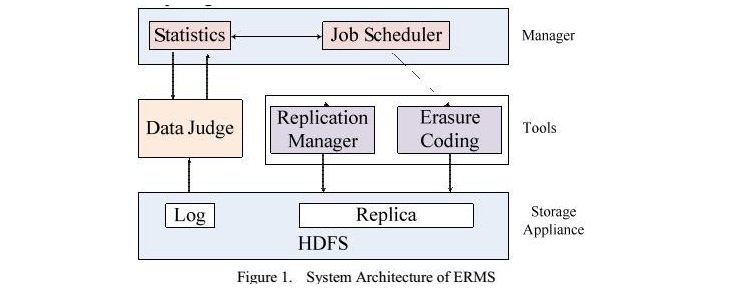
Here the replication manager is responsible for managing the replicas and making the placement strategies, in this complete architecture HDFS is just a basic storage appliance where the blocks or chunks of data is dumped. The data judge model is used for extracting metrics from HDFS cluster and uses a daemon to distinguish existing data type in a real time system.
“Data Judge” Model
Today’s world is a world of data. We know that replication factor is a critical issue in terms of Hadoop Distributed File System. We are not facing any challenges for storage space but keeping the data secure and replicating it so as to make full use out of it.
This data judge scheme introduces a log parser, that regularly audit (investigate) the HDFS logs and instantly translates them into events and this is a fairly distributed scheme, on creating these events we are going to judge, how critical the data is and how we can increase the replication factor of it dynamically. This concept is usually known as Elastic Replication Management System.
The data after passing the data judge model is organized according to the priority and the critical data (that is accessed often or of high priority). Critical data is one that has high amount of access records and high intensity access records. This concept distinguishes the data by hot data and cold data, the data judge model also recognized a data as cold data i.e. the data that is rarely accessed and thus given low priority.

Implementing replica replacement and dynamic allocation policy
This is a critical task, as making the replication factor increasing on the move is a tuff task to perform, and also to maintain the reliability and efficiency factor of HDFS consistent.
Step 1: Elastic Replication Management System incorporates an Active/Stand by Storage system. It makes a list of Active Data Nodes (Using data Judge Algorithm) that will distinguish among hot and cold data.
Step 2: Making a list of Stand By data i.e. the data that is not used recently or is of least importance.
Step3: Calculate the current replication factor and default replication factor.
Step 4: Developing a strategy for calculating the number of data nodes that contains least data blocks that and choosing the data block that has least priority and replacing the data block with high priority data node.
Step 5: The last and final step is the data clearance or moving the lowest priority data blocks to normal data nodes. This is also known as erasure code parities.
Here in this scheme when choosing the data block the Elastic Replication Management System always prefers a stand by node that is placed in same racks so that other replica’s may be given high priorities.
The most important rule for this is to remove the lowest priority data and for this we use Elastic Replication Management System. While replica replacement strategy doesn’t require rebalancing the whole cluster and avoiding rebalancing, increasing or decreasing the replicated blocks that are assigned priorities, so for this reason the ERMS is well suited and preferred.
Conclusion
Replication factor is always an issue in HDFS and it could obviously affect the system’s performance. This test can also perform on any dummy data set either by default data set or any other data set of your choice. The TEST_DFS_IO is the by default benchmark for evaluating the performance of Hadoop Distributed File System that mainly uses the Map-Reduce to Read and Write the files in parallel while keeping the Elastic Replication Management System in mind, TEST_DFS_IO is well suited to analyse the performance of HDFS while using different replication factors. ERMS also has a functionality of increasing the replication factor either in an optimal manner or using one by one strategy. In this way we can achieve the variations in replication factors for prioritized data.


{kind=link}
Hey, can you provide some link to the codes for the implementation of the same ?