

What is image segmentation?
Image segmentation is a method used in which a digital image is broken into subgroups such as segments known as image segments. This is done to reduce the complexity of the image to make the further process and other processes simpler. Segmentation, in simpler words, is assigning labels to the pixels.
How does image segmentation work?
Partition the whole image into various parts/segments. It won’t be a good idea to process the entire image at once, as there will be some regions that won’t be carrying any information. To fulfill this, we divide the image into segments to process the essential parts. This is how image segmentation works.
An image is a set of various pixels. We group pixels having similar attributes while using image segmentation. Have a look at the below visual :
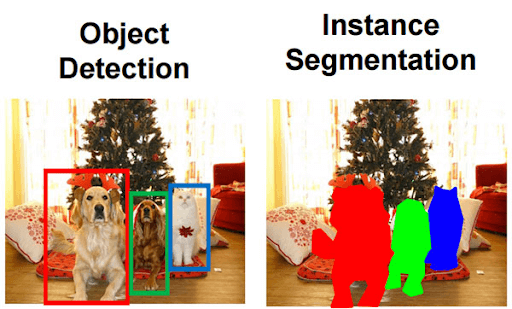
Object detection builds a boundary box around each class of an image. But it tells us nothing about the object or the shape. We want more information in order to identify the object. Image segmentation defines a pixel-wise mask for every object in the image. This technique is a far more granular understanding of the objects in the image.
Why do we need image segmentation?
Segmentation is crucial in image recognition because it extracts the items of interest for additional processing such as description or recognition. The classification of picture pixels is accomplished using image segmentation. To undertake an analysis of the item, segmentation techniques are utilized to extract the required object from the image. With picture segmentation, a tumor, cancer, or a block in the blood flow, for example, can be easily separated from its background. Monochrome image segmentation can be done using a variety of techniques. Color image segmentation is more difficult since each pixel in a color image is vector-valued.
Region-based Segmentation
The region-based segmentation approach compares nearby pixels for similarity. Pixels with comparable properties are clustered together into distinct zones. Gray-level intensity is the most popular way of assigning similarity in all segmentation algorithms, however, there are additional options, such as variance, colour, and multispectral characteristics.
The pixels that indicate homogeneous areas in an image are clustered using region-growing algorithms. Regions are formed by grouping neighboring pixels with qualities that differ by less than a certain amount, such as intensity. In the output image, each grown region is given its own numeric label. Because it is adaptive and less vulnerable to the effects of partial occlusion, adjacency, noise, and ambiguous borders, this family of algorithms works well with difficult imagery.
The region-grown operator performs connected-components analysis on gray-scale pixel data in their most basic form. Neighboring pixels in a picture are compared to a reference pixel value for the region at each pixel. The neighboring pixel is added to the current zone if the difference is less than or equal to the Difference Threshold. In other words, there is another pixel p(j) in a region for every pixel p(i) in the region.
abs (I[p(i)]) – I[p(j)] < Threshold
This algorithm works well with multiband data such as for color images. If there are multiple input images (I1…In), the threshold criteria must hold for all input images
(abs (I1[p(i)] – I1[p(j)]) < Threshold)
&…&
(abs (In[p(i)] – In[p(j)]) < Threshold)
Edge Detection Segmentation
In an image, an edge is a curve that follows a path of rapid change in image intensity. Edges are often associated with the boundaries of objects in a scene. In general, edge detection is the process to characterize the intensity changes in terms of the physical processes that have originated them. Edges provide the topology and structure information of objects in an image. Edge detection can be used for region segmentation, feature extraction and object or boundary description.
The process of edge detection is classified into two broad categories techniques
- Derivative Approach
- Edges are detected by calculating derivatives followed by thresholding.
- They also incorporate noise-cleaning scheme.
- Edge masking means 2D derivative computation.
2. Pattern Fitting Approach
- Here, a series of edge estimates the functions in the form of edge templates over a minute neighborhood are analyzed. Parameters along with features that correspond to the best fitting function are evaluated.
Following are some approaches to complete the process of generation of edge map which may involve some or many of them:
- Noise Smoothing
- Edge Localization
- Edge Enhancement
- Edge Linking
- Edge Following
- Edge Extraction
Image Segmentation based on Clustering
Clustering techniques are used to group data points that are more similar to each other closer together than data points from other groups. Consider an image of an apple and an orange. In apple, the majority of the pixel points should be red/green, which differs from the pixel values in orange. We can tell each object apart if we cluster these points together, right? This is how cluster-based segmentation functions. Now let’s look at some code examples.
As it is visible to our naked eye there are five color segments in the Image
- The green part of Apples
- The orange part of Oranges
- Gray Shadows at the bottom of the Apples and oranges
- Bright Yellowish part of Apple’s top and right parts
- White Background
Faster R-CNN
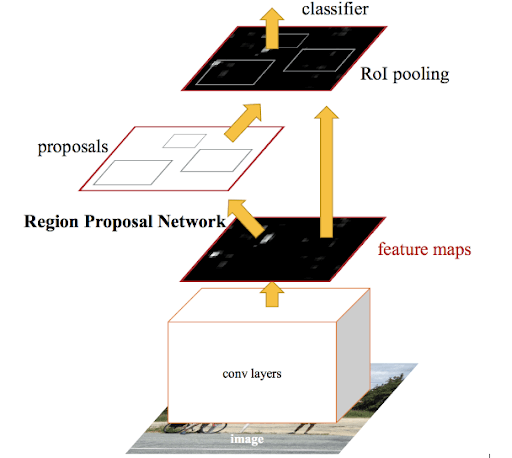
Faster RCNN is a variant of Fast RCNN that has been tweaked. The main distinction is that Fast RCNN generates Regions of Interest via selective search, whereas Faster RCNN employs the “Region Proposal Network,” or RPN. RPN takes picture feature maps as input and outputs a series of object proposals, each with a score for objectness.
In a Faster RCNN technique, the following stages are commonly followed:
- We give the ConvNet an image as input and it returns the feature map for that image.
- On these feature maps, a region proposal network is used. The object proposals are returned, along with their objectness score.
- On these suggestions, a RoI pooling layer is applied to reduce the size of all the proposals to the same size.
- Finally, to identify and output the bounding boxes for objects, the proposals are given to a fully connected layer with a softmax layer and a linear regression layer at the top.
 To begin, Faster RCNN receives CNN’s feature maps and sends them to the Region Proposal Network. RPN overlays these feature maps with a sliding window, and for each window, it constructs k Anchor boxes of various shapes and sizes:
To begin, Faster RCNN receives CNN’s feature maps and sends them to the Region Proposal Network. RPN overlays these feature maps with a sliding window, and for each window, it constructs k Anchor boxes of various shapes and sizes: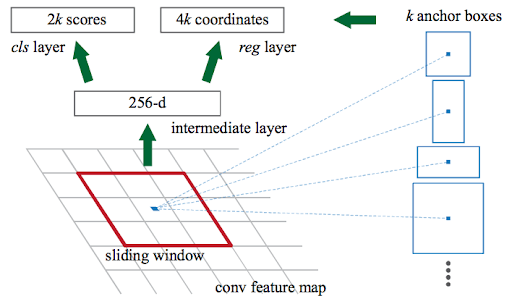
Anchor boxes are a type of fixed-size boundary box that can be found all over the image and come in a variety of shapes and sizes. RPN forecasts two things for each anchor:
- The first is whether or not an anchor is an object (it does not consider which class the object belongs to)
- The bounding box regressor is used to fine-tune the anchors to better fit the object.
Bounding boxes of various shapes and sizes have now been passed on to the RoI pooling layer. After the RPN stage, it’s likely that some proposals will have no classes assigned to them. Each proposal can be cropped so that each proposal contains an item. This is what the RoI pooling layer does. It extracts fixed sized feature maps for each anchor: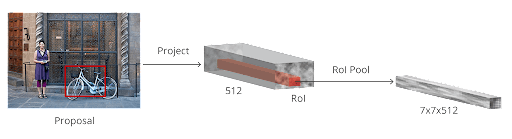
The feature maps are then fed into a fully connected layer that includes a softmax and a linear regression layer. Finally, it classifies the object and forecasts the bounding boxes for the objects that have been recognized.
Mask R-CNN
Mask R-CNN is a deep learning architecture developed by data scientists and researchers at Facebook AI Research (FAIR) that can construct a pixel-wise mask for each object in an image. This is a highly cool notion, so pay attention!
The popular Faster R-CNN object detection architecture is extended with Mask R-CNN. To the already existing Faster R-CNN outputs, Mask R-CNN adds a branch. For each object in the image, the Faster R-CNN approach generates two things:
- It is of a high standard.
- The coordinates of the bounding box
Mask R-CNN extends this by adding a third branch that also outputs the object mask. To get a sense of how Mask R-CNN works on the inside, look at the image below:
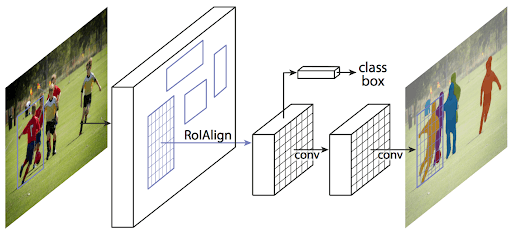
- We give the ConvNet a picture as input, and it returns the feature map for that image.
- On these feature maps, the region proposal network (RPN) is used on these feature maps. This gives the object proposals as well as the objectness score for each of them.
- On these suggestions, a RoI pooling layer is applied to reduce the size of all the proposals to the same size.
- Finally, the proposals are sent to a fully connected layer, which classifies and outputs object bounding boxes. It also returns each proposal’s mask.
Mask R-CNN, which runs at 5 frames per second, is the current state-of-the-art for picture segmentation.
Also Read: Tips For Maximising Images on Your Website


{kind=link}