

The Internet of Things (IoT) is the new reality that is going to penetrate our lives. According to Gartner, the number of interconnected devices will increase to 6.4 billion in 2016, up by 30% from 2015, thus generating enormous volumes of data every day. In fact, nearly 2.5 quintillion bytes of data is produced every day. Enterprises need to be equipped to handle such huge volumes of data. To process such data volumes, enterprises need to be able to store and process the data every day, without allowing unforeseen events such as system crashes interrupt the flow. Hadoop is capable of storing and processing huge volumes of data efficiently, without failure. There are a number of use cases to demonstrate that Hadoop is the best-equipped tool to handle the data generated from interconnected devices. Surveys across industries show that enterprises are already relying on Hadoop to obtain better analytics, improve analytical capabilities and augment data warehouses.
What is Hadoop?
Hadoop is a free Java-based programming framework that supports the storage and processing of large datasets in a distributed computing environment (DCE). The emergence of big data has put serious challenges before the traditional computing systems. Big data has become one of the most valued assets enterprises have. To gain valuable business insights and make good decisions, companies have to regularly manage growing volumes of structured, semi-structured and unstructured data. Traditional computing systems are not designed to handle such large datasets. This is where Hadoop comes in.
Let us think of Hadoop as a programming framework that can accommodate a large number of servers and other related resources with each server offering local storage and computation capabilities. All servers and resources are interconnected in a network. The Hadoop framework allows you to scale up the number of servers and related resources based on requirements. Now, assume that you need to process at least 1000 terabytes of data every day and offer analytics to a group of marketing personnel who view the analytics on multiple client computers. How does Hadoop handle such an enormous task day in day out with such efficiency?
Hadoop divides the entire task across the servers and resources which are also known as clusters. The servers and other resources in a cluster are also known as nodes. Each cluster now processes the data and returns the results to a master computer. Note that each cluster is capable of developing and running a software application in it. The master computer collects the end results from the clusters, converts them into readable format and offers as analytics to business users.
The Hadoop architecture comprises four modules each of which plays a specific role in the processing of big data. The names of the modules are MapReduce, HDFS, YARN and Common Utilities.
Impact and applications of Hadoop in the Industry
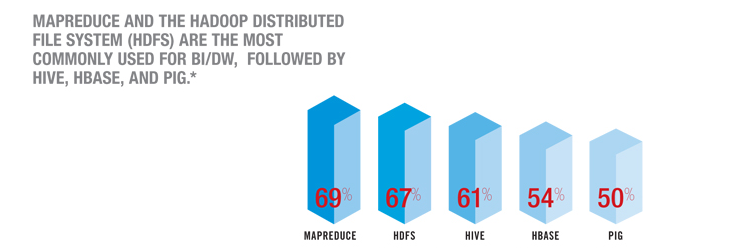
The image below shows that MapReduce and the Hadoop Distributed File System (HDFS) are the most commonly used Business Intelligence and Data Warehousing tools.
The corresponding image below shows that big data sourcing and advanced analytics are two of the areas that benefit most from Hadoop. This is expected because the flexible storage, computation power and Java-based platform enable Hadoop to store and process high volume of data and integrate with any platform to deliver analytics.

The image below represents a few areas that could be impacted by Hadoop. Hadoop’s influence could span across industries which would be able to cut costs, improve efficiency, utilize data efficiently and influence people’s lives positively, among many other things.

What is IoT?
The IoT is a concept according to which all devices — traffic lights, watches, fridges, televisions, air conditioners or anything that you can think of — will be connected to the Internet via an IP address and can exchange data with other devices.
How does IoT work? There are millions of use cases to show how it works, but let us tackle the parking space problem. You are taking your family out for dinner on Sunday night and you know that the available parking spaces close to the restaurant are possibly going to be under immense pressure. You want to locate the closest available parking space and book it without needing to run around looking for a parking space. Now, your car has a device fitted with a sensor. The device uses the GPS to interact with sensors at all parking spaces close to the restaurant you are going to. Your car receives the data about the vacant parking spaces available close to the restaurant and you book the most convenient one online. That is how convenient IoT can get.

The pairing of Hadoop and IoT
The IoT indeed appears to be full of promises, but it is important to know the way to leverage its full potential. While the number of interconnected devices increases, the volume of data is going to take monumental proportions. It has already been pointed out that traditional computing systems cannot store or process such volumes of data. Experts believe that enterprises can reap full benefits from the IoT phenomenon by pairing Hadoop with IoT. The main reasons Hadoop is best suited to work with IoT are given below:
- Hadoop is capable of storing and processing any volumes of data. It can scale up based on rising data volumes.
- No risk of performance issues or work stoppage because of unforeseen events as the work is divided across clusters. Even if a node crashes or experiences issues, it does not become a showstopper. From the perspective of business continuity, nothing can be more desirable.
- Hadoop, being an open source Java-based framework, is compatible with all platforms.
- No dependency on hardware to provide fault-tolerance and high availability (FTHA). Hadoop has a library in the Common Utilities module that can detect and prevent application layer failures.
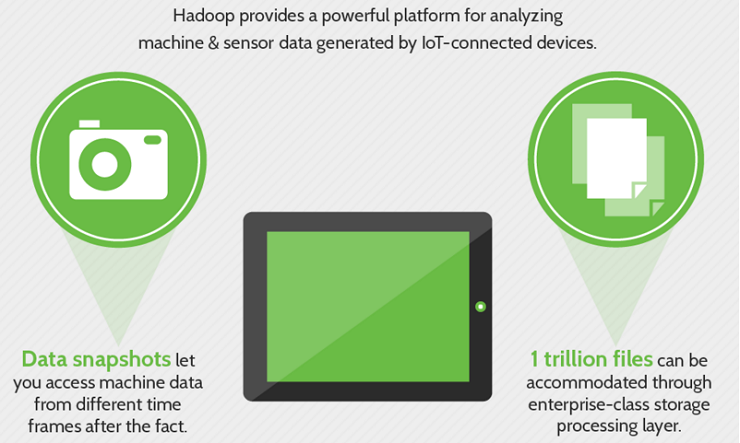
The image below gives reasons why Hadoop is considered as the best fit with IoT.
Summary
Right now, there is no better alternative than the Hadoop-IoT pairing in sight for the efficient storage and processing of big data. However, it needs to be noted that both, IoT and Hadoop, are in their early stages of adoption by the industry. There is some hype around both concepts. As the dust settles down, the enterprises will learn more about Hadoop-IoT pairing and ways to better process the data.


{kind=link}