

Role of hadoop in making business intelligence strategies
From the past decade, there are many technologies and different number of data structure methods (stack, heap memory and binary trees) for increasing the capabilities and performance of business intelligence based solutions and systems as well. These services are sometimes self-oriented and deliver various levels of capabilities (depending on service level agreement also sometimes known as SLA). For many of the developers and back end users hadoop is equivalent to big data and business intelligence and saying that is hadoop compatible with Big Insights or cloudera’s version of Hadoop for BI approaches.
Most of the decision making systems such as online analytical processing are used to transform and migrate the data to an operational data store and enhancing broad consumption of many business intelligence system. More business rules that are incorporated into the data management systems, the less time it will take for a developer to model between analyzed data and Business intelligence predicates.
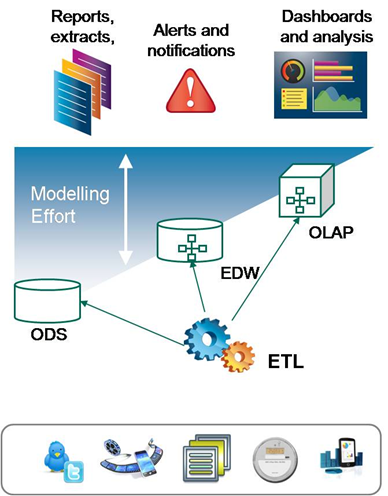
Using hadoop as a business intelligence tool
Hadoop is a storage data that is used for business intelligence and most of the time hadoop distributed file system is used for storing data and transactional processing for managing data in its raw state. One of the advantage of this is that map reduce programming is used for processing with hadoop for business transactional analysis that deliver a great performance and that too supporting specialized query optimization that accelerates the code performance and execution time. Flaws in using hadoop is its slow processing performance and limiting reporting capabilities for business intelligence applications just because of its lack of real time transactional tools (batch processing analysis, where a job is submitted first and then analyzed). Though hadoop is good for interactive capabilities that may be used in specific areas and performance improvement for general ad hoc queries, it is still a preferred choice for many of the data architects and data scientists.
Implementing and usage of hadoop data platform for business intelligence
Step 1: Initialization of data and importing the data – the data sets can be any unstructured data that is used for analyzing as a use case (real testing as well). We can have a sample test case as NYSE data (New York Stock Exchange data). The files can be in a format of an excel sheet or can have a csv format (comma separated values).
Step 2: Dumping and loading the data into hadoop distributed file system – this is also known as staging the data for analysis. We can stage the data using specialized cloud storage (we can also use hd insights service, for example azure blob storage). For the testing purpose, the environment used can be a local environment like cloudera’s distribution of hadoop or Hortonworks sandbox to implement the experiment. In this example, ambari data staging methodology is used.
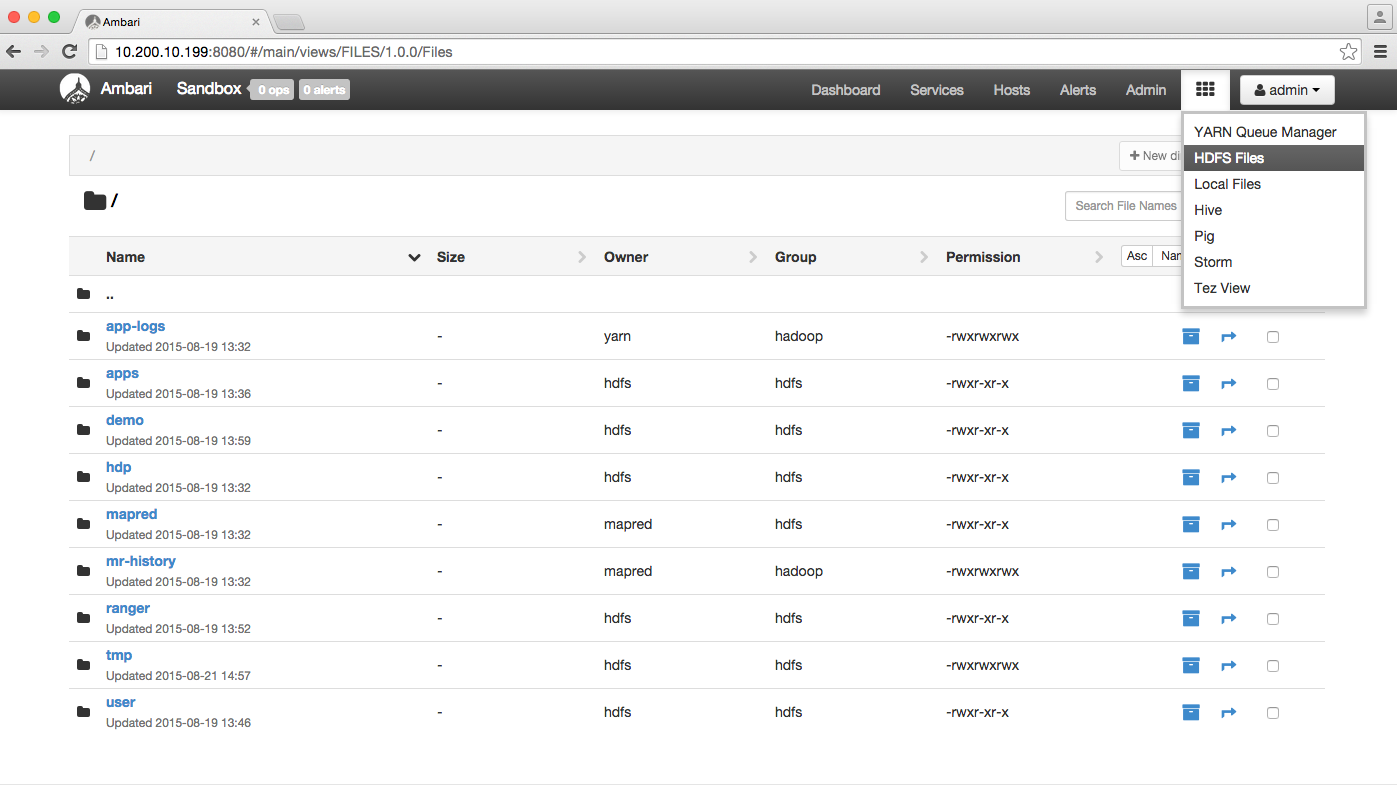
Step 3: Create a new folder and unzip some of the files used for analysis (local zip directory like NYSE datasets). Other alternative techniques can also be used for unzipping the data and dumping into a location (using hadoop command line arguments).
Step 4: Logging into local host using ssh (secure socket shell) for a secure remote session to other machine by typing the command ssh [email protected] (using root privileges for full admin rights)
Step 5: After logging into account, try to upload the unzipped files using hadoop command line interface
hadoop fs –put nyse_file0 /users/admin/data
After dumping the files, change the file permissions
su hdfs (for changing user to hdfs super user) and change the mode to
hdfs dfs -777 /users/admin/data (this will give full read write and execute permissions to all the users that log in)

Step 6: Using hive to execute the business intelligence query for business analysis
Before using the data that is loaded into HDFS, we need to create a hive schema and for that we need to execute some DDL queries (data definition language) just like relational databases.
create external table price_data (stock_exchange string, symbol string, trade_date string,
open float, high float, low float, close float, volume int, adj_close float)
row format delimited
fields terminated by ','
stored as textfile
location '/users/admin/data /nyse_prices';
With this query we will be able to create a schema for loading the comma separated file
Step 7: Aggregating the stocks data for knowledge extraction and the output of the previous results is the input of aggregation query
create table yearly_aggregates (symbol string, year string, high float, low float, average_close float, total_dividends float) row format delimited fields terminated by ',' stored as textfile location '/users/admin/data /stock_aggregates';
This query is pretty much clear as each and every statement is executed for data aggregation (aggregating data from previous queries)
Step 8: Running the query for testing the table and the output will be a single line record (knowledge extraction of various queries for business intelligence).
Step 9: Moving back the records from hive query (results obtained from hive query stored as a part file and links of records stored in hive metastore). This step will consume and shape the data in a csv or excel format for this we need to open a blank excel sheet and go to the power query tab as depicted in the image
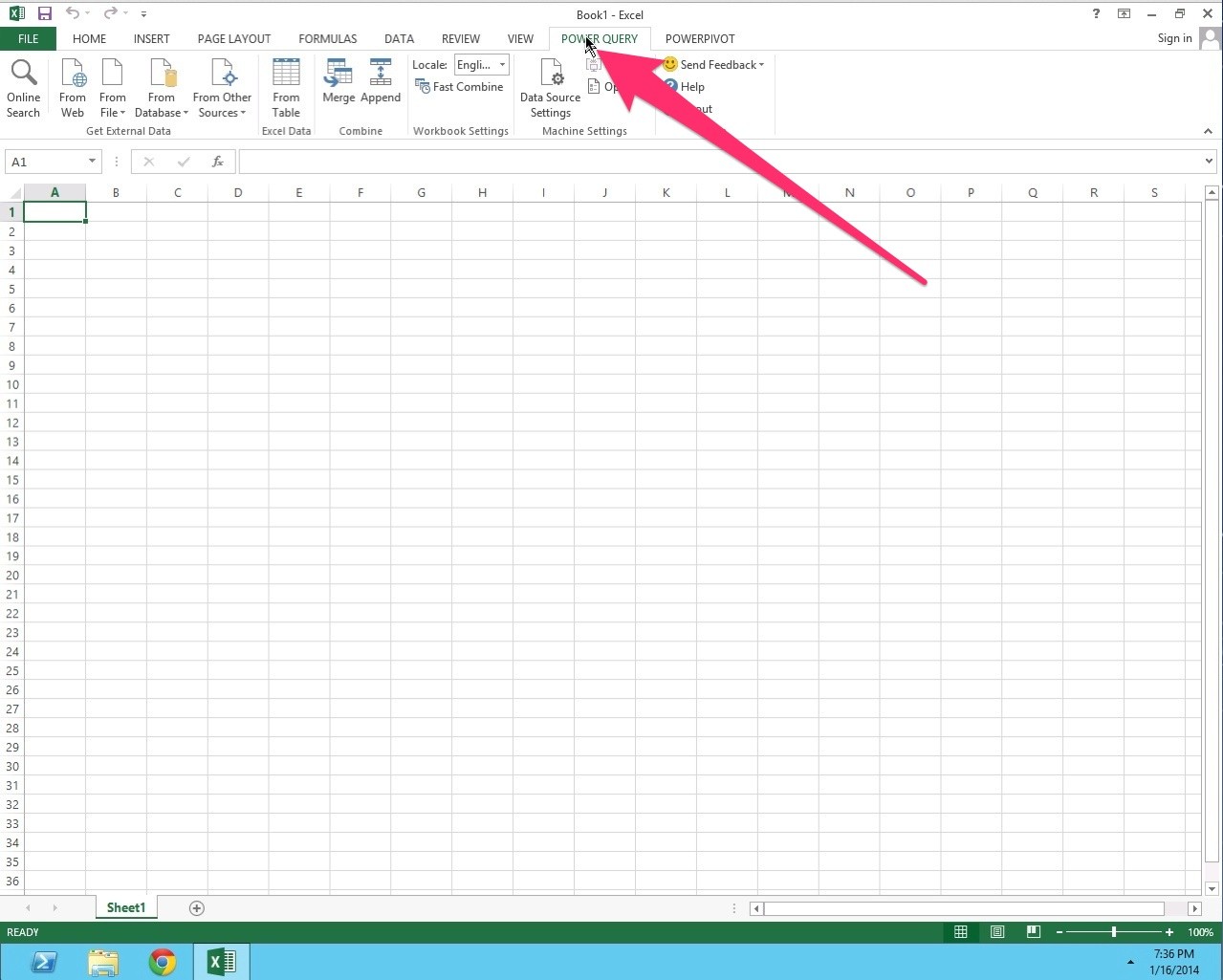
Step 10: Click the “from other sources” tab to import the data from hadoop distributed file system and enter the name and IP address of the server (localhost in this case) to import the data. With this approach, we can use hadoop for business intelligence that is also helpful in predictive analysis for gaining an expertise in business solutions.
Conclusion
The extensive use of hadoop and big data has resulted its popularity over other technologies, making hadoop highly recommended for business intelligence. In this article, we discussed the challenges and advantages faced during the phase of implementing and analyzing real time data with the use of this framework. The future of business intelligence lies among the dominating technologies such as hadoop and spark for batch and real time processing in order to perform the optimum and making maximum out of business intelligence algorithms and machine learning as well.


{kind=link}