

Hadoop was designed to be a distributed system that scales up to thousands of nodes. Even with a few hundred node cluster managing all those servers is not easy. Problems that can kill your application such as deadlocks, inconsistency and race conditions arise. Zookeeper was developed to solve challenges that arise when administering a large number of servers. To solve these challenges it provides a centralized way to manage objects required for a properly working cluster. Some of the objects that can be managed are naming space, configuration information, distributed synchronization and group services.
Zookeeper has several benefits that making it an excellent way to manage a cluster. First Zookeeper is replicated across many hosts with each host being aware of the others. With a large number of hosts running Zookeeper availability of its service is always guaranteed because there is no single point of failure. Secondly Zookeeper is fast especially in workloads that have more reads than writes. Thirdly Zookeeper is simple to use because it utilizes a standard hierarchical namespace like the one used on operating system files and directories. Finally client requests to make writes are processed in the order sent by clients. This way of guaranteeing order enables the system to resolve deadlocks, queues and other features required in a distributed computing environment.
Zookeeper is configured to run on a cluster that is called an ensemble. This can be the same cluster running Hadoop or you can create a dedicated cluster. To ensure consistency in data stored by Zookeeper a change is only successful if it has been made on at half of the ensemble. This half of the cluster is referred to as a quorum. In the event of two conflicting changes at the same time there is a leader in the ensemble that ensures only the first change it makes is successful and the other is unsuccessful.
To guarantee availability of the Zookeeper it is advisable to run it on a an odd number of servers. Possible choices are three, five or seven servers. When an individual server fails service availability is guaranteed as long as at least half of the nodes in the cluster are running. When a failed node becomes available again it is synchronized with the other nodes in the cluster.
Setting up Zookeeper on a single server is very easy. Download it from here http://zookeeper.apache.org/releases.html. Navigate to the directory where it was downloaded and unpack it.
cd ~/Downloads sudo tar xzvf zookeeper-3.4.8.tar.gz
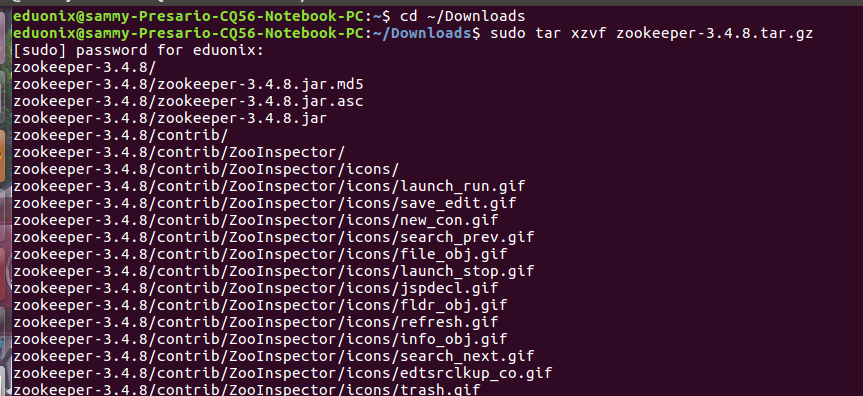
Move extracted files to an installation directory and assign its ownership to an appropriate user.
sudo mkdir /usr/local/zookeeper_single sudo mv zookeeper-3.4.8 /usr/local/zookeeper_single sudo chown -R eduonix /usr/local/zookeeper_single

To configure Zookeeper we edit to edit three configuration properties in zoo.cfg configuration file. These are the ports used to listen to client requests, the directory used to store data and amount of time for performing heart beats. Create a directory that will be used to store data using the command below.
sudo mkdir /usr/local/zoo_data sudo chown -R eduonix /usr/local/zoo_data

A zoo_sample.cfg file is provided under /conf/ directory so rename it to zoo.cfg then add the configuration properties highlighted in green.
sudo cp /usr/local/zookeeper_single/zookeeper-3.4.8/conf/zoo_sample.cfg /usr/local/zookeeper_single/zookeeper-3.4.8/conf/zoo.cfg sudo gedit /usr/local/zookeeper_single/zookeeper-3.4.8/conf/zoo.cfg
tickTime=2000 dataDir=/usr/local/zoo_data clientPort=2181
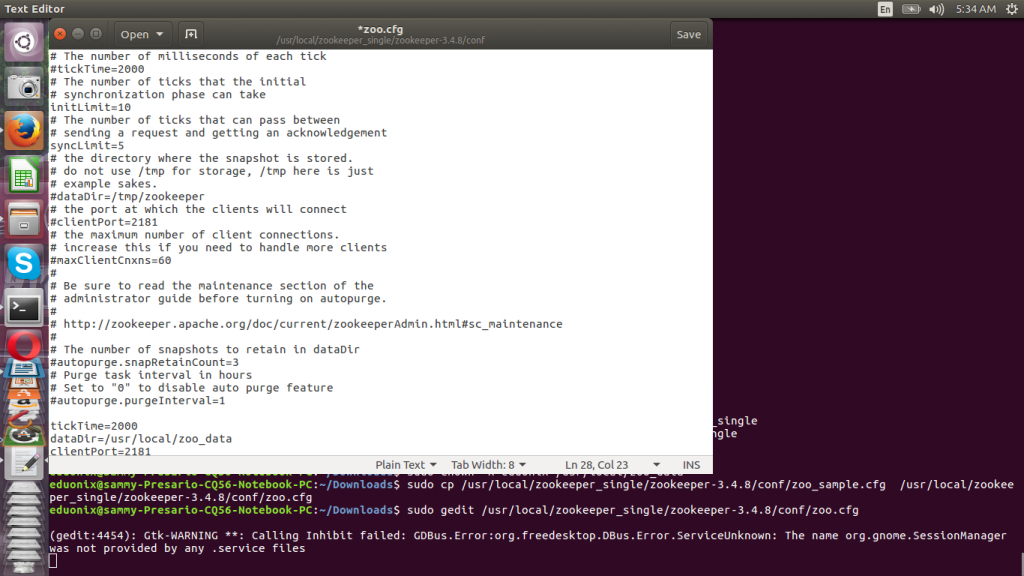
Save the configuration file and start Zookeeper using zkServer.sh script found under bin directory.
/usr/local/zookeeper_single/zookeeper-3.4.8/bin/zkServer.sh start

In a production environment it is recommended to run a cluster with an odd number of nodes. You install using the procedure discussed previously on each node but the configuration file is different. An example of a file that can be used in a cluster is highlighted below in green. The file has to specified for each server participating in Zookeeper service.
tickTime=2000 dataDir=/usr/local/zoo_data clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
The dataDir is the directory used by Zookeeper to store data. The initLimit property is used to specify the maximum amount of time Zookeeper servers have to connect to the leader. When you are processing large amounts of data just increase this value as required. The property syncLimit is used to fix allowable amount of time a server can be out of sync with leader. The properties server.1, server.2 and server.3 specify the servers that form the Zookeeper service. Then you specify the host name of each of the servers followed by the port numbers 2888 and 3888. These ports are used for peer to peer communication. Specifying a port this way enables a connection between a leader and a follower. There are many properties available to control the behavior of Zookeeper so refer to administration guide available online for an exhaustive discussion.
To make each server aware of the other servers in the ensemble you use a myid file that is placed in the data directory of each server. This file contains only a unique value between 1 and 255 which corresponds to the value specified in zoo.cfg file. For example for server.1 the myid file only contains the value 1.
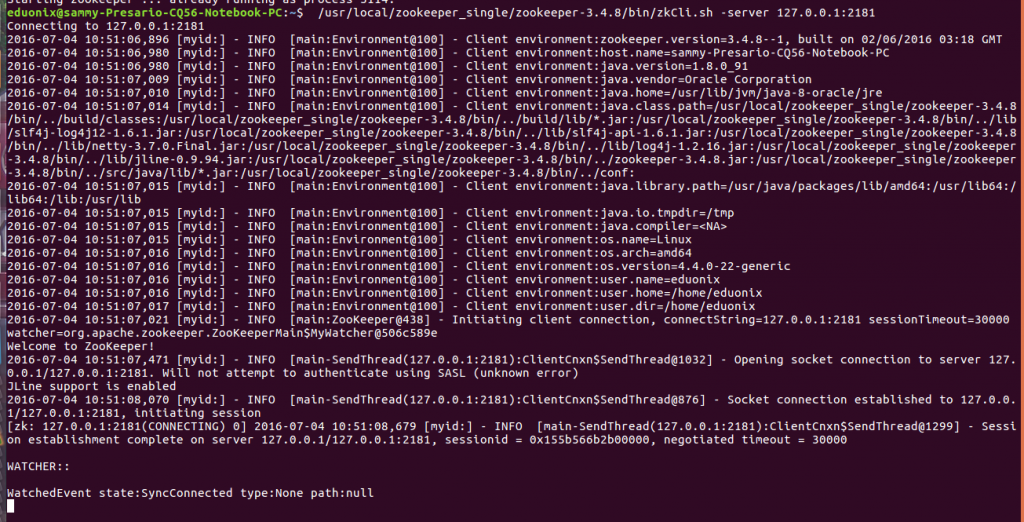
A CLI is available to connect to the server and issue commands. To start it use the command below
/usr/local/zookeeper_single/zookeeper-3.4.8/bin/zkCli.sh -server 127.0.0.1:2181
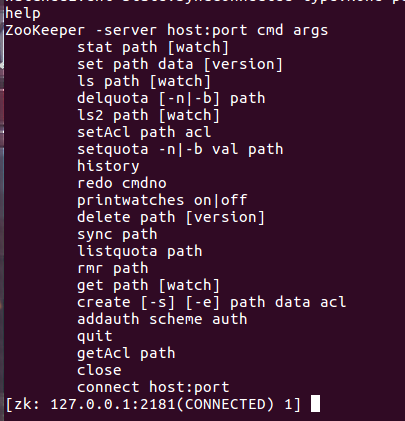
A list of available commands that can be executed are displayed by typing help
This tutorial introduced you to the need to use a mature solution for managing distributed applications. Challenges that arise in distributed applications were identified and it was explained how Zookeeper solves these challenges. Installing Zookeeper on a single machine and on a cluster was discussed. Some of the important parameters that control the behavior of Zookeeper were discussed. Finally using CLI to connect to Zookeeper server and issue commands was discussed. In this first part tutorial it was demonstrated how to set up Zookeeper in standalone and cluster mode. In part two of this tutorial we will demonstrate how to use it to maintain cluster data.


{kind=link}