
")
The capability to manipulate text strings is of great importance. In our everyday’s work, we need to search text, extract parts of text, and sort text. Linux shell has a number of useful tools that help us do various text processing tasks. In this article, we are going to investigate these tools. When needed, we will illustrate our talk with examples. So, here we go.
head and tail
The head and tail commands are text-processing tools that achieve two opposite tasks. The head command outputs the first part of files, while the tail command outputs the last part of files. They have almost similar syntaxes:
head –n k FILE
This will retrieve the first k lines in a file.
tail –n k FILE
This will retrieve the last k lines in a file.
Another way to write the above commands is to eliminate the -n, and use –k, where k is the number of lines to retrieve.
head –k FILE tail –k FILE
If the number of lines to retrieve is not specified, both commands default to get 10 lines.
Example
This will get the first 5 lines of the /etc/passwd file

The following will achieve the same result:
3
Example
This will get the last 10 lines in the /etc/passwd file:

The following form has the same result:

Example
We need to extract the line number 136 from the /etc/httpd/conf/httpd.conf file, how could we achieve this?
This can be done using a mix of head and tail effects. Watch this:
[root@server01 ~]# head -136 /etc/httpd/conf/httpd.conf| tail -1 Listen 80
The above line first uses the head command to retrieve the first 136 lines. The required line is the last in this output. So, the extracted 136 lines are then piped to be the input to the tail command that extracts the last (one) line, which is the required line (Line number 136).
Quite useful, yet easy, isn’t it?!
The Word Count wc Command
The wc command prints line, word, and byte counts for each file. It can perform such statistics for files or output from other commands passed to it through pipe.
Example

Where 13 is the number of lines in the file (including the empty lines), and
70 is the number of words in the file, and
458 is the number of characters.
sort and uniq
The sort command sorts lines of text files. Like the cat command, it can concatenate multiple files, but it prints the sorted result of concatenation.
Example
The following command prints the /etc/passwd sorted alphabetically.

In files like the above (wherein lines consist of equal numbers of fields separated by a delimiter or separator like white spaces, tabs, commas, colons, etc.) the sort command can also sort according to a specific field (column). This uses the following syntax:
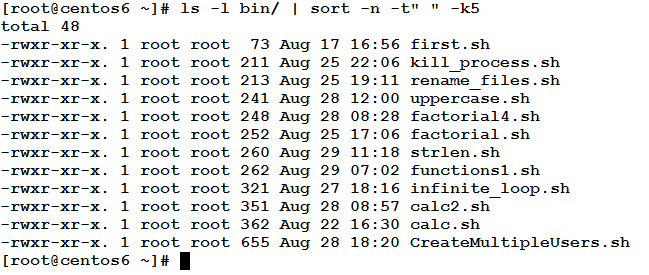
sort –t field_seprator –k field_number [–r] [-n]
Where:
field_separator is the delimiter used to separate fields.
field_number is the number of the column to sort according to it.
-r (optional) means reverse order, and
-n performs a numerical sort.
Example
Consider we need to sort the files in a directory according to their size (from smaller to larger). How could we achieve this?
In the long listing below, the file size is the represented by the fifth column.
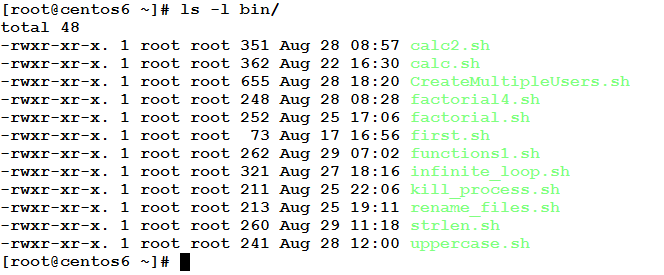
To sort this output according to the numeric value of the fifth field, use the following command:
The uniq command
If there is duplication in some lines, the uniq command can report or omit repeated lines. This command checks adjacent matching lines, and removes the repeated lines (keeping only one).
Example
Consider the following file that has some repeated lines.
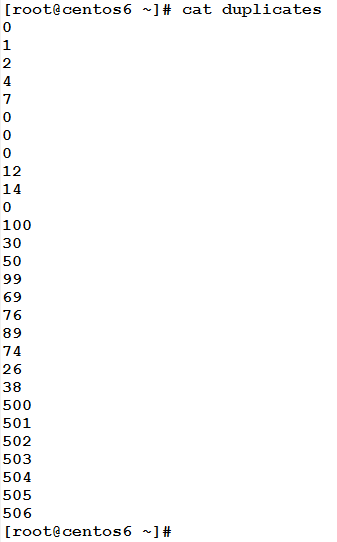
To remove such duplicates, use the uniq command:
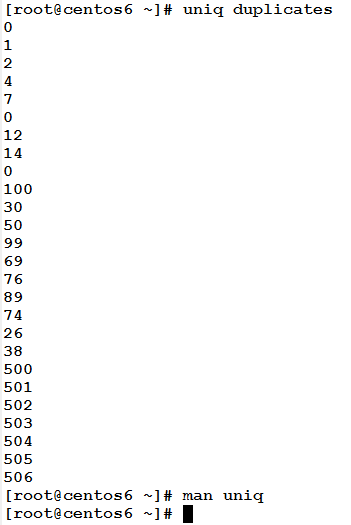
According to the definition, three adjacent zeros have become only single zero.
– Wait, there are still repeated lines!! Not all zeros have been removed.
Yes, that is true. Refer back to command usage; it removes “adjacent” repeated lines. To get a duplicates-free list, use a mix of sort and uniq commands together.

Mission cleared!! And all duplicates have been removed sir!!

expand and unexpand
The expand command converts tabs into white spaces, while unexpand does the opposite.
Example
Consider the following file that contains two fields separated by tab character.

The expand command will convert these tab separators into white spaces.
The tr Command
The tr command can translate (covert) or delete characters. It takes its input from the standard input, and sends its output to the standard output.
Example
In the above servers file, the following command will take the file as input, and delete any numeric characters, and then write the result to the standard output.
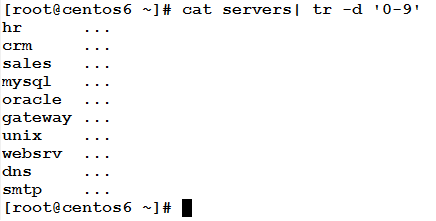
Where the –d option tells the command to delete (not to convert).
Example
Continuing with the servers file, the following command will convert any alphabetic character to uppercase.
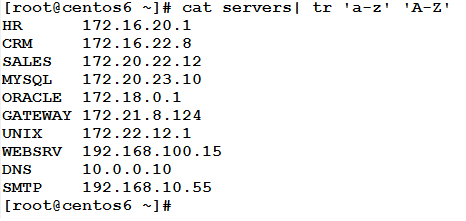
Example
In the servers file, the following command will convert the tab character into a white space, and will print the modified content to the standard output.
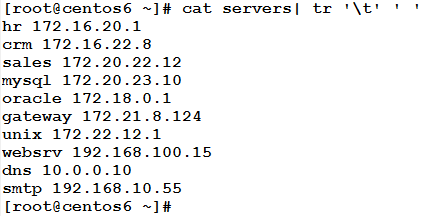
Where ‘\t’ represents the tab character.
Example
The following command will suppress adjacent repeated white spaces into a single white space.
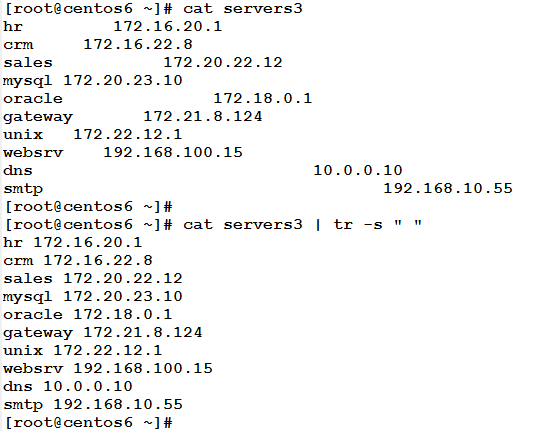
Where –s suppresses (squeezes) each input sequence of a repeated character into only single occurrence of this character.
The nl command
This commands prints the contents of file(s) to the standard output preceded by with line numbers. It has the same effect of using cat command with the –n option.
Example
The following command will print the /etc/filesystems file, with line numbers added at the beginning of each line.
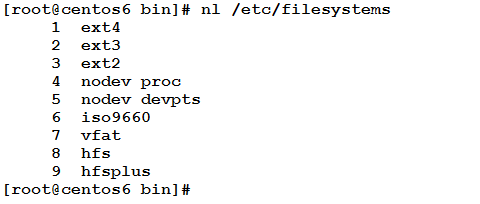
If two or more files are specified as input to the nl number, the numbering will continue, as if they were one file.

* * * * * *
In this article, we have learned how to sort contents of files, how to remove repeated lines, how to count lines, words, and characters in a file, how to translate (convert), and delete text, and how to print the contents of one or more files with line numbers.
That was part one of the articles on Text Processing Tools. So stay here and don’t go anywhere, part two is on the way. Just wait for it.


{kind=link}
Very useful post, thanks