

Introduction
Map reduce is the core technology of Hadoop and is the backbone of big data and Hadoop framework. This technology works in conjunction with HDFS (that is another core component of Hadoop framework). Map Reduce works as a data analysis tool whereas HDFS works as data Storage system. The combination of data analysis and data storage makes Hadoop more efficient to work with Big Data and is a very good example of unstructured data analysis tool.
Map reduce is mainly a software or an API based framework that is used for writing the jobs for analyzing the data, it also analyze various structured and unstructured data but the quantity is huge. The core functionality of Map and Reduce programming is that map and reduce functions directly works on data and the MAP and REDUCE functions are moved to the data, for analyzing data rather than data moving to the functions, that helps saving time, hardware capacity, making hardware more efficient and conserves bandwidth utilization.
Map-Reduce functions
Let’s discuss about basic functionality of these two core functions-:
Mapper function:
It takes the data in the form of key value pairs and emits the data again in key value pairs. The output of the Mapper functions is fed into the input of reducer function. The mapper function is capable of doing analysis with the help of filter and sorting functions and with these functions it yields a set of tuples with key-value combination.
Reducer Function:
It takes emitted output of Mapper function as the input and performs a summary. The operation may be any function like summation function for analysis purpose or any other function that is well suited for a particular problem statement. The functions are designed according to the problem statement and algorithm.
Let’s take an example of a basic hello world program that counts the number of words and there occurrences
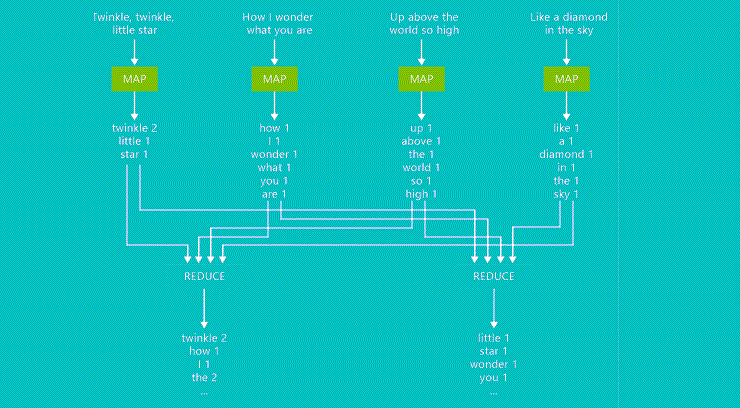
The output of the job is the total count of how many times a word has occurred in a particular sentence of a particular paragraph or any file that is fed to the Map-Reduce function and the Map-Reduce job will work over this particular input.
Hands on with Map-Reduce Programming and Some Technical Aspects of it
The Map-Reduce framework operates on key-value pair and the framework views the input given to the job as a key and value pair. The prime restriction of the key-value classes is that they need to be serializable by the framework itself so for that each mapreduce job has to implement writable interface.
A Map-Reduce job always splits the input data into chunks or logical boundaries known as input splits and these input splits are the logical chunks on which the Map and Reduce functions are performed. The Map-Reduce framework is responsible for scheduling the tasks and monitoring them with one job client or daemon known as JobTracker.
The question is that, how many input splits are needed for a Map-Reduce job to perform its execution; the answer is that number of map depends upon number of input splits.
Making Map-Reduce job to take new input splits
This is the concept of running a Map-Reduce job on ingested data or the data coming directly from a source application in some manner of live streaming. This is done by using a random read write NFS (Network file system) capability for hadoop that allows machines running NFS client to mount hadoop cluster into a local file system.
Testing and creating input splits on an incoming data
Hadoop always breaks a file into parts of data and that is obvious in every case of data before storing it into HDFS. MAPr refers this as chunk size and it always keeps this size as 256 MB.

Overriding some of the Map-Reduce Methods
The motive behind overriding is to use some important Map-Reduce methods and use Split ID
- Using path name of the input file
- Starting offset of the input file
- Length of the split
Step 1: Persisting the SPLIT_ID to a sub directory of the Map-Reduce output directory (where the output of a job is kept) on successful completion of a Map task.
Step2: Preprocessing the list of splits already passed to Map-Reduce job by looking up for each split in the persisted output directory.
Step3: Finally the main method is overridden in order to set the methods as a part of job initialization.
Without changing the original source code of the main method a new java class can be used that extend the basic Map-Reduce class, and this class can be repeatedly run as data start streaming.
While (file is still being streamed in)
hadoop jar newjob.jar newapp input output
Save off results file from output/part*
End
Demonstration of the solution using word count program
Some key points here to note are the SPLIT_ID that persist the use of a process known as task side effect files, these files are used when a mapreduce job attempt to emit additional data from a Map-Reduce task, but only succeed upon completion of the job.
Here we are not modifying the existing word count class; instead we are creating a new word count class with the modified code. A set of scripting class codes are also written to wrap the complete package and other relevant codes, after wrapping the codes word count (New word count program) is ran on sample data several number of times. After each run the part output files that contain results from the previous run of codes ingest the latest portion of codes and the file is saved for final aggregation.
Changing the format of the output file from /outputdir/part_r_00000 to output-pass-0, output-pass-1 and so on.
Finally in order to aggregate output from each iteration a single program is ran called as word count final that takes all these output directories as input and comes up with the final output file.
Summary
This article focuses on managing the input splits on real time data and making the analysis process easy by scripting a new word count program, without having to wait for a single job completion to happen.


{kind=link}