

In the Hadoop ecosystem Pig offers features for performing extraction, transformation and loading of data (ETL). In ETL the main objective is to acquire data, perform a set of transformations that add value to the data and load the cleansed data into a target system. Examples of transformations are removing duplicates, correcting spelling mistakes, calculating new variables and joining with other data sets. There are two components in Pig that work together in data processing. Pig Latin is the language used to express what needs to be done. An interpreter layer transforms Pig Latin programs into MapReduce or Tez jobs which are processed in Hadoop. Pig Latin is a fairly simple language that anyone with basic understanding of SQL can productively use it. Latin has a standard set of functions that are used for data manipulation and that are extensible by writing user defined functions (UDF) using java or Python.
Data processing in Pig involves three steps. In the first step data is loaded from hdfs. In the second step data passes through a set of transformations. In the final step data is sent to the screen or stored in a file.
Installation of Pig requires a properly configured Hadoop set up. Verify Hadoop is installed by running hadoop version at the terminal. If Hadoop is properly installed you should get similar output to that shown below. If Hadoop is not installed refer to the setting up Hadoop tutorial.

Download Pig from the closest mirror site. Move into the downloads directory extract the archive, move it into the correct installation directory and set the correct permissions.
cd ~/Downloads sudo tar xzvf pig-0.15.0.tar.gz sudo mv pig-0.15.0 /usr/local/pig sudo chown -R eduonix /usr/local/pig
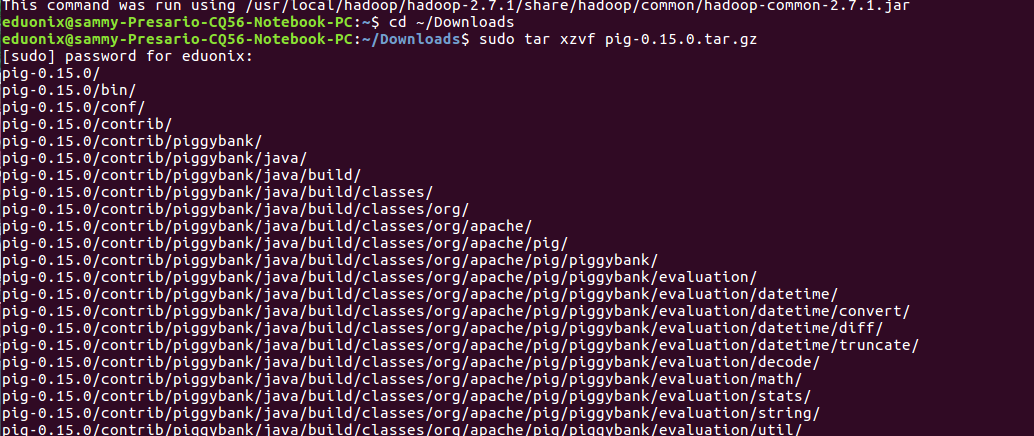

Open .bashrc in a text editor and add the lines below to set pig home directory gedit ~.bashrc
### Pig Home directory
export PIG_HOME=”/usr/local/pig/” export PIG_CONF_DIR=”$PIG_HOME/conf” export PATH=”$PIG_HOME/bin:$PATH” export HADOOP_CONF_DIR = “/usr/local/hadoop/hadoop-2.7.1/etc/hadoop” export PIG_CLASSPATH=”/usr/local/hadoop/hadoop-2.7.1/etc/hadoop”
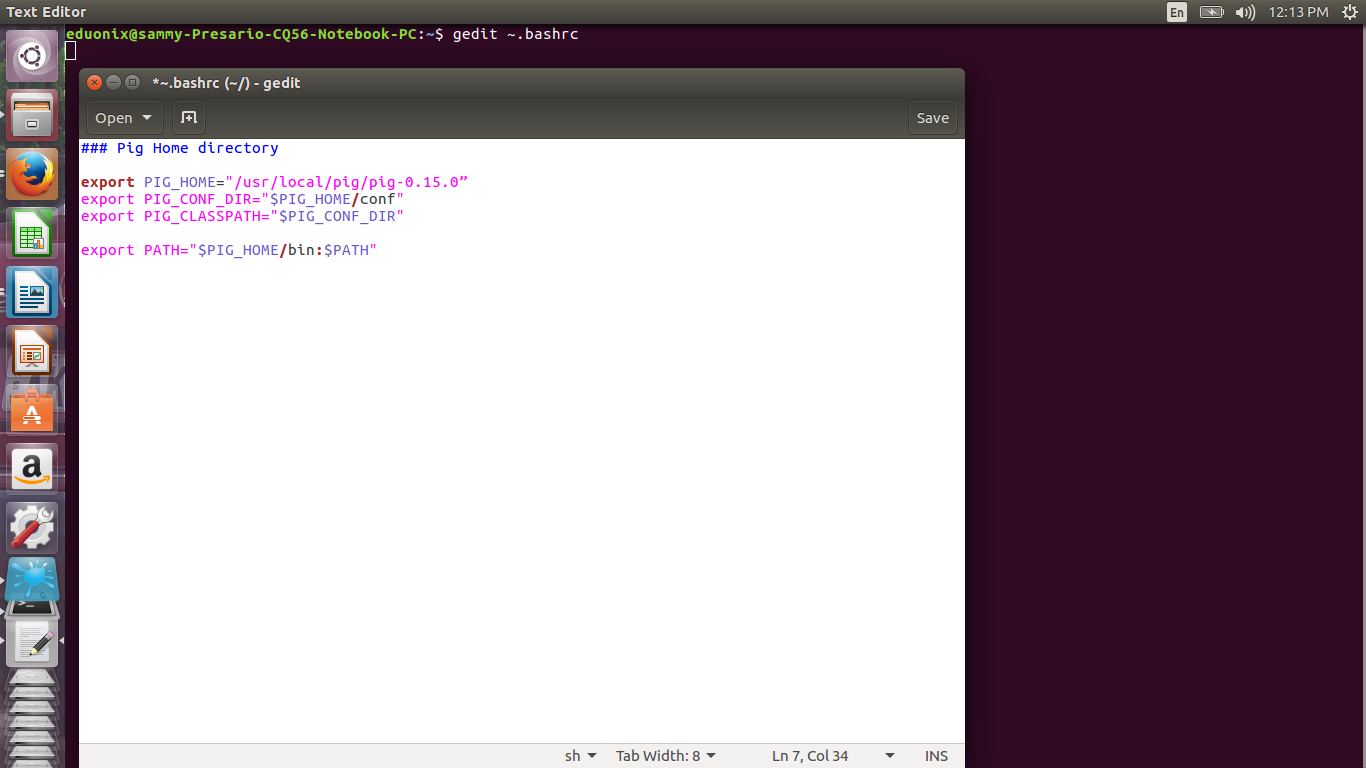
Save .bashrc and reload it by running source ~.bashrc

Run pig -h at the terminal to check Pig has been correctly installed.
Within Hadoop Pig can run in local mode or mapreduce mode. Local mode is suited for processing small amounts of data. Local mode does not require Hadoop and hdfs. You choose to use local mode by setting -x option to local. Mapreduce mode is chosen by specifying -x option to mapreduce. In this mode a Hadoop installation and hdfs are required. When -x option is not specified Pig uses mapreduce by default. Pig programs can be run in local or mapreduce mode in one of three ways. These are grunt, script or embedded.
When using a script you specify a script.pig file that contains commands. Then you use the command pig script.pig to run the commands. Grunt provides an interactive way of running pig commands using a shell. When Pig does not get any file to run it starts Grunt shell. Pig scripts can also be run from Grunt with use of run and exec. In embedded mode Pig programs are run in java using PigServer class.
To run pig in an interactive mode using local mode run this command pig -x local at the terminal. This enables running pig commands
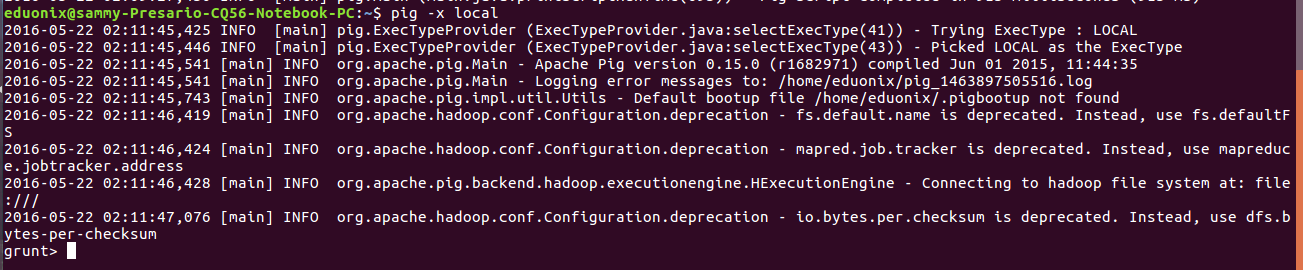
To run pig in mapreduce mode type pig at the terminal.
In the hive tutorial we demonstrated how to load data from hdfs into Hive. In this tutorial loading cars.csv data into Pig will be demonstrated. The load command is used to bring in data into pig from hdfs. We specify the hdfs path of the file to be loaded and the schema that we will load data into. The data was loaded into hdfs using the commands below. Download the data from http://perso.telecom-paristech.fr/~eagan/class/as2013/inf229/data/cars.csv.
cd ~/Downloads head cars.csv sed -i id cars.csv hadoop fs -put cars.csv /usr/hadoop/cars.csv
CARS = LOAD ‘/usr/hadoop/cars.csv’ USING PigStorage(‘,’) AS ( Name:chararray, Miles_per_Gallon:float, Cylinders:int, Displacement:int, Horsepower:int, Weight_in_lbs:int, Acceleration:float, Year:chararray, Origin:chararray);
In the above expression the part to the left of = is called an alias or relation. The PigStorage(‘,’) part specifies that fields in our data are separated by a comma. The part after AS specifies the schema that will be used in storing the data. The above statement does not initiate any mapreduce jobs. The jobs are initiated when using STORE or DUMP command.
DESCRIBE CARS;

STORE CARS INTO ‘/usr/hadoop/CARS’ USING PigStorage(‘,’);
The above example shows how to load and save data using the grunt shell. This is just one way Pig can be run. Another way of running pig is using scripts. Scrips in Pig follow a specific format in which data is read in, operated on and saved back in the file system. Pig has simple data types like int, float, chararray, long, double and bytearray. From these simple data types one is able to construct concepts like tuples, bags and maps. Arithmetic operators possible with simple data types are: add, subtract, multiply, divide, and module.
In the Pig Latin language statements operate on relations and are therefore called relational operators. The LOAD and STORE operators that load and store data respectively have been explained in the previous section. The DUMP operator is used to show the contents of a relation on the screen which is useful for testing and debugging. The ORDER operator enables a relation to be sorted The FILTER statement uses a condition to select data. The JOIN operator uses an inner or outer join to join two relations. The FOREACH operator is used to iterate tuples and generate transformations. The SPLIT operator is used to partition a relation into two or more. The GROUP operator is used to group data in one or more relations. These are some of the commonly used operators in Pig Latin. For an exhaustive discussion of operators available refer to the Pig documentation available online.
This tutorial has introduced Pig and explained how it fits in the Hadoop ecosystem. Installation of Pig has been demonstrated. The two modes in which Pig can run have been explained. Pig has three ways in which programs can be run and these have been explained. Commonly used operators in Pig have been highlighted and loading and storing of data has been demonstrated.


{kind=link}