

What is HDFS (Hadoop Distributed File System):
HDFS is a distributed file system that is fault tolerant. HDFS is the primary distributed storage for Hadoop applications. It provides an interface to the applications to move themselves closer to data. Hadoop is all about the efficient processing of large chunks of data.
It’s therefore important to understand how Hadoop store its data. HDFS organizes its file system differently from the underlying file system such as Linux ext3 or ext4 file system. HDFS employs a block-based file system, wherein files are broken up into blocks. A file and a server in the cluster don’t have a one-to-one relationship. This means that a file can consist of multiple blocks, all of which most likely won’t be stored on the same machine.
Component of HDFS:
There are two types of major components in HDFS.
1) Name Node: This is the brain of the HDFS, it decides where to put the data into Hadoop cluster. It manages the filesystem metadata.
2) Data Node: Data Node is the place where HDFS stores the actual data.
HDFS enables users to store data in files, which are split into multiple blocks. Since Hadoop is designed to work with massive amounts of data, HDFS block sizes are much larger than those used by typical relational databases. The default block size is 128MB, and you can configure the size to, as high as 512MB.
HDFS Architecture:
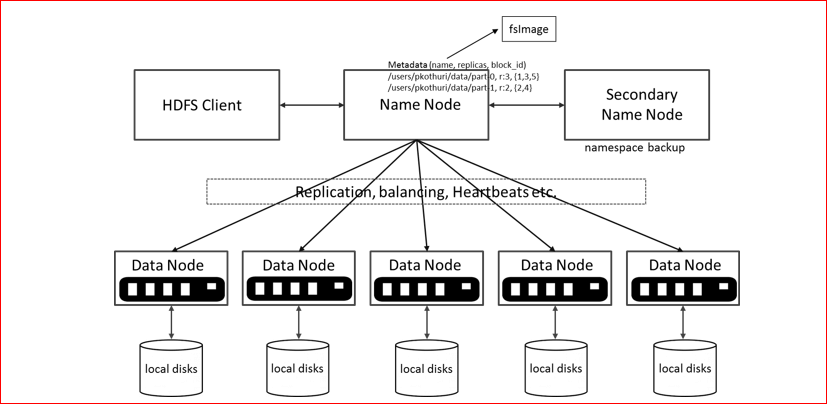
The HDFS data is distributed among the cluster’s nodes but appears to you as a single unified file system that you can access from any of the cluster’s nodes. You can run a cluster with a single NameNode whose job is to maintain and store metadata pertaining to the HDFS file system.
Unique Features of HDFS:
- Fault tolerant: Single data blocks get stored onto multiple machines depending upon replication factor. This unique feature makes Hadoop fault tolerant cause unavailability of any node that won’t affect the data. If replication factor is 3, data will get stored onto three data nodes.
- Scalability: data transfer happens directly with the data nodes so your read/write capacity scales fairly with the number of data nodes.
- Space: In case of extra space requirement, just add another data node and rebalance all data nodes.
HDFS & Data Organization:
Each file that is written onto data nodes gets splits into blocks. No of blocks depends upon replication factor. Each block gets stored on different-different data nodes.
Block Placements:
1) First replica of data block gets stored onto local machine.
2) Second Replica gets stored on machine in different rack.
3) Third replica of same block gets stored onto different machine but the rack of second & Third replica remains same.
HDFS Configuration:
Replication factor, Block size gets defined in the hdfs-site.xml file. Refer following property to declare the block size and replication factor.
Go to /usr/local/hadoop/etc/hadoop and add the following property into hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop_store/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop_store/hdfs/datanode</value> </property> </configuration>
HDFS Commands Type:
User Commands:
hdfs dfs – runs filesystem commands on the HDFS
hdfs fsck – runs a filesystem checking command
Administration Command:
hdfs dfsadmin – runs HDFS administration commands.
A) HDFS User Commands:
1) hdfs dfs -ls /
List all the files/directories for the given hdfs destination path

2) hdfs dfs -ls –R /”directoryname”
Recursively list all files in hadoop directory and all subdirectories in the directory.

3) hdfs dfs -cat /hadoop/test
This command will display the content of the HDFS file test on your stdout.

4) hdfs dfs -put /home/hduser/samplefile /hadoop
Copies the file from local file system to HDFS.
{File samplefile was already present in local file system}

5) hdfs dfs -put –f /home/hduser/samplefile /hadoop
Copies the file from local file system to HDFS, and in case the local already exist in the given destination path, using -f option with put command will overwrite it.
6) hdfs dfs -cp /hadoop/test /hadoop1
Copies file from source to destination on HDFS. In this case, copying file ‘test’ from hadoop directory to hadoop1 directory.

7) hdfs dfs -rm /hadoop1/test
Deletes the file (sends it to the trash).

8) hdfs dfs -df /hadoop
Shows the capacity, free and used space of the filesystem.

9) hdfs dfs -du -h /hadoop/test
Show the amount of space, in bytes, used by the files that match the specified file pattern. Formats the sizes of files in a human-readable fashion.

10) hdfs dfs -df -h /hadoop
Shows the capacity, free and used space of the filesystem. -h parameter Formats the sizes of files in a human-readable fashion.

B) HDFS Administration Command:
1) hadoop version
To check the version of Hadoop

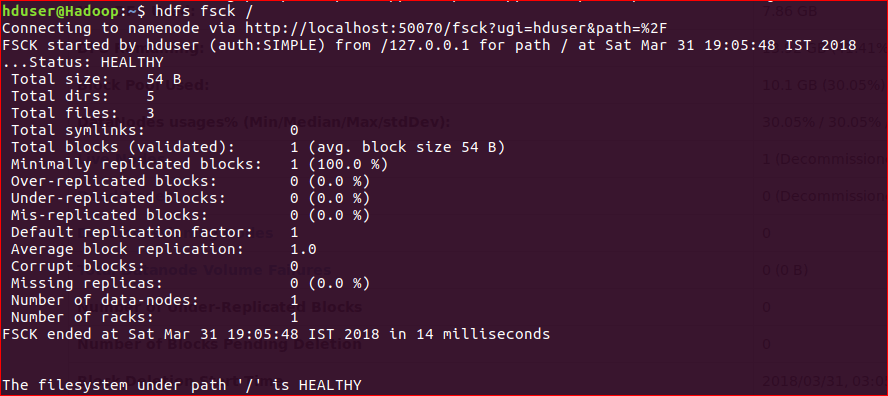
2) hdfs fsck /
It checks the health of the Hadoop file system.
3) hdfs dfsadmin -refreshNodes
Re-read the hosts and exclude files to update the set of Datanodes that are allowed to connect to the Namenode and those that should be decommissioned or recommissioned.

4) hdfs namenode -format
This command runs only once while starting the Hadoop environment. It Formats the NameNode so never use this command as this will delete all the data in the Hadoop cluster, all data will be lost with no recovery option.
Conclusion: –
HDFS is the integral part of Hadoop ecosystem. For better output, HDFS management is most important. HDFS provides data transfer in-between the nodes very quickly.
HDFS works closely with MapReduce and other programming models that support Hadoop and provide assistance in managing the BigData. HDFS is also important because of its Fault tolerant feature.
For more HDFS management commands, please refer hadoop.apache.org.


{kind=link}