
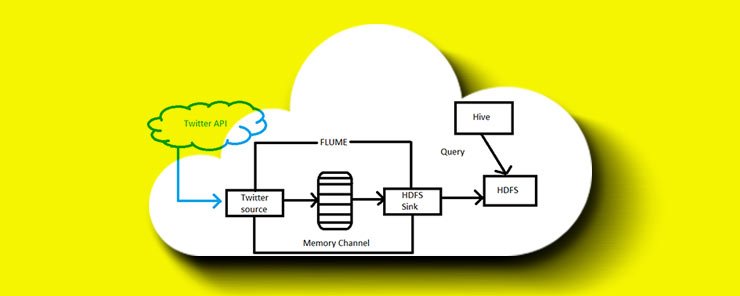
Apache Hive is project within the Hadoop ecosystem that provides data warehouse capabilities. It was not designed for processing OLTP workloads. It has features for manipulating large distributed data using a SQL-like language called HiveQL. This makes it suitable for extract/transform (ETL), reporting and data analysis problems. HiveQL queries are translated into Java MapReduce code which runs on Hadoop. The queries are executed by Mapreduce, Apache Tez or Apache Spark. Hive queries run on Mapreduce take long to run because of batch processing. Spark provides a way to run low latency queries. Spark provides better performance than MapReduce without requiring any changes in queries. Hive is able to access data stored in HDFS, Hbase andAmazon S3.
This tutorial requires a fair understanding of relational databases.
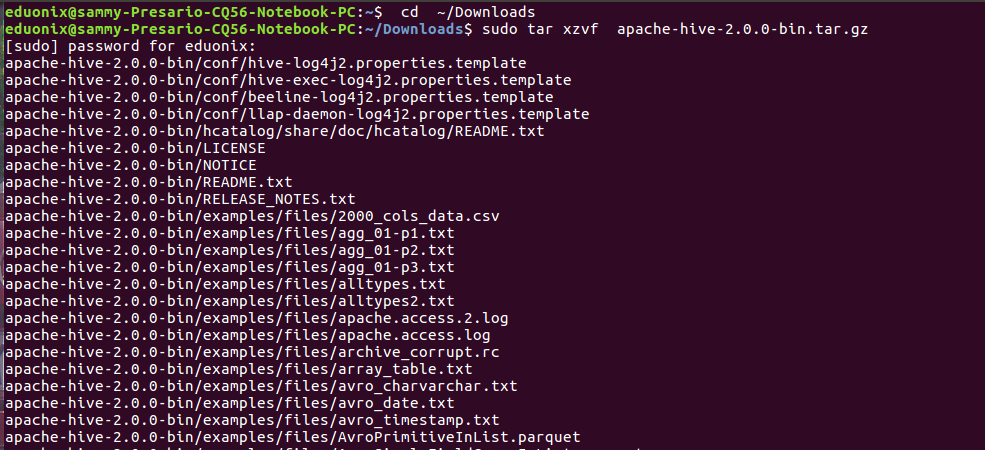
Hive requires a working installation of Hadoop before installation. Verify Hadoop is installed before beginning Hive installation. Move to the downloads folder, extract the hive tar, move it to its installation folder and assign its ownership to user eduonix.
cd ~/Downloads sudo tar xzvf apache-hive-2.0.0-bin.tar.gz sudo mv apache-hive-2.0.0-bin /usr/local/hive sudo chow -R eduonix /usr/local/hive

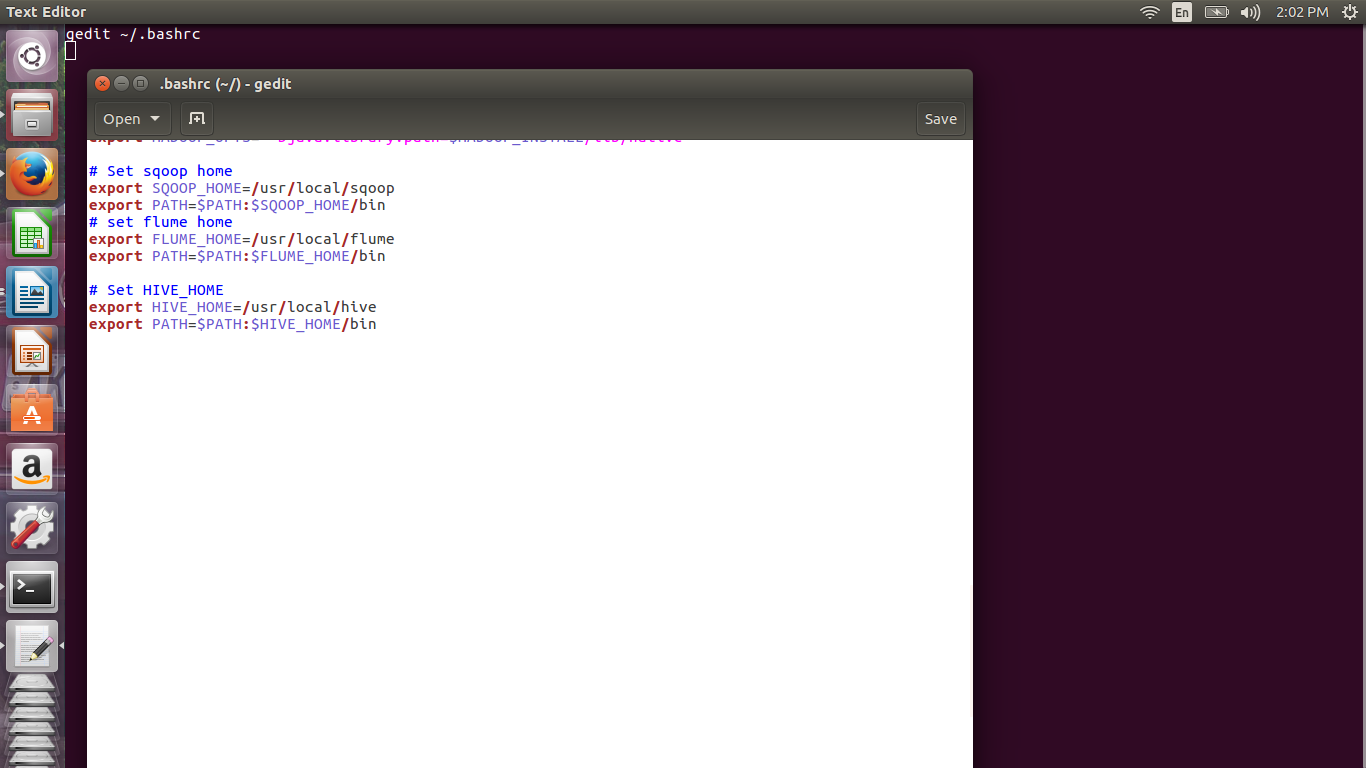
Open .bashrc in a text editor by running gedit ~/.bashrc and add lines below.
# Set HIVE_HOME export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin
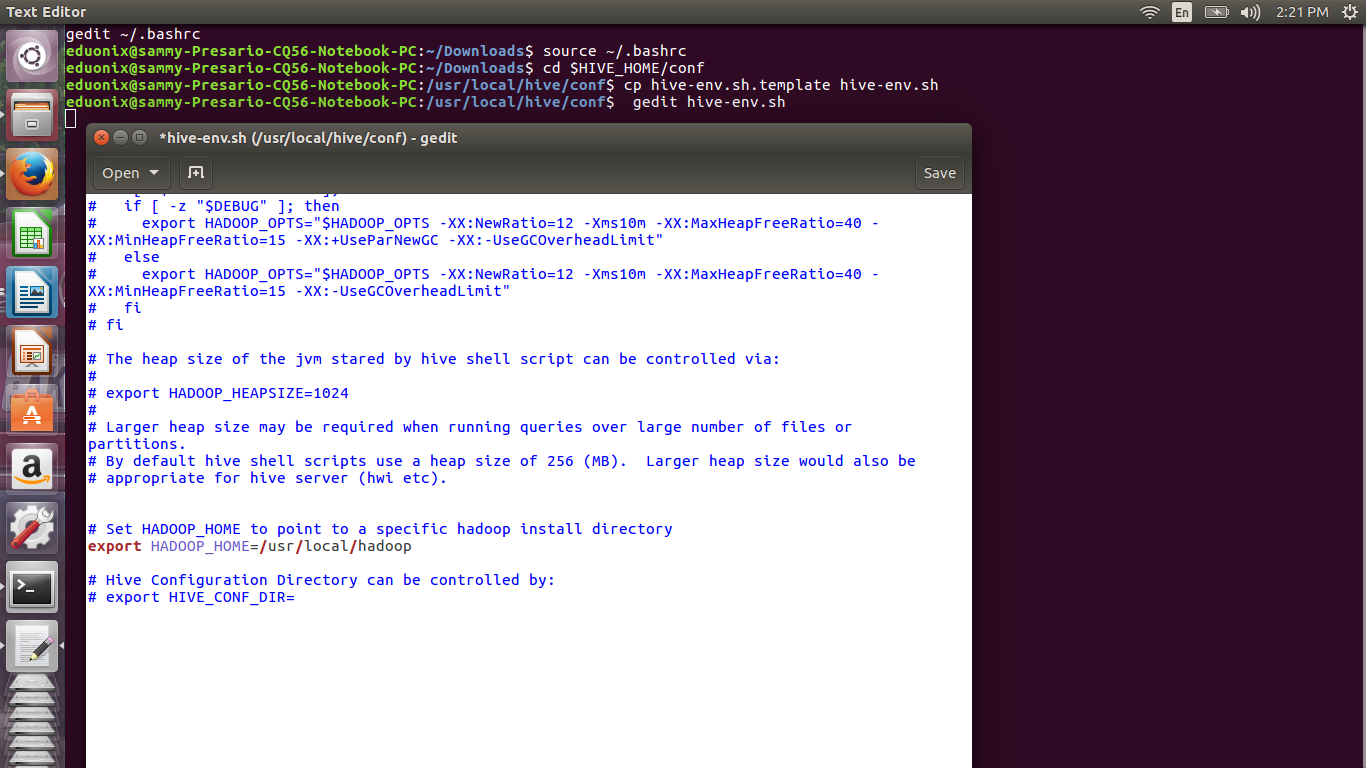
Save the file and reload it by running source ~/.bashrc
Rename the hive-env.sh.template provided to hive-env.sh and open it in a text editor.
cd $HIVE_HOME/conf cp hive-env.sh.template hive-env.sh gedit hive-env.sh
Add the line below to point Hive to the Hadoop installation
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.1
Hive requires a database for its metastore. Derby comes preinstalled but it is only useful as a test enviroment. Mysql is a better option and in this tutorial it’s use will be demonstrated. Installation of Mysql was demonstrated in the Sqoop tutorial so it will not be repeated.
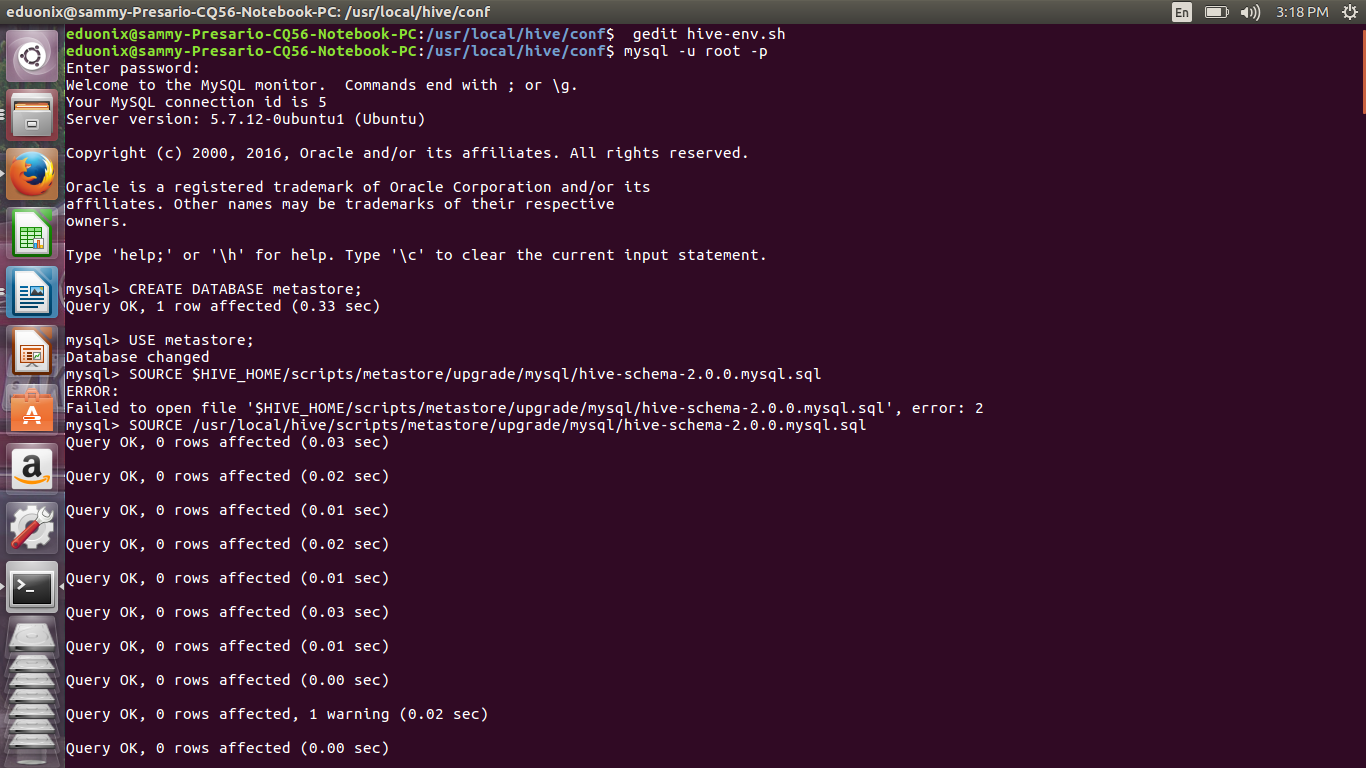
Copy the mysql connector jar into $HIVE_HOME/lib/. Create the metastore database and create the schema using hive-schema-2.0.0.mysql.sql.
mysql -u root -p CREATE DATABASE metastore; USE metastore; SOURCE /usr/local/hive/scripts/metastore/upgrade/mysql/hive-schema-2.0.0.mysql.sql
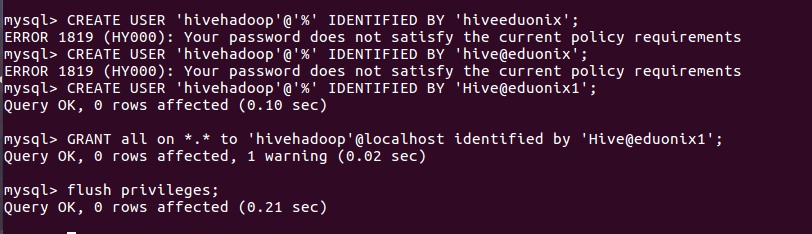
Create a Mysql account that Hive will use to access metastore.
CREATE USER 'hivehadoop'@'%' IDENTIFIED BY 'Hive@eduonix1'; GRANT all on *.* to 'hivehadoop'@localhost identified by 'Hive@eduonix1'; flush privileges;
In /usr/local/hive/conf create a hive-site.xml and add the configuration settings below.
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost/metastore</value> <description>metadata is stored in a MySQL server</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>MySQL JDBC driver class</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hivehadoop</value> <description>user name for connecting to mysql server</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hiveeduonix</value> <description>password for connecting to mysql server</description> </property> </configuration>
Invoke the hive console and create a table to test the metastore.
hive
create table eduonixhive(id int, name string);
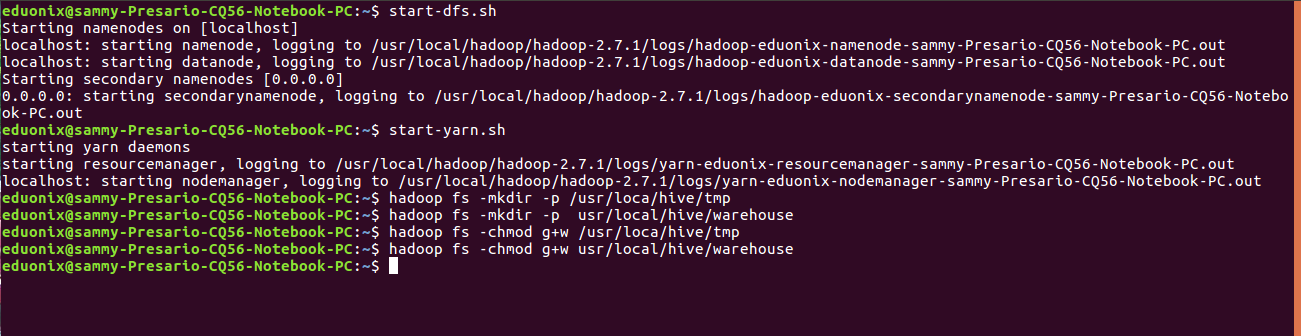
In the hadoop file system create a temporary directory /usr/loca/hive/tmp that will be used to store results of intermediate data processing. Create a directory usr/local/hive/warehouse that will be used to store hive data. The permissions on these directories are then changed to read/write. Before running these commands make sure hadoop is running
start-dfs.sh start-yarn.sh hadoop fs -mkdir -p /usr/loca/hive/tmp hadoop fs -mkdir -p usr/local/hive/warehouse hadoop fs -chmod g+w /usr/loca/hive/tmp hadoop fs -chmod g+w usr/local/hive/warehouse
Run hive at the terminal to start hive and avail its terminal.
We create a table in Hive to test if it is working properly
create table eduonixcourses (id int, name string, instructor string);

We need to confirm the metadata of the table we created above is in metastore. Login to Mysql console, select metastore database and show it’s tables.
mysql -u root -p use metastore; show tables ;
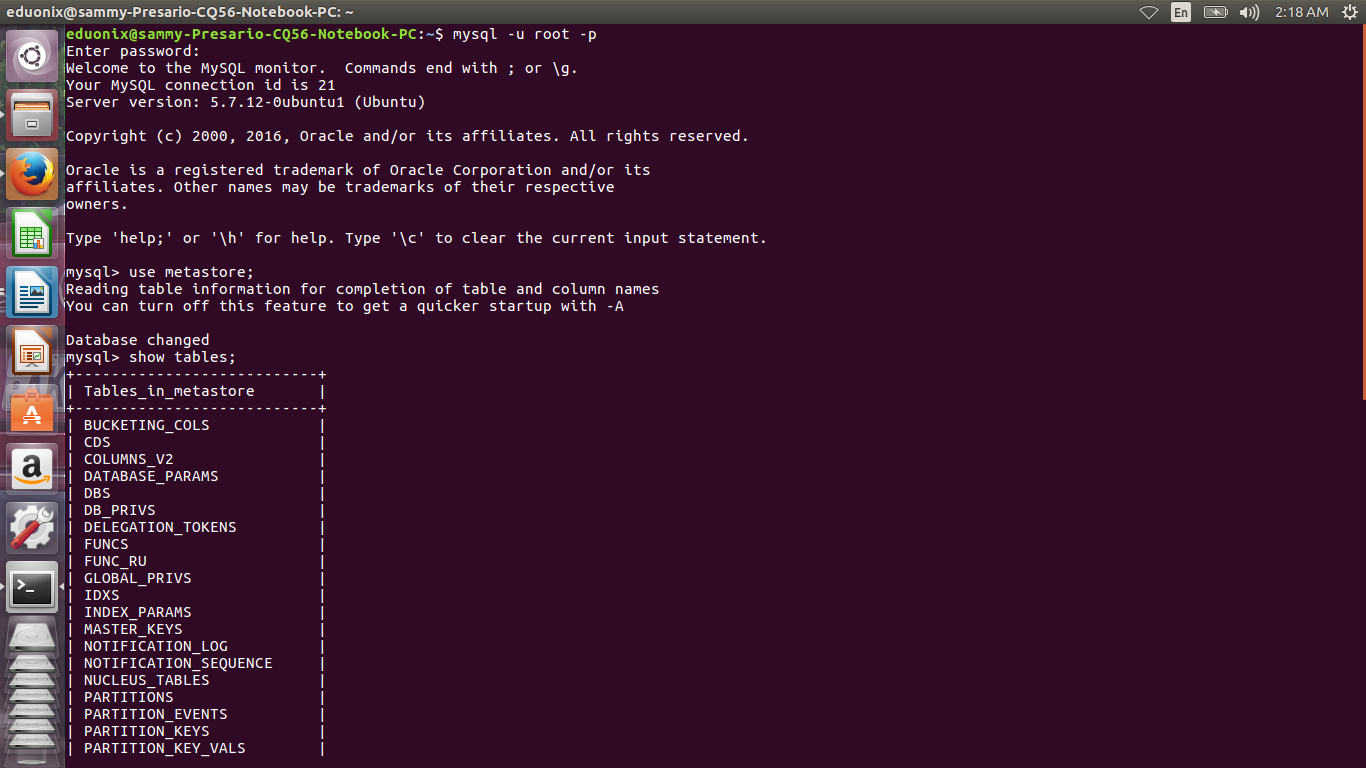
Query the metastore to check the metastore for database eduonixcourses exists.
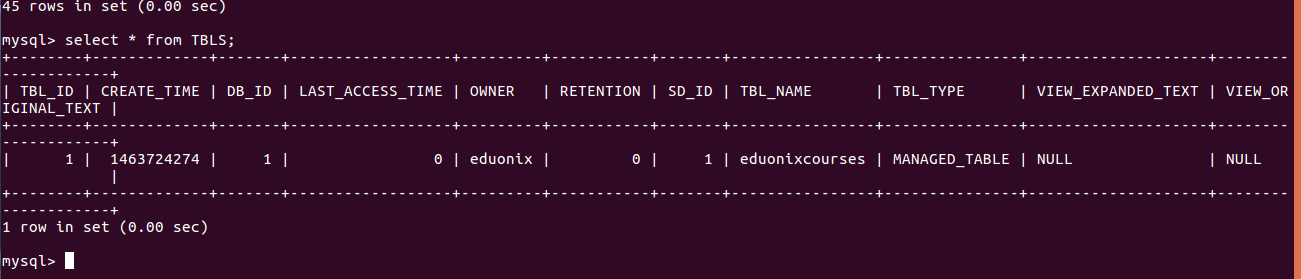
The eduonixcourses database has been created in the metastore repository so our Hive installation is working properly.
Hive organizes data into databases, tables, partitions and buckets or clusters. The first three concepts are similar to those used in relational databases. Partitioning and bucketing of tables is not mandatory but it provides a way of pruning thereby speeding query processing. Primitive and complex data types for specifying columns are available in Hive. Primitive types available are: number, float, double, bigint, smallint, tinyint, int, string and boolean. The complex types available are structs, maps and arrays. Arithmetic and logical operators similar to those in relational databases are also available in Hive.
Some data operations provided by HiveQL are listed below
- Creation, dropping and altering of tables and partitions
- Using SELECT clause to select specific columns
- Using joins on two tables
- Filtering data using the WHERE clause
- Storage of query results in the hadoop file system
These are some of the features provided by HiveQL that are commonly used. For a complete perspective of what the language offers refer to the hive data definition language manual.
In the sqoop tutorial we demonstrated how sqoop is used as a tool for importing data from relational databases into hadoop. Here we will demonstrate how data can be loaded into Hadoop from the local system. We will then load data into Hive from the local system. Download the cars.csv data from http://perso.telecom-paristech.fr/~eagan/class/as2013/inf229/data/cars.csv. This is data that measured the fuel consumption and other characteristics of eight car models.
First we need to do some preprocessing then upload the data into HDFS. Navigate to the downloads directory and check if the cars.csv data has any headers. If they are there we need to remove them because they are not part of the data.
cd ~/Downloads head cars.csv sed -i id cars.csv

Once the headers have been removed we can upload the data into hdfs
hadoop fs -put cars.csv /usr/hadoop/cars.csv

before we can upload the data into Hive we need to create a table similar in structure to the data we are loading. Invoke hive and run the commands below
CREATE DATABASE cardata; CREATE TABLE IF NOT EXISTS cars_performance( Name STRING, Miles_per_Gallon INT, Cylinders INT, Displacement INT, Horsepower INT, Weight_in_lbs INT, Acceleration DECIMAL, Year DATE, Origin CHAR(1));
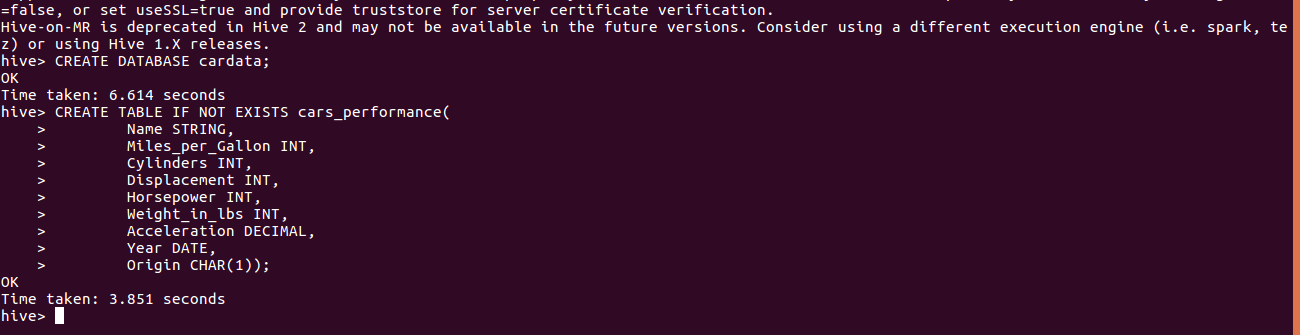
With the cars.csv data in hdfs and the database structure in place we can load the data into Hive.
LOAD DATA INPATH '/user/hadoop/cars.csv' OVERWRITE INTO TABLE cars_performance;

This tutorial has highlighted the role of Hive in the Hadoop ecosystem. It has explained the features provided by Hive to enable management and analysis of data. It has explained how data is organized in Hive. It has explained how to install and configure Hive on top of Hadoop. Loading data into hdfs from the local system then into hive has also been demonstrated.


{kind=link}