
")
This is Part three, the last article in the series of Text Processing Tools.
The awk Language
Yes, you haven’t misread it. awk is a pattern scanning and processing language. It is a complete language itself. In this article, I will try to cover the basics of awk, and its common usages. Among its many uses, awk can be used as field extractor (acting as cut command), as basic calculator, and as a pattern matcher (acting as grep command). So, let’s investigate these uses, and illustrate our talk with examples. Here we go.
Using awk as cut
The awk command can extract columns (fields) out of a file (or output from another command piped to it as input). The syntax will be:
awk –F field_separator '{print $m$n}' FILE
Where:
field_separator is the character used as delimiter between fields. If none specified, white space is used as delimiter.
print is used to print selected fields to the standard output.
Fields are referred to by their positions. i.e. The first field in the input is $1, and the second is $2, etc.
Example
We need to print the list of files in a directory, with their sizes in bytes.
This can be done using the following command:

Example
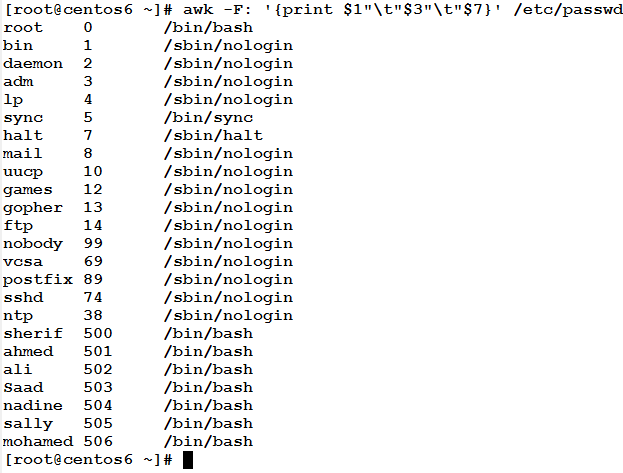
From the /etc/passwd file, extract the user name and its user ID, and its login shell.
Consider the following line from the file as a sample:
root:x:0:0:root:/root:/bin/bash
From this line, we can see that the required field are the first, the third, and the seventh. Based on this, the following command will print the required info to the standard output:
awk as Basic Calculator
In the above two examples, if the extracted fields contain numeric values, those values could be used as operands to arithmetic operations. For instance, in the example that lists files with their sizes in bytes, dividing such sizes by 1024 will give its equivalent in kilobytes.
Example
Given a file that has two columns, both containing numeric values:
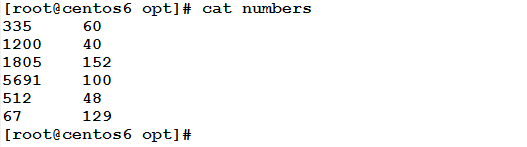
The following command will divide the first field by the second field:

awk as grep
awk can be used for pattern matching. This uses the following syntx:
awk '/PATTERN/' FILE
awk '/PATTERN/ {print}' FILE
Example
The following command will retrieve lines matching the string “nologin” from the /etc/passwd file:

The Stream Editor sed
sed is used to perform basic text transformations on an input stream (a file or input from a pipeline).
Using sed for String Substitution
The most popular usage for the sed command is to perform string substitutions. The syntax used for performing such operation:
sed –e 'startline,endline s/regexp/replacement/gi' FILE
Where:
startline is the first line to start matching and substitution from.
endline is the last line at which matching and substitution stops.
regexp is the string to look for.
replacement is the string to substitute the matched string.
g option mean global replacement.
i ignores case on search.
FILE is the input file to be searched.
Example
In this example, we are going to replace every occurrence of the word “bash” by its uppercase form “BASH”.

In the command above, note the following:
1,$ are the line numbers marking both ends of the range of lines to be scanned and processed. 1 means the first line, while $ denotes the last number in the file (input stream). Instead, we could use for example 3,20 to limit the sed work between the third and the twentieth lines.

Using sed to Delete Matched Strings
In the above substitution syntax, if the replacement part was left empty, the matched text will be substituted with nothing; i.e. deleted. So, deletion is a special case of the substitution operation.
Example
The following command will print the contents of the /etc/sysconfig/selinux file, with all lines uncommented. Remember, a commented line in a script or configuration file is preceded by #.

In the above command, the regex (regular expression) search pattern used was ^#. This matches all lines starting with the hash character ‘#’. The replacement part is left empty. This simply replaces the matched pattern (# character at the beginning of a line) by nothing. So, all lines are printed to the standard output uncommented.
The yes Command (The Dangerous Guy)
The yes command repeatedly writes a line with specified string(s) to the standard output. This continues until the command is killed. If no strings specified to be printed, the y character is continuously printed instead.
If no string specified:
This command can be useful when we need to create a large-size text file. Redirecting the output of the command to a file will create a very fast growing file.
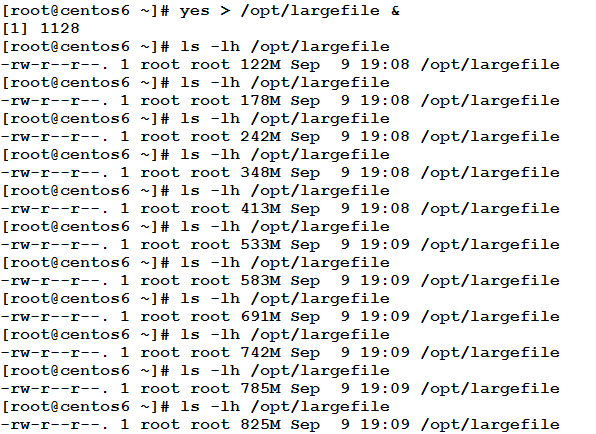
Warning
Use the yes command with care. A file to which the command output is redirected can grow in size to several Giga Bytes within two or three minutes. If you forget to kill the command in the right time, it can continue to grow until it fills up the file system.
column, and colrm
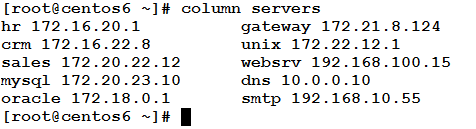
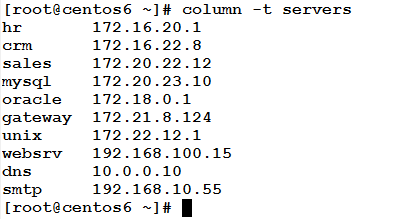
The column command formats its input into multiple columns. It writes the input in a table format to the standard output. This command is commonly used either with –t option or without options at all.
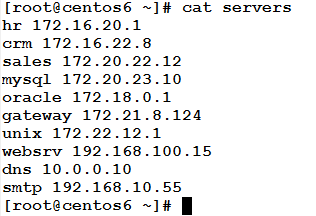
Example
Consider the following file:
Using column without options:
Using the command with –t option:
The colrm Command
This command removes selected columns of characters from a file, and writes the result to the standard output.
Syntax:
colrm STARTCOL ENDCOL
Where:
STARTCOL is the column number from which the removal starts.
ENDCOL is the column number until which removal will continue.
Example
The following command will remove characters from the second to the tenth, from each line of the /etc/passwd file:

* * * * * *
That was the third and last part of the series of Text Processing Tools in Linux Shell. This topic is finished, but we are not done yet. So, stay here; there are more articles on the way to you.


{kind=link}