

If you aren’t a developer or a tech geek, you probably have never heard of TensorFlow. First introduced on 9th November, 2015 by Google, TensorFlow is an open-source library that is Python friendly and is used for numerical computations using data flow graphs. TensorFlow is a cross-platform system that can run on mobiles, Tensor Processing Units(TPUs) and embedded platforms. It is very fast and is built on the C++ platform. It works on both CPU and GPU cores. TensorFlow has been created to imbibe deep learning abilities to your machines. Deep learning is made possible through the use of multi-layer neural networks. Here we will explain how o use dataset in tensorflow.
TensorFlow has two major features that are essential and must be used – Estimators and Dataset. Estimators are used to create TensorFlow models. They come pre-loaded with many such models but you also have the option of creating custom models. Dataset is a practice that creates input pipelines. Benefits of using Dataset API are –
- It provides much more functionality than the previous API i.e. queue-based pipelines,
- It is cleaner and simpler &
- It is faster and easier to operate.
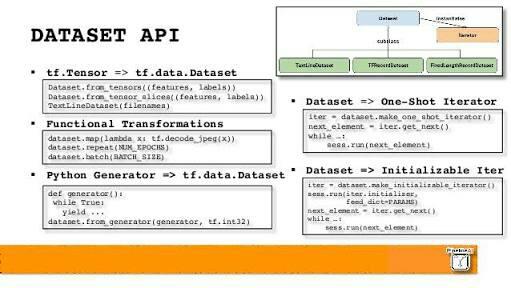
In this article, we will explain you how to use the dataset API efficiently and effectively. There are three important steps to be followed to use a dataset –
- Importing the data – We must create a dataset stance which is to be imported.
- Iterator creation – By using the created dataset, an iterator instance must be created that will iterate throughout the dataset.
- Feeding the model– Once the iterator has been created, the same can be used to feed the elements of the dataset to the model.
Importing the data
For using the dataset, it must be imported from a supported source. Following are the various sources available –
- From Tensors – The data can be imported from the tensors itself and initialized.
- From Generators – Dataset can be imported from various generators. They are especially beneficial for array of different element length.
- From CSV files – Dataset can be imported from an existing csv file.
- From NumPy – This is the most commonly used method of Importing a dataset. We can use one or more numpy arrays and pass it to TensorFlow for creating the dataset.
- From Placeholder – If the data inside the dataset needs to be dynamically changed, we should use a placeholder to create the dataset. It gives you an added flexibility.
How to create and use dataset?
You must define a source to begin with. Or else, if the data to be inserted is in the recommended TFRecord Format on your disk, you can construct a tf.data.TFRecordDataset. Once the dataset object is created, it can be transformed into a new dataset. The user has the option of choosing per-element transformation or multi-element transformation.
Structure of a dataset
The elements in a dataset must have a uniform structure. Each element consists of one or more objects known as components. The component defines the type of elements and its static shape in the tensor. We can inspect the inferred types and shapes of each and every component in a dataset element. You can name each component separately for added convenience.
Need for an Iterator
To consume values from a dataset, an iterator must be created that can give access to an element of a dataset at a time. Re-initializing the initiator will take you to the next symbolic element. You can also choose different types of initiators as per your needs.
Iterator creation
The elements in a dataset can be accessed by the use of an iterator. So you must create an iterator to retrieve the actual data that you need. There are four types of iterators that can be used –
- Initializable
Such an initiator will let you parameterize the definition of a dataset through the use of one or more tensors which you can feed while initializing the iterator. But it requires an explicit function to be run before you can use the same.
- Re-Initializable
Such an iterator can be initialized using various objects in a dataset. The structure of such objects must be the same i.e. same type and having a compatible shape for every component. It is very useful in case if your dataset needs additional transformation.
- One-shot
It is the simplest and most basic type of iterator. It only supports iteration once in the entire dataset and their is no option for explicit initialization. These do not support parameterization and can handle almost every simple dataset task.
- Feedable
It gives you the maximum flexibility. You get the same ability as that of the Re- Initializable Iterator but with an added benefit of not requiring you to start from the very beginning when you want to switch between iterators.
Feeding the model
When you run the Iterator.get_next(), It will return one or more tensors that are corresponding to the symbolic next element of the iterator. Every time you evaluate the tensors, they will take the next available value in the underlying dataset.
The iterator won’t advance until you use the returned tensor object in a TensorFlow expression and get its result passed. If your iterator reaches the bottom of the dataset, it will display an OUT OF RANGE error. You cannot use the iterator once it reaches this stage. You will have to reinitialize the iterator to be able to use it further.
In case of a nested structure, the returning value will be one or more tensors in the same nested structure.
Some Additional Topics
1. Batch
- Simple Batching
Such batching stacks the consecutive elements in a dataset into a single element. The dataset API has the ability to automatically batch the dataset with the provided size, like a batch of 6 elements.
- Batching Tensors with padding
It works with all the tensors with the same size in a dataset. But some models also have the ability to work with different tensor sizes. It can be done with the help of padding. The size may vary but if they have a common feature, they can be padded together.
2. Shuffle
Shuffling is very important to avoid the nuisance of overfitting. The dataset can be set to shuffle every epoch after a certain interval. For choosing the next element uniformly, a buffer parameter can also be set.
- Repeat
If you have multiple epochs of the same data, there are two methods to process these. The simplest of these two is the Repeat. If you apply the repeat function sans any arguments, the result will be indefinite loop repetition. This function has the ability to concatenate the arguments without differentiating between the end and beginning of the epochs. You can also set a signal for the end of every epoch. It will help you in statistical analysis.The Queue-based API had a lot of issues which has been carefully looked after with the introduction of Dataset API in TensorFlow. It is fast, uses a commonly-used language for its operation and is very reliable. It also has some good methods for pre-processing the data that has been fed to it. It is a very good option to improve your training speed and if properly used, can save up to 30% of your training time.


{kind=link}