
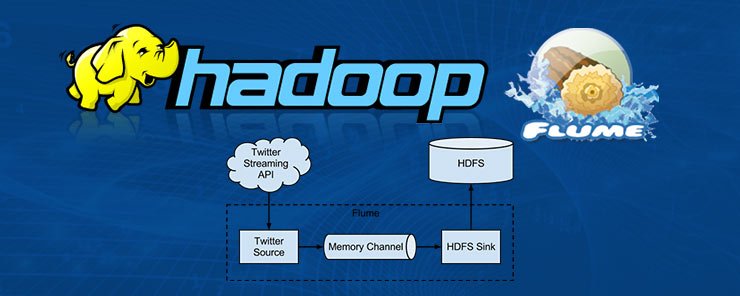
Apache Flume is a tool in the Hadoop ecosystem that provides capabilities for efficiently collecting, aggregating and bringing in large amounts of data into Hadoop. Examples of large amounts of data are log data, network traffic data, social media data, geo-location data, sensor and machine data and email message data. Flume provides several features to manage data. It lets users ingest data from multiple data sources into Hadoop. It protects systems from data spikes when the rate of data inflow exceeds the rate at which data is written. Flume NG guarantees data delivery using channel based transactions. Flume scales horizontally to process more data streams and data volumes.
Flume requires at least java 7, adequate memory and storage, and adequate read/write permissions for agents. Flume runs as one or more agents. An agent is a JVM process hosting the components that transmit data from an external source to the next step. An agent consists of three components vit source, channel and sink and requires at least one component to run. Flume sources listen to and consume events depending on the source the agent is configured to use. Flume agents can have multiple sources but at least one source is required. Some data sources supported by Flume are: Avro, netcat, seq, exec, syslogtcp and syslogudp. Once an event consumes an event it writes the event to a channel as a transaction. Use of events and transactions maintains readability through out a data flow.
Channels provide a way for Flume to transfer events from sources to sinks. Once an event is written to a channel by a source it remains there until it is removed there by a sink in a transaction. This enables Flume sinks to retry failed writes. In-memory queues and durable disk based queues are the two types of channels available in Flume. In-memory channels provide high throughput but avail no recovery when an agent fails. File or database backed channels provide full recovery when an agent fails. Sinks provide a way for Flume to output data. Some supported sinks are Avro, hdfs, HbaseSink and irc.
To install Flume download it from your nearest mirror. Navigate to the Downloads directory, extract the package and move it to its installation directory beneath /usr/local
First confirm Hadoop is installed by running hadoop version
cd ~/Downloads
sudo tar xzf apache-flume-1.6.0-bin.tar.gz
sudo mv apache-flume-1.6.0-bin usr/local/flume
Change ownership of flume directory to user eduonix
sudo chown -R eduonix /usr/local/flume

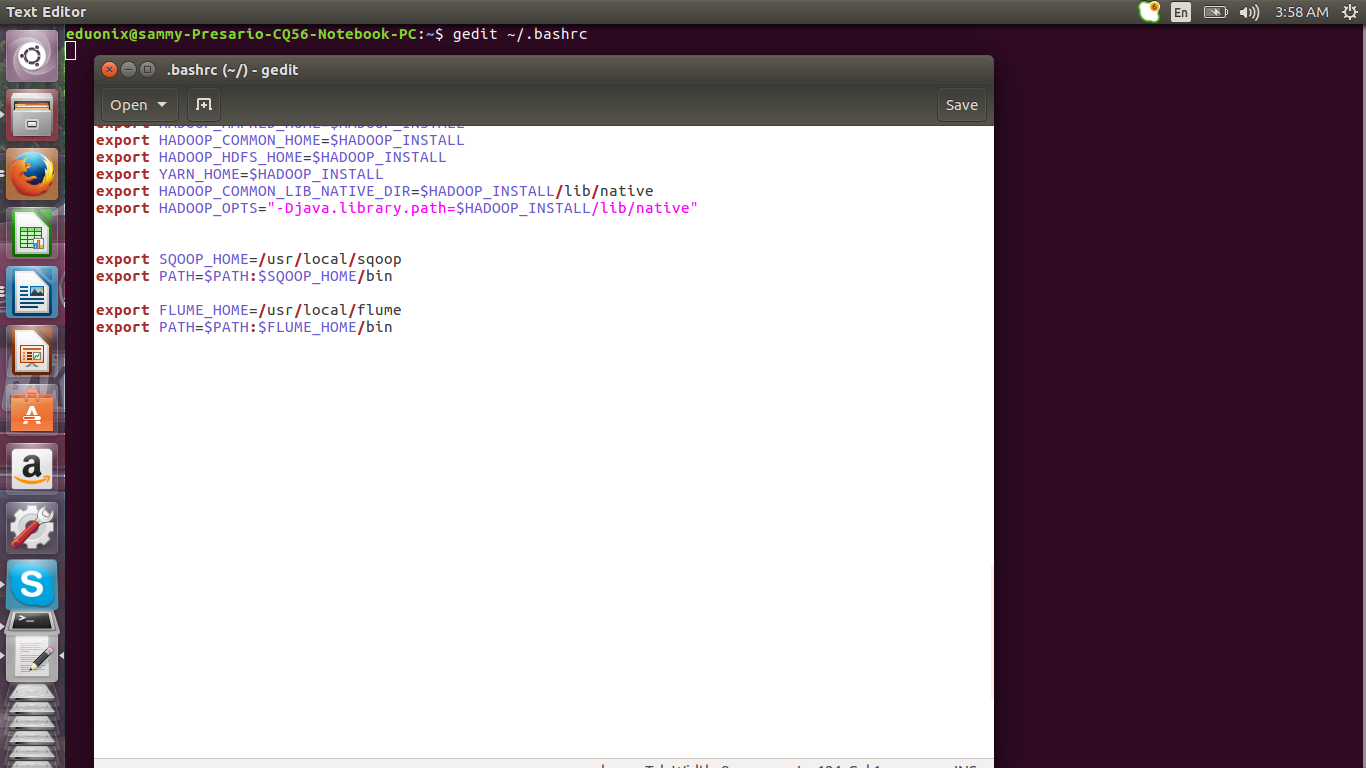
Set your home path by editing .bashrc and adding path to sqoop bin
gedit ~/.bashrc
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin
Reload .bashrc using source ~/.bashrc
Reload .bashrc using source ~/.bashrc
Run flume-ng version to confirm flume has been properly installed

You set up an agent using a configuration file which specifies the Java properties. The configuration file contains properties of each source, sink and channel in an agent and how they are joined in forming an agent. Each component in the data flow has a name, type and specific properties.
To demonstrate how Flume is used we will create an example by sourcing data from twitter and importing it into HDFS. First we create an app on twitter by following this link https://apps.twitter.com/
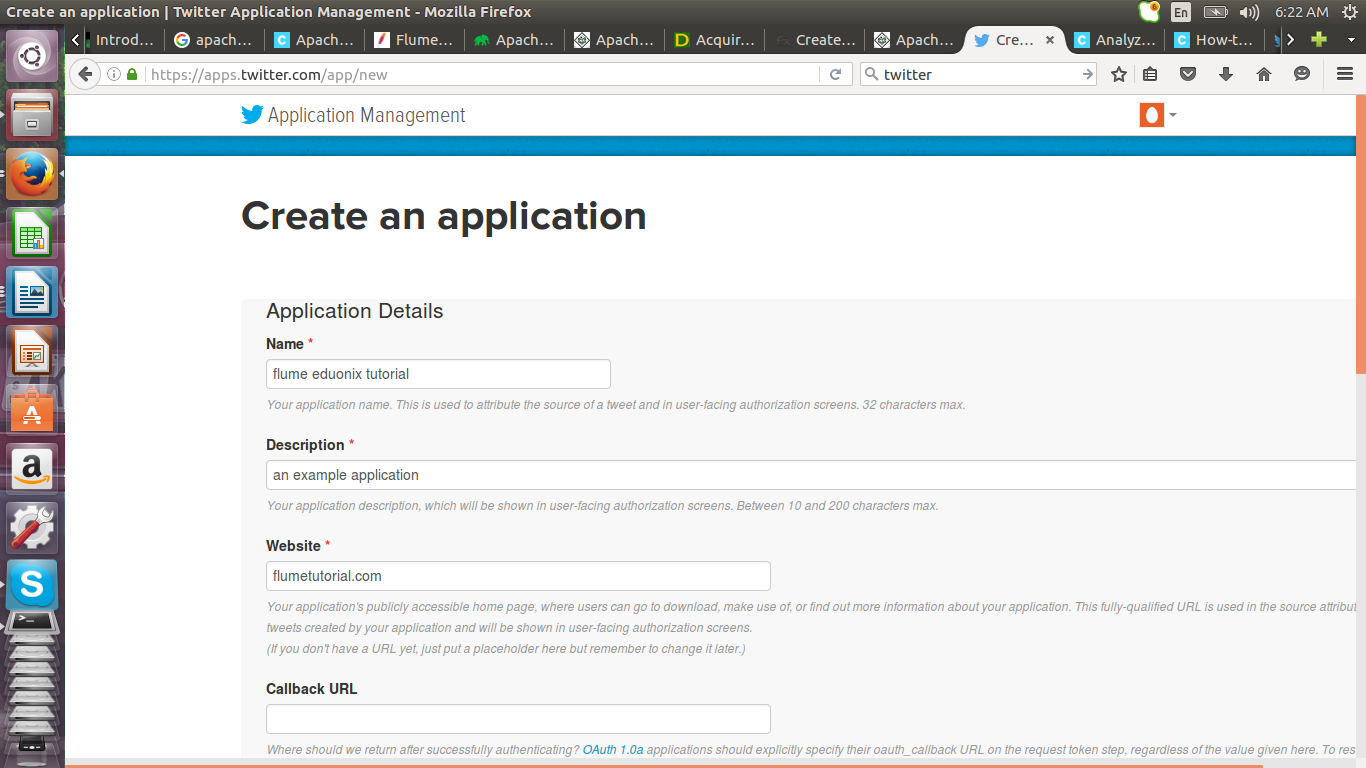
Fill in the details of your application and accept the license agreement
Click on keys and access tokens tab and click on create my access token button.
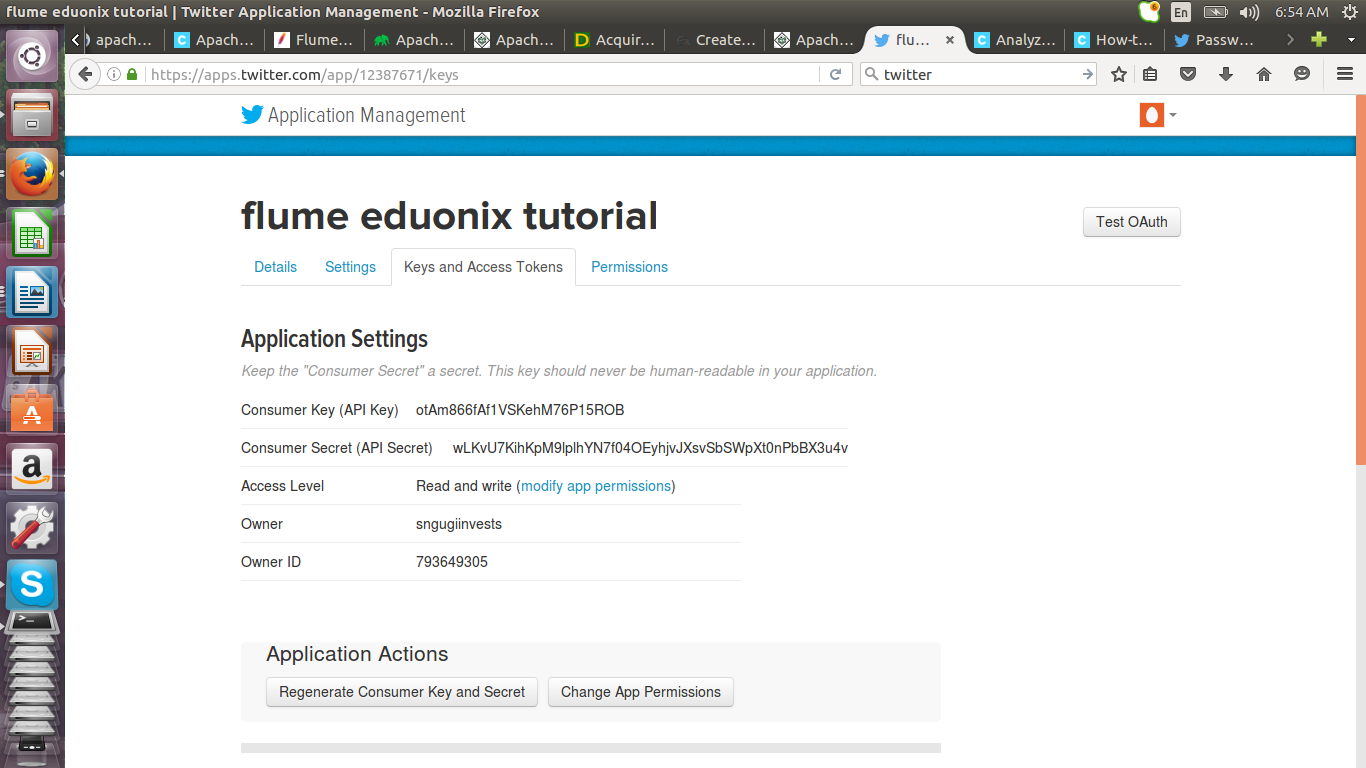
Your application will be generated
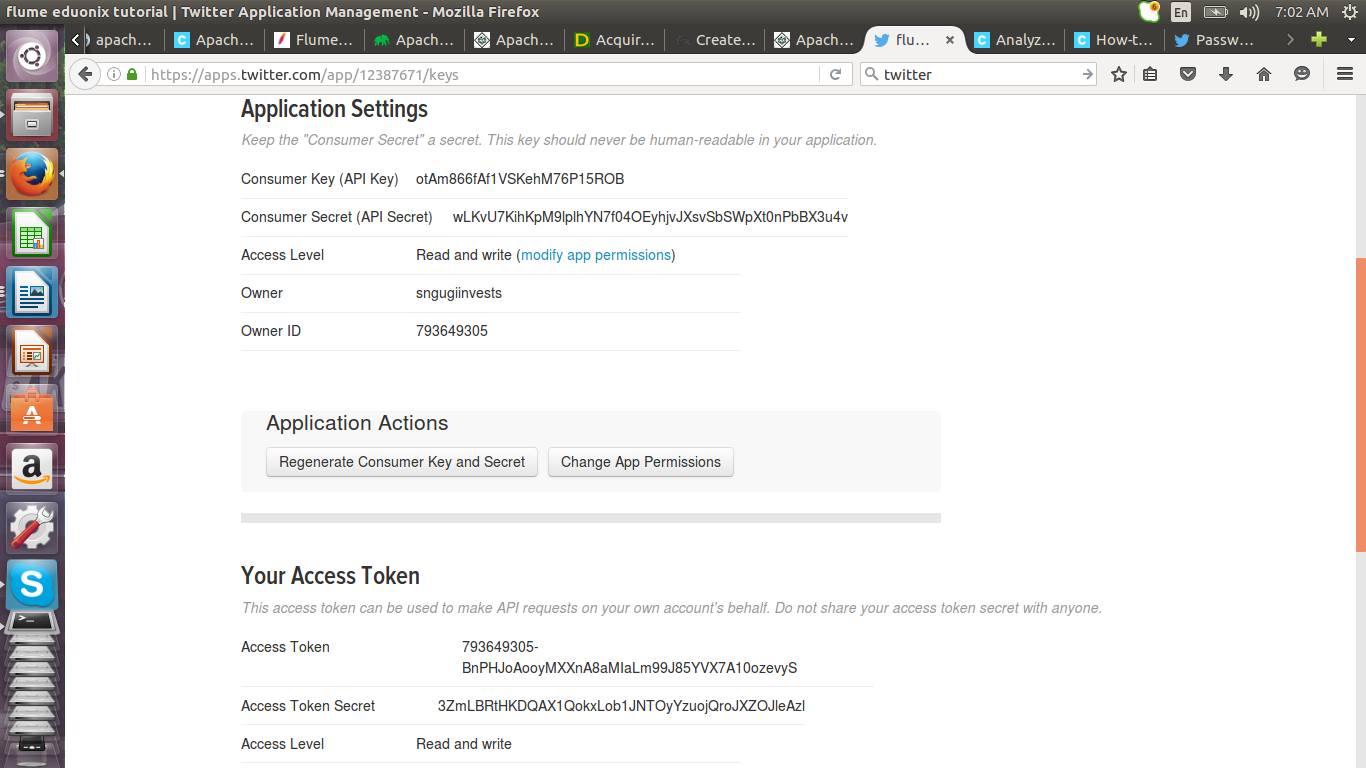
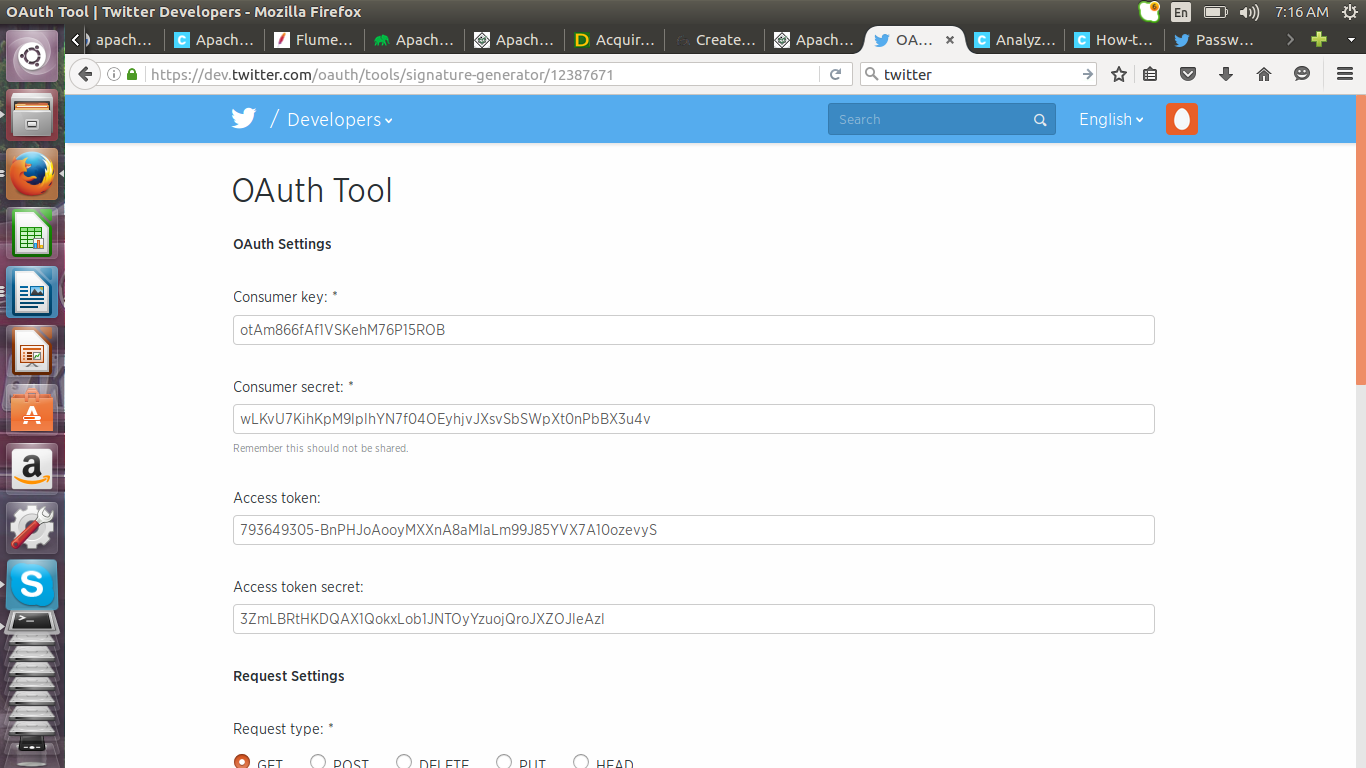
Click on test o auth button to get the details for configuring Flume.
Start hadoop and yarn by running the comands below
start-dfs.sh
start-dfs.sh

Create a directory in the hadoop file system to store data extracted from twitter
hadoop fs -mkdir -p /usr/local/twitter_data
![]()
Assign ownership to user eduonix
hadoop fs -chown -R eduonix /usr/local/twitter_data
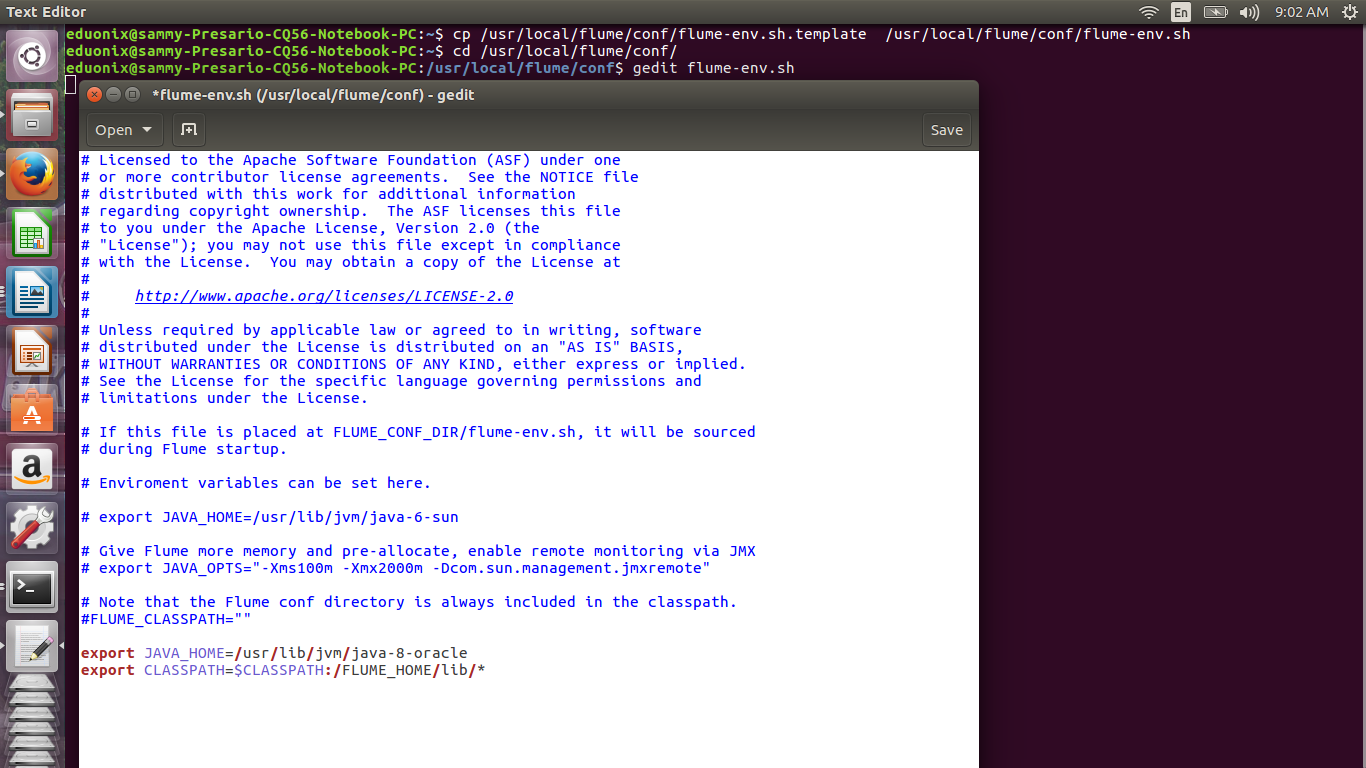
We will use the Twitter 1% Firehose source to get data from twitter. The default Flume installation has the required core, media support and stream jar files. Create a flume-env.sh file from the template provided then open Flume-env.sh and add the lines below
cp /usr/local/flume/conf/flume-env.sh.template /usr/local/flume/conf/flume-env.sh cd /usr/local/flume/conf/ gedit flume-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*
Open a text editor and add the lines below, save it as a configuration file in conf directory of flume. The first section describes the agent’s name, source, channel and sink. The second section specifies the properties of the data source. It is here that we use consumer key, consumer secret, access token and access token secret. We also specify the keywords that we need to get data on. The third section describes the properties of the sink that we will use. We use a hdfs sink and specify the data will be stored in the /usr/local/twitter_data directory. The fourth section specifies we will use a memory channel. The MemChannel.capacity option specifies maximum number of events that can be placed in the channel. The MemChannel.transactionCapacity specifies max events the channel can receive or send. The last section connects the source and the sink using the channel.
# Naming the components on the current agent. EduonixTwitterAgent.sources = Twitter EduonixTwitterAgent.channels = MemChannel EduonixTwitterAgent.sinks = HDFS # Describing/Configuring the source EduonixTwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource EduonixTwitterAgent.sources.Twitter.consumerKey = otAm866fAf1VSKehM76P15ROB EduonixTwitterAgent.sources.Twitter.consumerSecret = wLKvU7KihKpM9lplhYN7f04OEyhjvJXsvSbSWpXt0nPbBX3u4v EduonixTwitterAgent.sources.Twitter.accessToken = 793649305-BnPHJoAooyMXXnA8aMIaLm99J85YVX7A10ozevyS EduonixTwitterAgent.sources.Twitter.accessTokenSecret = 3ZmLBRtHKDQAX1QokxLob1JNTOyYzuojQroJXZOJleAzl EduonixTwitterAgent.sources.Twitter.keywords = hadoop,hive, bigdata, mapreduce, sqoop, hbase, pig # Describing/Configuring the sink EduonixTwitterAgent.sinks.HDFS.type = hdfs EduonixTwitterAgent.sinks.HDFS.hdfs.path = /usr/local/twitter_data EduonixTwitterAgent.sinks.HDFS.hdfs.fileType = DataStream EduonixTwitterAgent.sinks.HDFS.hdfs.writeFormat = Text EduonixTwitterAgent.sinks.HDFS.hdfs.batchSize = 1000 EduonixTwitterAgent.sinks.HDFS.hdfs.rollSize = 0 EduonixTwitterAgent.sinks.HDFS.hdfs.rollCount = 10000 # Describing/Configuring the channel EduonixTwitterAgent.channels.MemChannel.type = memory EduonixTwitterAgent.channels.MemChannel.capacity = 10000 EduonixTwitterAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel EduonixTwitterAgent.sources.Twitter.channels = MemChannel EduonixTwitterAgent.sinks.HDFS.channel = MemChannel
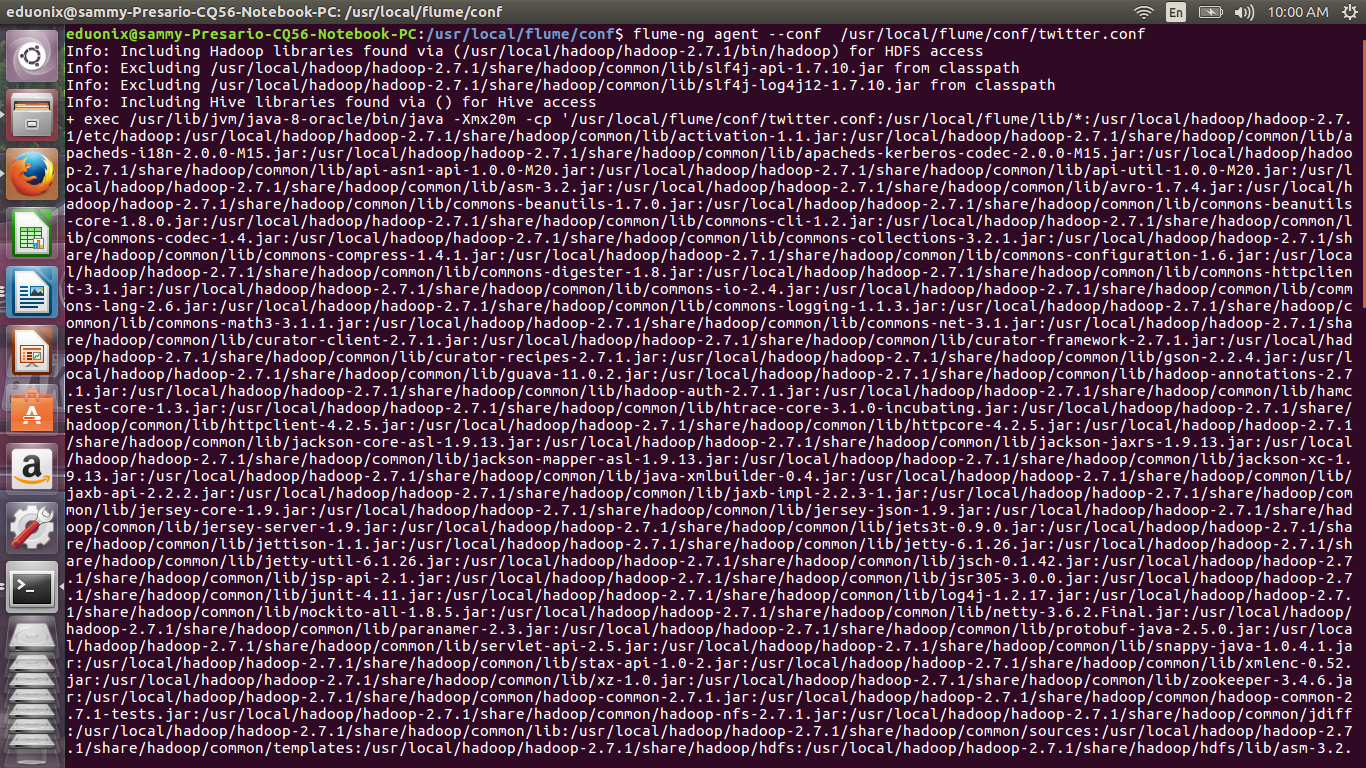
Once all the components have been specified we can call the agent to get the data and bring it to hdfs. The command below is used
flume-ng agent --conf /usr/local/flume/conf/twitter.conf
This tutorial has explained the role of Flume in the hadoop ecosystem as tool for bringing in big volumes of data. It has explained how Flume is deployed via an agent and the components of an agent. It has also demonstrated how to install and configure Flume. Specifying the components of an agent using a configuration file has been demonstrated. Finally the tutorial has shown how to call a flume agent.


{kind=link}
Thanks author for sharing this interesting blog post. I always looking for someone to post on Hadoop. Now this post really helps me to understand how to stream data into Hadoop using Apahe Flume.
Thanks again.
Hi Luna, above article is really nice,,i hope your looking for apache flume tutorial ,i hope it may be usefull for you.
Hi apache FLume is a best tool designed to working with streaming data, i send data into hdfs for storage and future analysis in apache flume
using three components like
1.source
2.channel
3.sink
it works with the streaming data sets.