
As in the previous guide we configured Hadoop cluster with YARN on Amazon EC2 instance. Now we will run a simple MapReduce Program on Hadoop cluster.
YARN has two daemons: ResourceManager and NodeManager
ResourceManager is the master that arbitrates all the available cluster resources and thus helps manage the distributed applications running on the YARN system. It works together with the per-node NodeManagers and the per-application ApplicationMasters. In YARN, the ResourceManager is primarily limited to scheduling i.e. only arbitrating available resources in the system among the competing applications and not concerning itself with per-application state management.
The NodeManager is YARN’s per-node agent, and takes care of the individual compute nodes in a Hadoop cluster. This includes keeping up-to date with the ResourceManager overseeing containers life-cycle management; monitoring resource usage (memory, CPU) of individual containers, tracking node-health, log’s management and auxiliary services which may be exploited by different YARN applications.
Before we run an example, check whether your cluster is up or not by running jps, if not, please start all the hadoop daemons first.
Command: jps
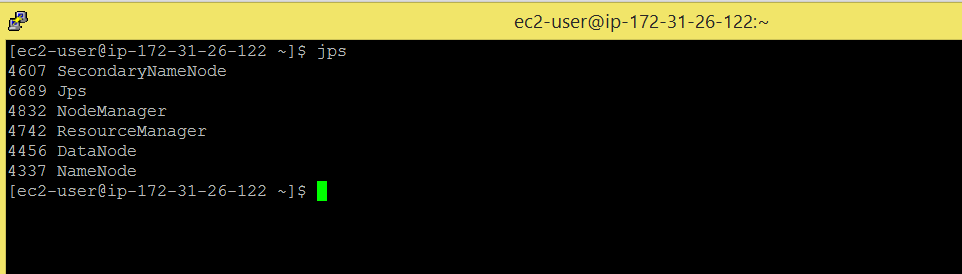
My cluster here is up and running. Also set yarn.application.classpath parameter in yarn-site.xml file, as shown below.
Command: vi hadoop-2.6.0/etc/hadoop/yarn-site.xml
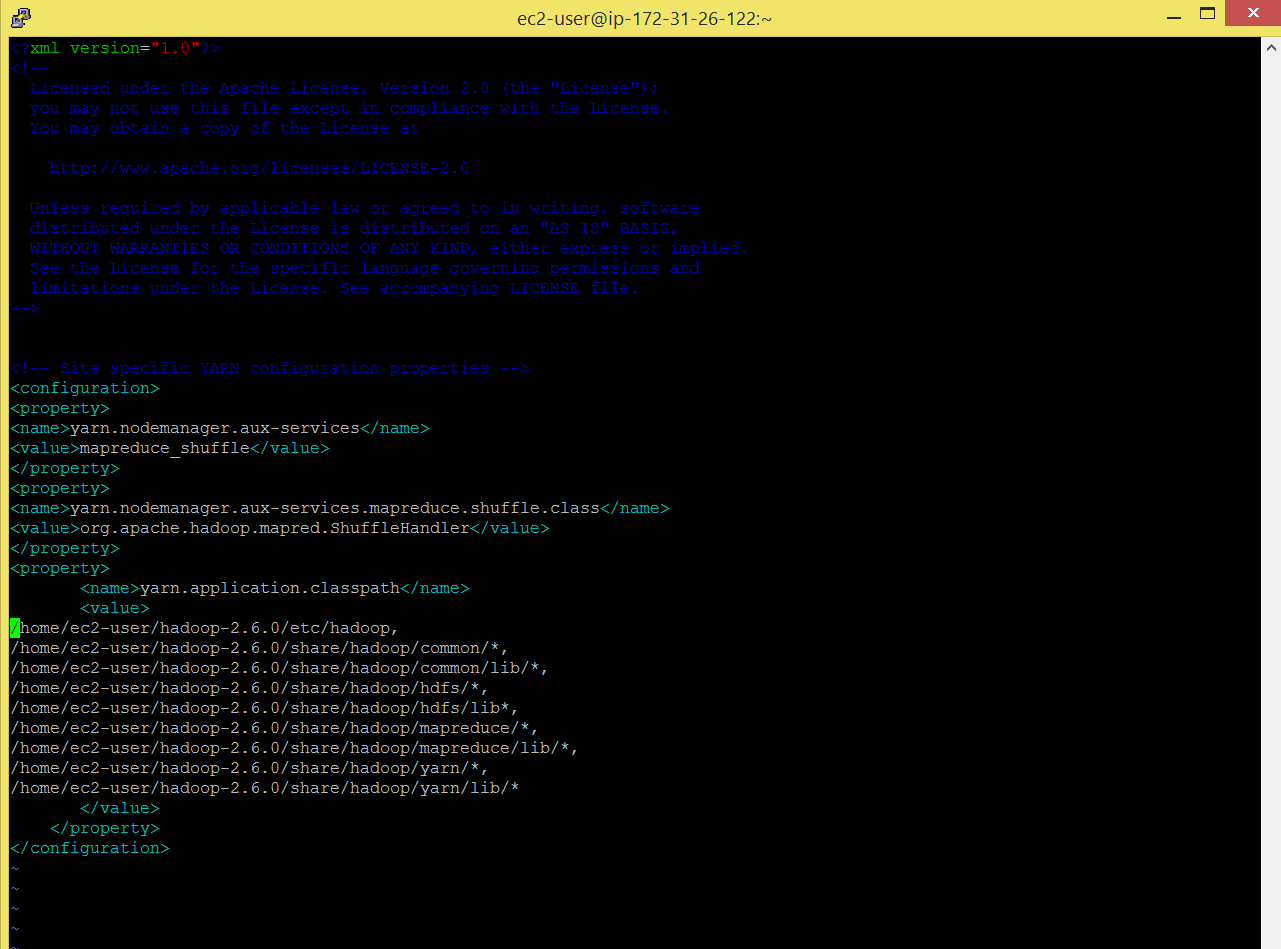
————————————————————————————————————————————–
/home/ec2-user/hadoop-2.6.0/etc/hadoop, /home/ec2-user/hadoop-2.6.0/share/hadoop/common/*, /home/ec2-user/hadoop-2.6.0/share/hadoop/common/lib/*, /home/ec2-user/hadoop-2.6.0/share/hadoop/hdfs/*, /home/ec2-user/hadoop-2.6.0/share/hadoop/hdfs/lib*, /home/ec2-user/hadoop-2.6.0/share/hadoop/mapreduce/*, /home/ec2-user/hadoop-2.6.0/share/hadoop/mapreduce/lib/*, /home/ec2-user/hadoop-2.6.0/share/hadoop/yarn/*, /home/ec2-user/hadoop-2.6.0/share/hadoop/yarn/lib/*
————————————————————————————————————————————–
Command: cd hadoop-2.6.0/share/hadoop/
Command: ls

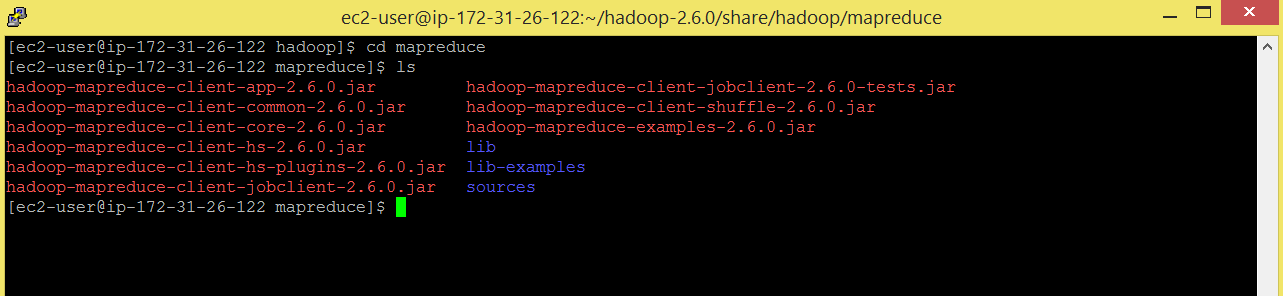
Command: cd mapreduce
Command: ls
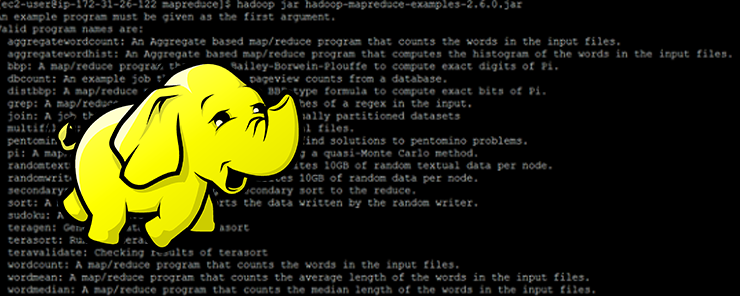
Command: hadoop jar hadoop-mapreduce-examples-2.6.0.jar
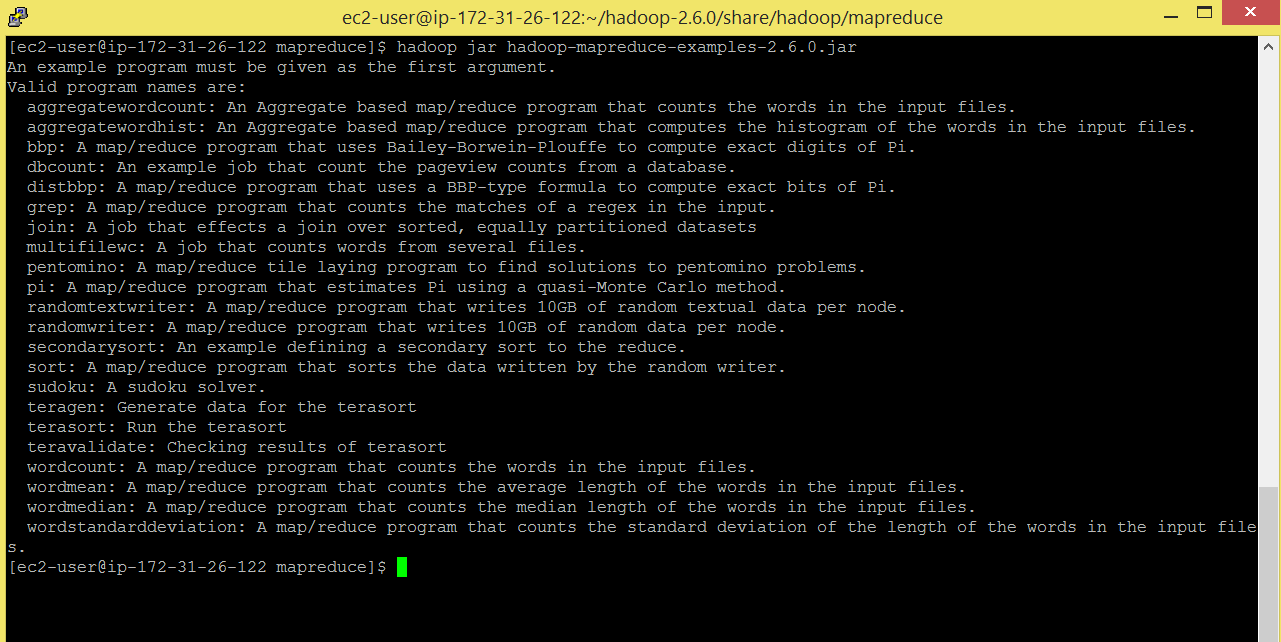
There are lot of mapreduce programs present in hadoop-example jar. We will be running wordcount program. As mentioned above, this program counts the number of times (frequency) a word has appeared.
I am creating a sample input file ‘words’
Command: cd
Command: vi words

Send the input file onto HDFS.
Command: hdfs-dfs -put words hdfs:/
Command: hdfs dfs -ls hdfs:/

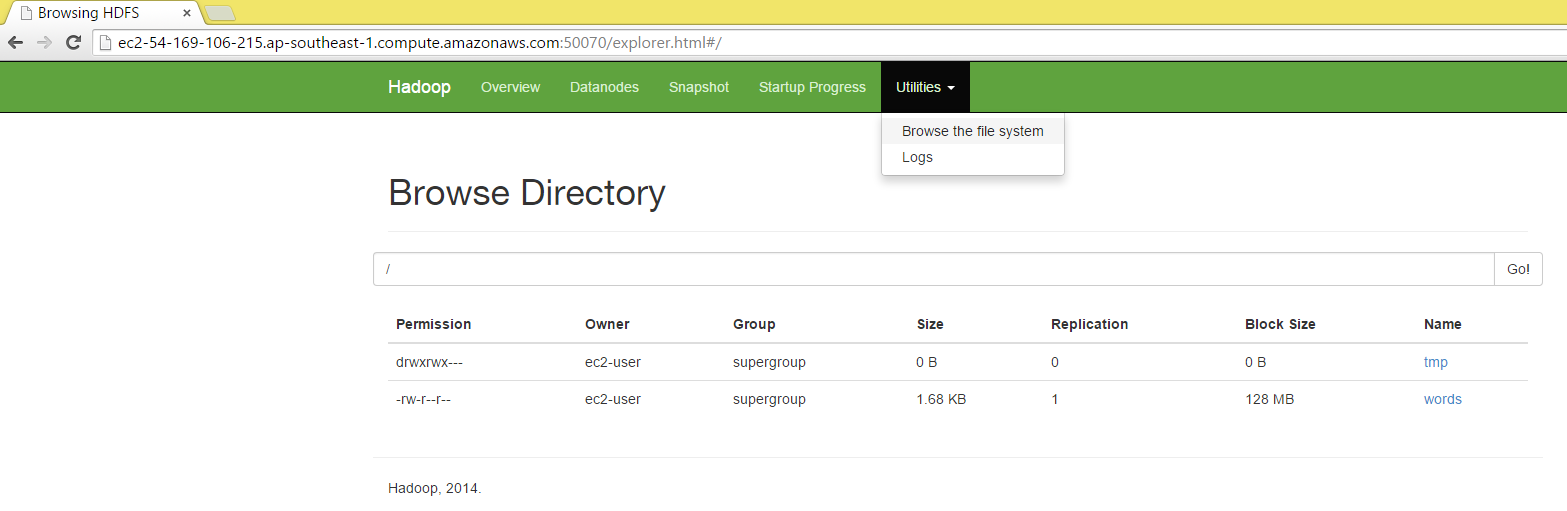
Also check by using browser.
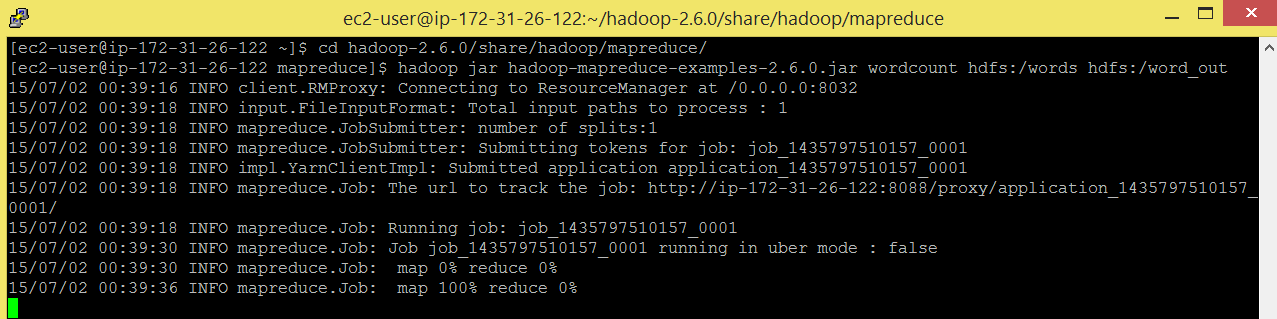
Run below commands to run mapreduce wordcount program.
Command: cd hadoop-2.6.0/share/hadoop/mapreduce
Command: hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount hdfs:/words hdfs:/ word_out

You can see in below snapshot that ResourceManager is running on 8032.
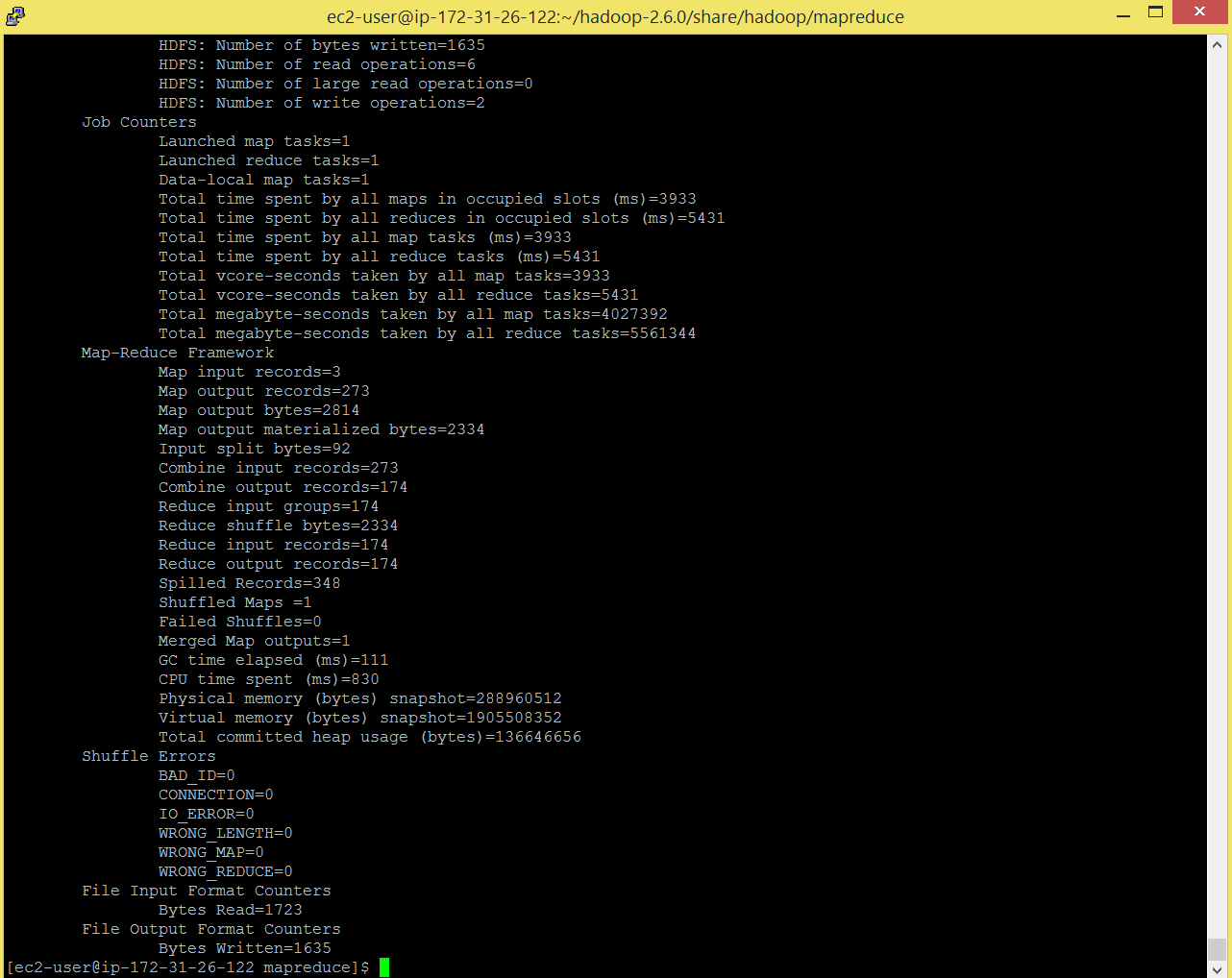
After completion of job , checkout the output.
Command: hadoop dfs -cat /word_out/part-r-00000
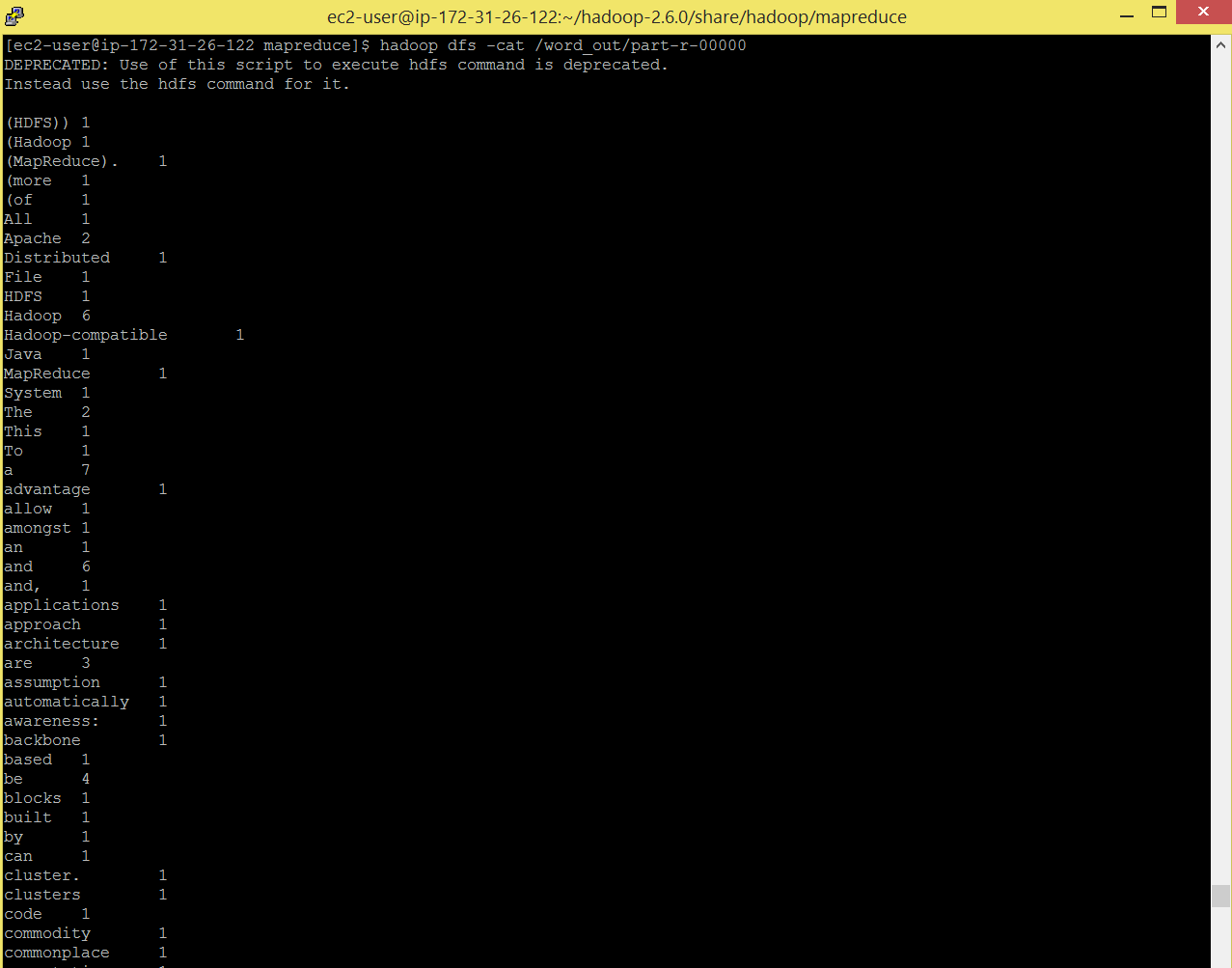
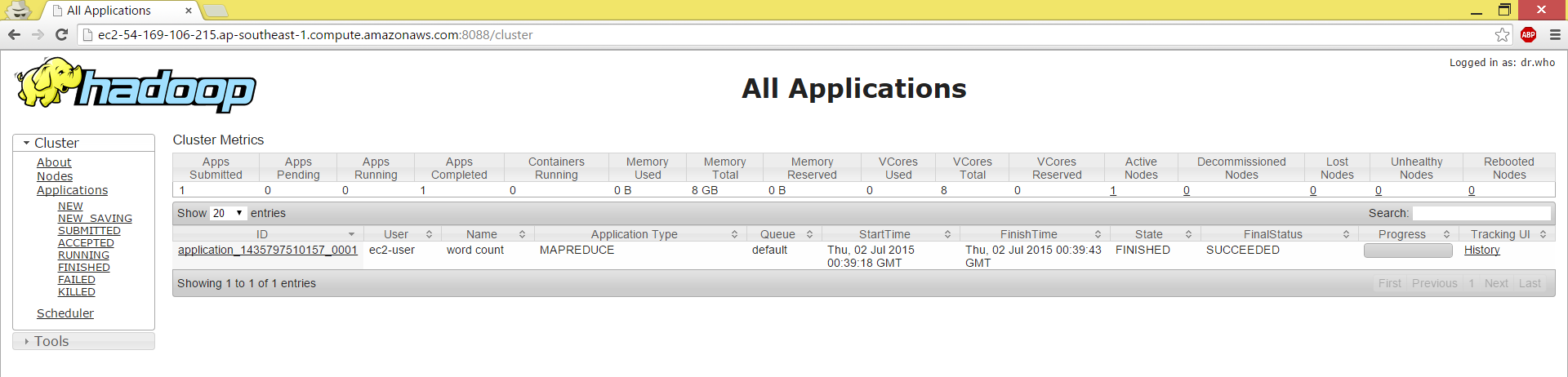
Also browse: , here you will see you application has succeeded.


{kind=link}