

Python is an open-source scripting language and includes various modules and libraries for information extraction and retrieval. In this article, we will be discussing Data Retrieval Using Python and how to get information from APIs that are used to share data between organizations and various companies. The hypertext transfer protocol (HTTP) is defined as an application protocol which is used distributed information systems for communication for the World Wide Web.
Python handles all the HTTP requests and integration with web services seamlessly. When a user uses Python language, there is no need to manually add query strings to your URLs or to form encode POST data. The installation of the requests library is managed with the following command:
|
pip install requests |
Output

Web APIs include various sections which are mentioned as follows:
1. Method
2. Base URI
3. Element
4. Media types
The sections of web APIs for specific URL is described as below:
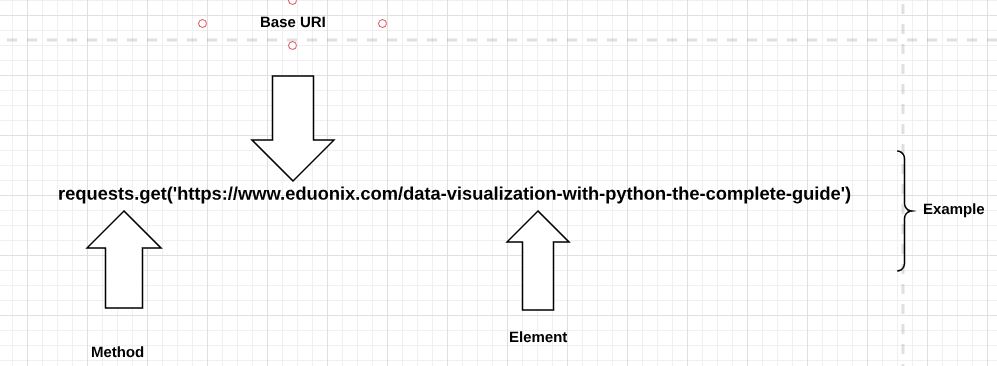
The method is a part of the HTTP protocol which includes methods such as GET, POST, PUT, and DELETE. Usually, these verbs do what their meaning implies i.e. getting data, changing data, or deleting it. In requests, the return value of HTTP is a response object.
Code Implementation to get a text of the response
>>> import requests
>>> response = requests.get("https://www.eduonix.com/data-visualization-with-python-the-complete-guide")
>>> type(response)
<class 'requests.models.Response'>
>>> print(response)
<Response [200]>
>>> print(response.text)
The output of the Data Retrieval Using Python, the response received is as follows:
JSON Parsing:
JavaScript Object Notation(JSON) is a notation used to define objects in JavaScript. The python library “requests” has built a JSON parser into its Response object. It can also convert Python dictionaries into JSON strings. Consider the following example which explains JSON parsing.
{
"first_name": "xyz",
"last_name": "abc"
}
It can be parsed with the Python code as mentioned below:
import json
>>> parsed_json= json.loads(json_string)
>>> print(parsed_json)
{'last_name': 'abc', 'first_name': 'xyz'}
>>> print(parsed_json['first_name'])
xyz
You can also dump the key-value pair into JSON format.
Web Scraping:
Web scraping is a basic practice of using a computer program or various web scraping tools to sift through a web page and gather the data in a systematic format. In other words, web scraping also called “Web harvesting”, “web data extraction” is the construction of an agent to parse or organize data from the web in an automated manner.
The method of web scraping can be used for the following scenarios:
- Retrieving information from a table on the wiki page.
- A user may want to get the listing of reviews for a particular movie to perform text mining. Users can even a build predictive model to spot fake reviews.
- Displaying analysis in visualization manner.
- Enrich the data set based on the information available on the specified website.
- It sounds very interesting to track trending news stories on a particular topic of interest.
But do bear in mind that if you use web scrapers without any proxies, any search engine that you use for web scraping will block or ban your IP address.
And in order for marketers and technical guys to overcome this hurdle, the use of rotating residential proxies, captcha solvers, and authentication tools have been readily available on the web. You can actually read about the Zenscrape residential proxies on the internet.
Example:
In this example, we will be focusing on hacking a web page and storing the information in a dictionary format. Hacker News is a popular aggregator of news articles that is found interesting by all hackers. For hacking a specific it is important to have three plugins installed in your system which are mentioned below:
1. Requests
2. Re
3. BeautifulSoup
The command for the installation of plugin is:
|
pip install requests |
# Importing plugins
import requests
import re
from bs4 import BeautifulSoup
articles = []
url = 'https://news.ycombinator.com/news' #website which is used for hacking
r = requests.get(url) #fetching all the requests
html_soup = BeautifulSoup(r.text, 'html.parser')
for item in html_soup.find_all('tr', class_='athing'):
item_a = item.find('a', class_='storylink')
item_link = item_a.get('href')if item_a else None
item_text = item_a.get_text(strip=True) if item_a else None
next_row = item.find_next_sibling('tr')
item_score = next_row.find('span', class_='score')
item_score = item_score.get_text(strip=True) if item_score else '0 points'
# We use regex here to find the correct element
item_comments = next_row.find('a', string=re.compile('\d+( |\s)comment(s?)'))
item_comments = item_comments.get_text(strip=True).replace('\xa0', ' ') \
if item_comments else '0 comments'
#Storing articles in JSON or dictionary format
articles.append({
'link': item_link,
'title': item_text,
'score': item_score,
'comments': item_comments})
for article in articles:
print(article)
Explanation:
1. The requests are fetched with respect to values fetched in the URL.
2. With the list of items used for iteration using for loop, it helps us to maintain a systematic approach of creating JSON (key-value) pairs.
3. The dictionary (JSON) value created includes a parameter of link, score, title, and comments.
Output:
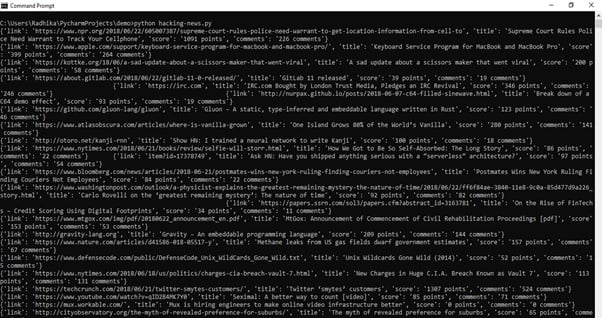
The above illustration explains the web scraping concept without reference to any API. Web Scraping is considered beneficial over the use of API due to the following constraints:
1. The website where a user is focusing on the information extraction does not provide ant API (Application Programming Interface).
2. The API provided is not free of cost.
3. API provided is limited, which means a user can access them only for a specific period of time.
4. API does not expose the data which is needed, but the website does.
Conclusion:
Data science research analysts using Python can easily scrap or fetch the information from the given website for the research outputs. Information Retrieval with Python goes through a simple procedure by showing how to handle the cookies and session values. We also focussed on various methods used for information retrieval which can be used in research.
Also Read- Python vs JavaScript: The Competition Of The Giants!






