

Getting started with data science
The rapid adoption of big data and data science has led to many of the developers and researchers moving towards machine learning and that is benefiting the market and attracting many data mining experts also. The prime focus on machine learning is to extract useful and tangible business insight and futuristic behavior towards market and various predictions for better output. There are many predictive algorithms that are used within machine learning (apart from algorithms used for data mining). Some of them are random forest and a well-known neural network algorithm that calculates number of users appearing for a particular domain and based on those analysis the data scientist conclude for some future predictions.
Sometimes data science is also correlated with feature engineering (a process of transforming very large raw data into a matrix). The most important and salient concern for data science is to make best efforts to make machine learning and Hadoop as a best market place for gaining an insight into this technology and increasing opportunities for business leaders and researchers as well.
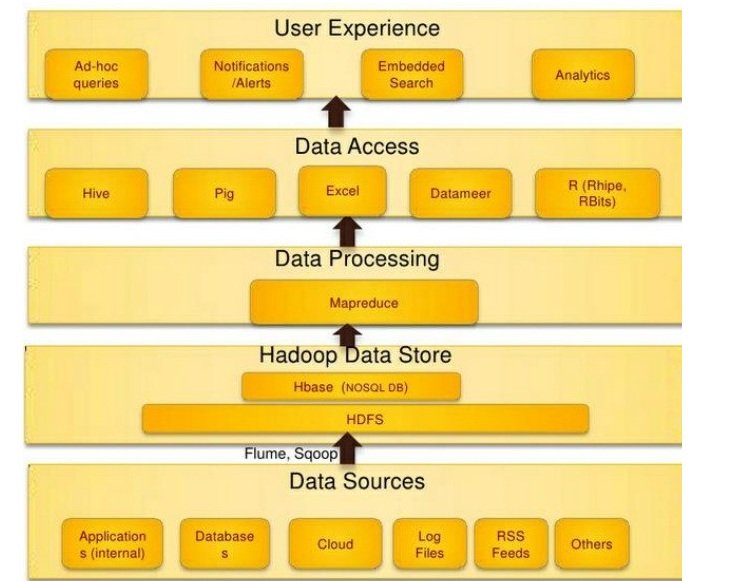
Hadoop and data science
Hadoop is the most suitable tool and best platform for data scientist and researchers that is pretty much handy and has lots of scope to incorporate various other technologies for various algorithms (specially focusing on raw and unstructured data). Hadoop is enabled with the technologies like YARN (yet another resource negotiator) and is the ideal platform for extracting and transforming useful information out of raw and massive unstructured data (Terabytes and Petabytes of data). After the data extraction we can easily apply various machine learning algorithms on that data. Hadoop framework has a wide variety of support for machine learning tools like apache mahout (specially designed for machine learning) whereas the resultant data can be further moved to some other analysis tools like R and has also the flexibility of writing the Hadoop scripts for machine learning in languages like python.
Hadoop, machine learning and things to watch out for!
Hadoop’s contribution for machine learning has given rise to apache mahout whose primary aim is to build a scalable and robust machine learning application. The main components of machine learning are Spark with scala (also known as h2o application) and well known Hadoop map reduce application. Apache mahout applications include many implementations for building many speedy frameworks (speed increase as much as 10x).
Useful tips for making Hadoop suitable for data scientist
Hadoop is a very useful platform for machine learning and many of the data scientists makes it to visualize and access algorithms to make it a declarative and promising advancement using some useful data visualization techniques.
Data analyst vs data scientist
Hadoop is very much useful for making data queries and most of the data scientist uses the Analytical queries to perform analysis on huge unstructured data. In spite of the fact that these queries are very much useful for many of the data scientist but it is still making a point to overcome some issues. Counting the queries after running the SQL statements often needs to reconsider the things so as to make the process lot easier. Still expressing the ideas with SQL analytical queries is a bit difficult as compared to traditional SQL queries, so it is still a challenging task for many of the data scientists.
Make sure to estimate financial risks and possibilities
There is a risk factor in each and every case of data analysis tools, when the data is analyzed with these tools then there is a risk of theft of data and this data loss might cause heavy financial loss and sometimes crisis situation for companies. According to financial statistics VAR (value at risk) factor makes a manageable diversification amongst the regulation. For VAR model mainly two approaches are used that is variance and covariance that is the easiest approach for analytical solutions for simplifying the solutions and assumptions. Another one is Monte Carlo simulation method that is used to define between market conditions and calculating the portfolio loss for each of the trial.

Data scientist must be dynamic
In order to make Hadoop better place for data scientist one must be dynamic enough to make an adaptability level up to an extent in order to be capable of being researching as well as developing a web application. Researchers should always make sure that they must work in a flexible environment in order to explain results and share intermediate data.
Data Scientist still under wrap
Many of the scientist and mathematicians have affection towards python programming language in terms of working with many of data and automation tools (many of the tools have a support for python programming language including python). Cloud-era has released its new project known as lbis that is also an open source project under apache foundation that has a data analysis framework meant to spawn a gap amongst data scientist and data analysis tools. The initial support for lbis was to provide end to end python experience for developers and data scientist as well. It has comprehensive capabilities for simplified ETL and data wrangling techniques. Apache spark has also a wide scope for many of the data scientists that are involved in real time analysis and has MLIB (the most popular machine learning library).
Conclusion
In this article we have gained an expertise knowledge for how Hadoop and some other Hadoop supportive platforms can be useful for data scientist, though data scientist has a wide ground of options related to languages and in terms of platforms, but this articles focuses on making Hadoop a better place for data scientist, we have also discussed about some dedicated tools and libraries for developed by apache foundation. Such dedicated libraries are pretty useful for many of the data scientists and most of them prefer data friendly languages like python, this article also calculates some financial risks that can harness the possibilities of not being a good analytical and logical scientist in order to have an in depth analysis.


{kind=link}