
In our previous guides, we saw how to run wordcount MapReduce program on a single node Hadoop cluster. Now we will understand the MapReduce program in detail with the help of wordcount MapReduce program.
MapReduce is a system for parallel processing of large data sets. MapReduce reduces the data into results and creates a summary of the data. A MapReduce program has two parts – mapper and reducer. After the mapper finishes its work then only reducer’s start.
Mapper: It maps input key/value pairs to a set of intermediate key/value pairs.
Reducer: It reduces a set of intermediate values which share a key to a smaller set of values.
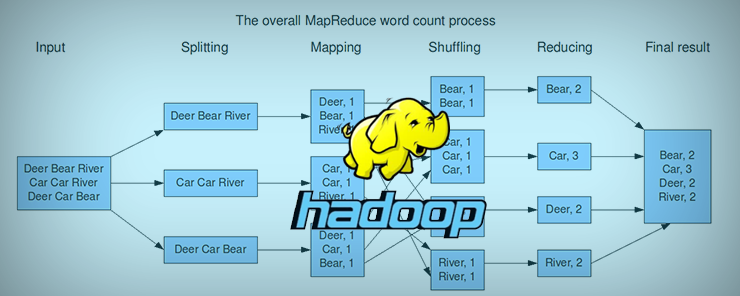
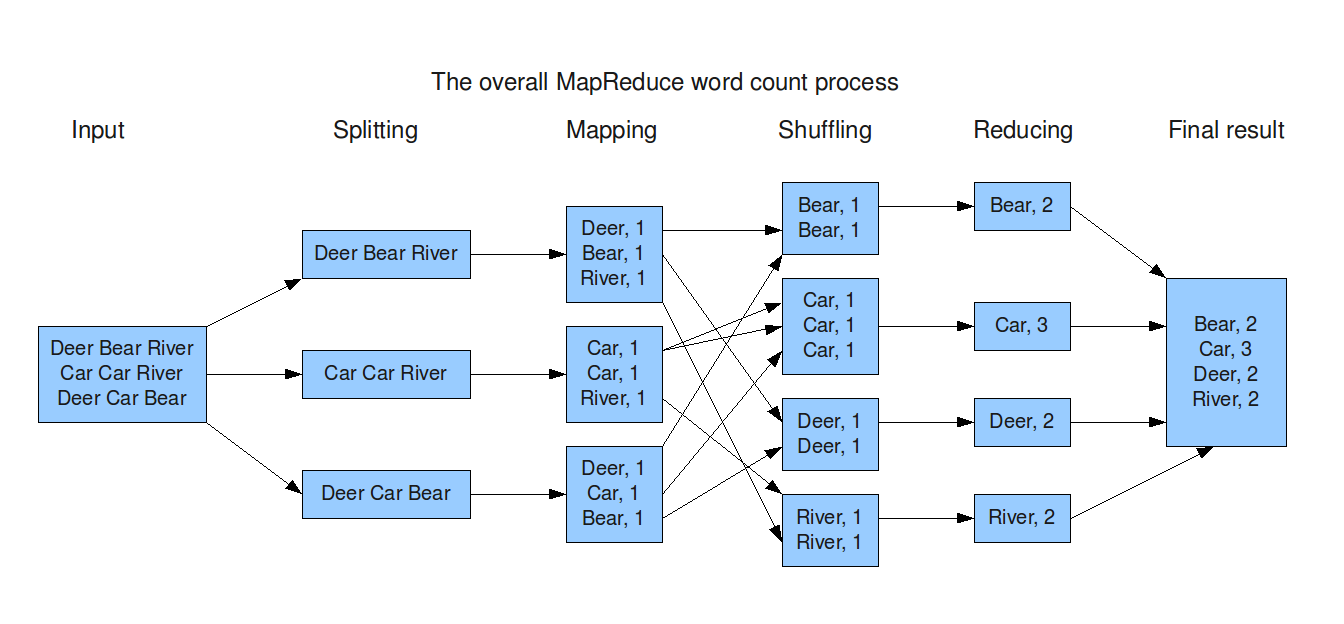
Basically, in the wordcount MapReduce program, we provide input file(s) – any text file, as input. When the MapReduce program starts, below are the processes it goes through:
Splitting: It splits the each line in the input file into words.
Mapping: It forms a key value pair, where word is the key and 1 is the value assigned to each key.
Shuffling: Common key value pairs get grouped together.
Reducing: The values of similar keys are added together.
From the below snapshot you can see the complete MapReduce workflow.
Let us see the practical implementation of wordcount program now. In a common MapReduce process, two methods do the major job, they are map and reduce methods. There is main method also in which we define all the job configurations. You can keep map, reduce and main methods in separate class files also, here I am taking in one class file.
The data types provided here are Hadoop specific data types designed for operational efficiency suited for massive parallel and lightning fast read write operations. All these data types are based out of java data types itself, for example LongWritable is the equivalent for long in java, IntWritable for int and Text for String. The input to mapper is a single line, then key value pair is formed and passed to reducer where the aggregation happens.
import java.io.IOException;
import java.util.StringTokenizer;
//These are the hadoop packages used in this mapreduce program
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class WordCount {
//Mapper
//<LongWritable,Text,Text,IntWritable> are hadoop specific data types
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable>{
/**
* @method map
* <p>This method takes the input as text data type and splits the input into words
* and makes key value pair. This key value pair is passed to reducer.
* @method_arguments key, value, output, reporter
* @return void
*/
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
//Converting the record (single line) to String and storing it in a String variable line
String line = value.toString();
//StringTokenizer is breaking the record (line) into words
StringTokenizer tokenizer = new StringTokenizer(line);
//Iterating through all the words available in a line and forming the key value pair
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
//Sending key value pairs to output collector where each key has value 1,
//which in turn passes the same to reducer
context.write(value, new IntWritable(1));
}
}
}
//Reducer
Public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
/**
* @method reduce
* <p>This method takes the input as key and list of values pair from mapper, it does
* aggregation based on keys and produces the final output.
* @method_arguments key, values, output, reporter
* @return void
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException {
//Defining a local variable sum of type int
int sum=0;
/*
* Iterates through all the values available with a key and adds them together
* and give the final result as the key and sum of its values.
*/
for(IntWritable x: values)
{
//Adding value of similar keys
sum+=x.get();
}
//Dumping the output
context.write(key, new IntWritable(sum));
}
}
//Driver
/**
* @method main
* <p>This method is used for setting all the configuration properties.
* It acts as a driver for map reduce code.
* @return void
* @method_arguments args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//Creating a job and configuration object and assigning a job name for identification //purposes
Configuration conf= new Configuration();
Job job = new Job(conf,"wordcount");
job.setJarByClass(WordCount.class);
//Providing the mapper and reducer class names
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//Setting configuration object with the Data Type of output Key and Value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//Setting format of input and output
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Deleting the output path automatically from hdfs if it already exists
outputPath.getFileSystem(conf).delete(outputPath);
//Exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}


{kind=link}