

To develop a data model in Hbase that is scalable you need a good understanding of the strengths and weaknesses of the database. The guiding principle is the patterns in which the data will be accessed. Simply put the queries that will be issued against the data guide schema design. Using this approach it is advisable to use a schema that stores data that is read together within proximity. This tutorial builds on managing data using NoSQL Hbase database. Please refer to it for review of basic concepts and how to install Hbase on Hadoop.
In relational schema data is normalized to avoid duplication but this leads to the need for joins when accessing data which may lead to slow queries. With a denormalized schema there is no need for joins when accessing data which speeds up data access. In Hbase denormalized data models that duplicate data are preferred. Tables that store data in a one/many to many relationship can be collapsed and the data stored in one table.
This tutorial will take a practical approach by showing how to remodel the sakila database into an Hbase schema. To import data into hive we will use sqoop so refer to imprting data with sqoop tutorial for a basic review of sqoop and how to install it.
Moving your data from a relational to a hbase model successfully depends on correctly implementing three concepts of denormalization, duplication and use of intelligent keys. The row key in a Hbase model is the only way of sorting and indexing data natively. This key is also used to split data into regions in a similar way partitions are created in relational table. Therefore this key needs to be designed in a way that it will enable data access as planned.
The sakila model is available at this link http://downloads.mysql.com/docs/sakila-en.pdf. We review film data and come up with a way of modeling it in Hbase.
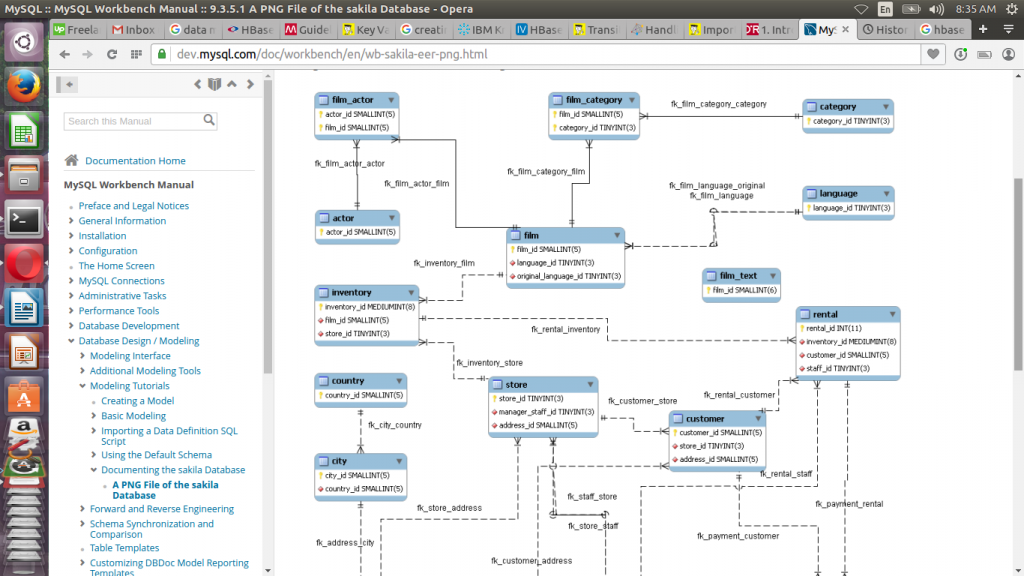
We would like to track film data in our database. This data is composed of film category, language and film actor. We would like to access the data as shown below:
- Which languages does an actor use
- What categories of movies does each actor have
We denormalize all tables containing film information into one table. One way of doing this is to use film_id in film table as a primary key and collapse film_category, film_actor and language into one table. In Hbase terminology the film_id becomes the row key. This key will be used to sort data, index and split the data into regions. The columns in each of the tables being denormalized are then used as columns and the tables become column families.
Data compression happens at column family level therefore schema design needs to be done with this in mind. It is good to keep column family name and qualifier short because for every row of data they are repeated. This reduces data stored and read by Hbase. The number of column families should be kept to the bare minimum to keep the number of Hfiles to a minimum level. Using fewest column families reduces disk space consumed and improves load time.
Our resulting data model will appear as shown below
| film_id | first_name | last_name | name | title | description | release_year | film_category |
Sqoop does not have features for directly importing a table into Hbase. To overcome this limitation a Hbase table is created before running Sqoop data imports.
Before issuing any Hbase commands start it by running hbase-start.sh at terminal.
Invoke Hbase shell by running hbase shell at a terminal. This will avail a shell that can be used to interact with Hbase. Use help command to find out how to use commands.
To create a table you use the create command using the construct shown below.
create ‘filmInfo’, ‘filmCategory’, ‘film’, ‘filmText’
The first argument is the table name followed by names of column families.
Once Hbase table has been created we use Sqoop to import data from respective Mysql tables. In the Sqoop import syntax you specify the Mysql table and columns to be imported and you also specify the Hbase target table and column families. When importing the data you also specify the Mysql column that will become the row key in Hbase using –hbase-row-key flag. The data import commands in the section below will be run by Sqoop to import data into Hbase. When running commands dont include sqoop as it is just an indicator to show commands will be run by
To import data from film_category table the commands shown below are used. From this table we would like to import category_id column into filmInfo column family with film_id as the row key.
sqoop import \ --connect jdbc:mysql://localhost/sakila \ --username root -P \ --table film_category \ --columns "category_id" \ --hbase-table filmInfo \ --column-family filmCategory \ --hbase-row-key film_id m -1
From film table we would like to import title, description, release_year, length, rental_rate and rental duration columns into filmInfo column family with film_id as the row key in Hbase.
sqoop import \ --connect jdbc:mysql://localhost/sakila \ --username root -P \ --table film_category \ --columns " title, description, release_year, length, rental_rate, rental_duration" \ --hbase-table filmInfo \ --column-family film \ --hbase-row-key film_id m -1
From film_text table we would like to import title and description into filmText column family with film_id as the row key in Hbase.
sqoop import \ --connect jdbc:mysql://localhost/sakila \ --username root -P \ --table film_category \ --columns " title, description" \ --hbase-table filmInfo \ --column-family filmText\ --hbase-row-key film_id m -1
This tutorial highlighted the benefits of having a good understanding of Hbase before beginning any data modeling. Best practices in column family design were explained and how they result in better performance. The Sakila data model that comes with Mysql was introduced and it was demonstrated how the model could be converted from a relational to a Hbase model. This is just one of the ways the data can be modeled.


{kind=link}