

In the first part of Pig tutorial we explained how Pig fits in the Hadoop ecosystem as tool for performing data extraction, transformation and loading (ETL). In that tutorial installation and configuration of Pig was demonstrated. We also reviewed some operations that can be performed on data. For a review of those concepts please refer to that tutorial. In this tutorial the main objective is to demonstrate how to write functional scripts for performing ETL.
Scripts in Pig can be executed in interactive or batch mode. To use pig in interactive mode you invoke it in local or mapreduce mode then enter your commands one after the other. In batch mode you save your commands in a .pig file and specify the path to the file when invoking pig. We will demonstrate how the two modes are used.
At an overly simplified level a Pig script consists of three steps. In the first step you load data from HDFS. In the second step you perform transformations on the data. In the final step you store your transformed data. Transformations are the heart of Pig scripts so in this tutorial we will extensively review them. To demonstrate concepts in this tutorial we will use the New York Stock Exchange data on dividends and prices for the years 2000 and 2001. The data is available from here https://s3.amazonaws.com/hw-sandbox/tutorial1/infochimps_dataset_4778_download_16677-csv.zip.
Pig has a schema concept that is used when loading data to specify what it should expect. You specify columns and optionally their data types. Any columns in your data but not included in the schema are truncated. When you have fewer columns than those specified in your schema they are filled with nulls. To load our sample data sets we first move them to HDFS then from there we will load into Pig.
hadoop fs -mkdir /usr/eduonix/stock_data
hadoop fs -put /home/eduonix/Downloads/infochimps_dataset_4778_download_16677/NYSE/NYSE_daily_prices_A.csv /usr/eduonix/stock_data
hadoop fs -put /home/eduonix/Downloads/infochimps_dataset_4778_download_16677/NYSE/NYSE_dividends_A.csv /usr/eduonix/stock_data

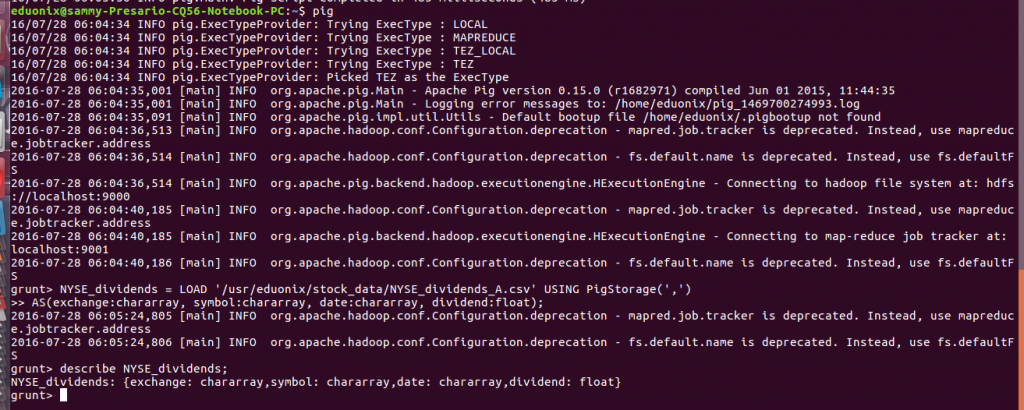
To load data into Pig you use the LOAD and specify the HDFS location where your data is, the schema and the format your data is stored in. you are not limited to loading data in HDFS you can also load data in other formats like Hbase. When your data is stored as a csv you specify that in PigStorage option. To load the stock data we use the commands below
pig
NYSE_dividends = LOAD '/usr/eduonix/stock_data/NYSE_dividends_A.csv' USING PigStorage(',')
AS(exchange:chararray, symbol:chararray, date:chararray, dividend:float);
describe NYSE_dividends;
NYSE_daily = LOAD '/usr/eduonix/stock_data/NYSE_daily_prices_A.csv' USING PigStorage(',')
AS(exchange, stock_symbol, date, stock_price_open, stock_price_high, stock_price_low, stock_price_close, stock_volume, stock_price_adj_close);
When writing pig scripts there are several key points to have in mind.
- A new data set or relation will result from a processing step.
- Keywords are case insensitive but relations and field names are case sensitive.
- To place comments on a single line you use — while to place comments on multiple lines you us /* */
As previously noted transformations are the main area where data flow pipelines add value to data. We are going to discuss the main relational operators used. The foreach operator is used to apply expressions on each record in the data which results in a new records that are sent down the pipeline. For example from the daily prices data we loaded earlier we would be interested in calculating the difference between high and low price. We would use foreach as shown below
stock_difference = foreach NYSE_daily generate stock_price_high + stock_price_low;
![]()
Standard mathematical operators can be used when defining expressions in the foreach operator.
The filter operator is used to retain records that will be passed to the next level in a pipeline and discard the others. Operators supported include ==, !=, >, >=, <, <=. Records that evaluate to true are passed on in the pipeline, otherwise they are not. For example from our daily stocks data we would be interested only in records where the closing price is higher than the opening price we would use the command below.
high_stocks = filter NYSE_daily by stock_price_close > stock_price_open;
![]()
The group statement is used to organize records that have the same key then you can use an aggregate function for further analysis. To organize the daily stock data by stock symbol we would use the command below.
grouped_stock = group NYSE_daily by stock_symbol;
After that we can then use the foreach operator and the count function
group_count = foreach grouped_stock generate group, count(NYSE_daily);

To sort data you use the order operator and the statement also ensures data in partitions is properly sorted. Use of this statement requires you to specify the key that will be used to sort data. An example of sorting data by date is shown below.
ordered_date = order NYSE_daily by date;
![]()
When using order statement you can specify more than one key to be used for sorting and you can also specify if sorting will be done ascending or descending. An example of use of more than column with sorting on one column done in a descending way is shown below.
ordered2_keys = order NYSE_daily by date desc, stock_symbol;
![]()
To remove all duplicate records in a data set you use a distinct statement. An example is shown below.
unique_rows = distinct NYSE_daily;
![]()
When you would like to join data from two streams you use the join statement. You specify a key from each stream and when the two keys are equal the records are retained otherwise they are dropped. You can specify more than one key but keys for each stream must be equal and of compatible data types.
Earlier on we loaded the dividend and stock data. To join these two data sets using the stock_symbol column we would use the command below.
joined_data = join NYSE_daily by stock_symbol, NYSE_dividends by symbol;
![]()
For greater flexibility the join statement supports left, right and full options similar to those available in SQL. In a left join even if there is no match on right all records on the left will be included. In a right join all records on right are included even when there is no match on the left. A full join includes records from all sides even when there is no match on either side.
This tutorial briefly reviewed concepts that were covered in first part of Pig. It introduced you to writing transformations in Pig. The structure of a pig script was explained. Statements used in transforming data were explained and examples were given. Finally joining data was demonstrated.


{kind=link}