
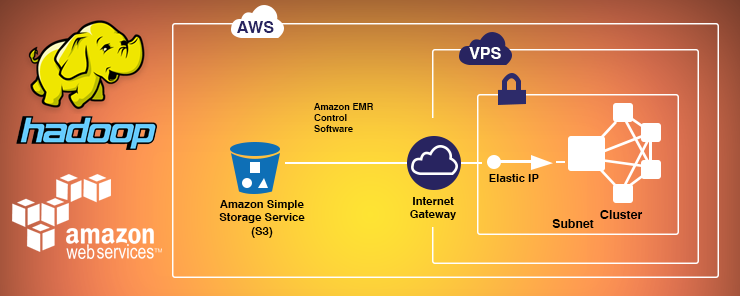
This is a step by step guide to install a Hadoop cluster on Amazon EC2. I have my AWS EC2 instance ec2-54-169-106-215.ap-southeast-1.compute.amazonaws.com ready on which I will install and configure Hadoop, java 1.7 is already installed.
In case java is not installed on you AWS EC2 instance, use below commands:
Command: sudo yum install java-1.7.0-openjdk
Command: sudo yum install java-devel
I am installing hadoop-2.6.0 on the cluster. Below command will download hadoop-2.6.0 package.
Command: wget

Check if the package got downloaded.
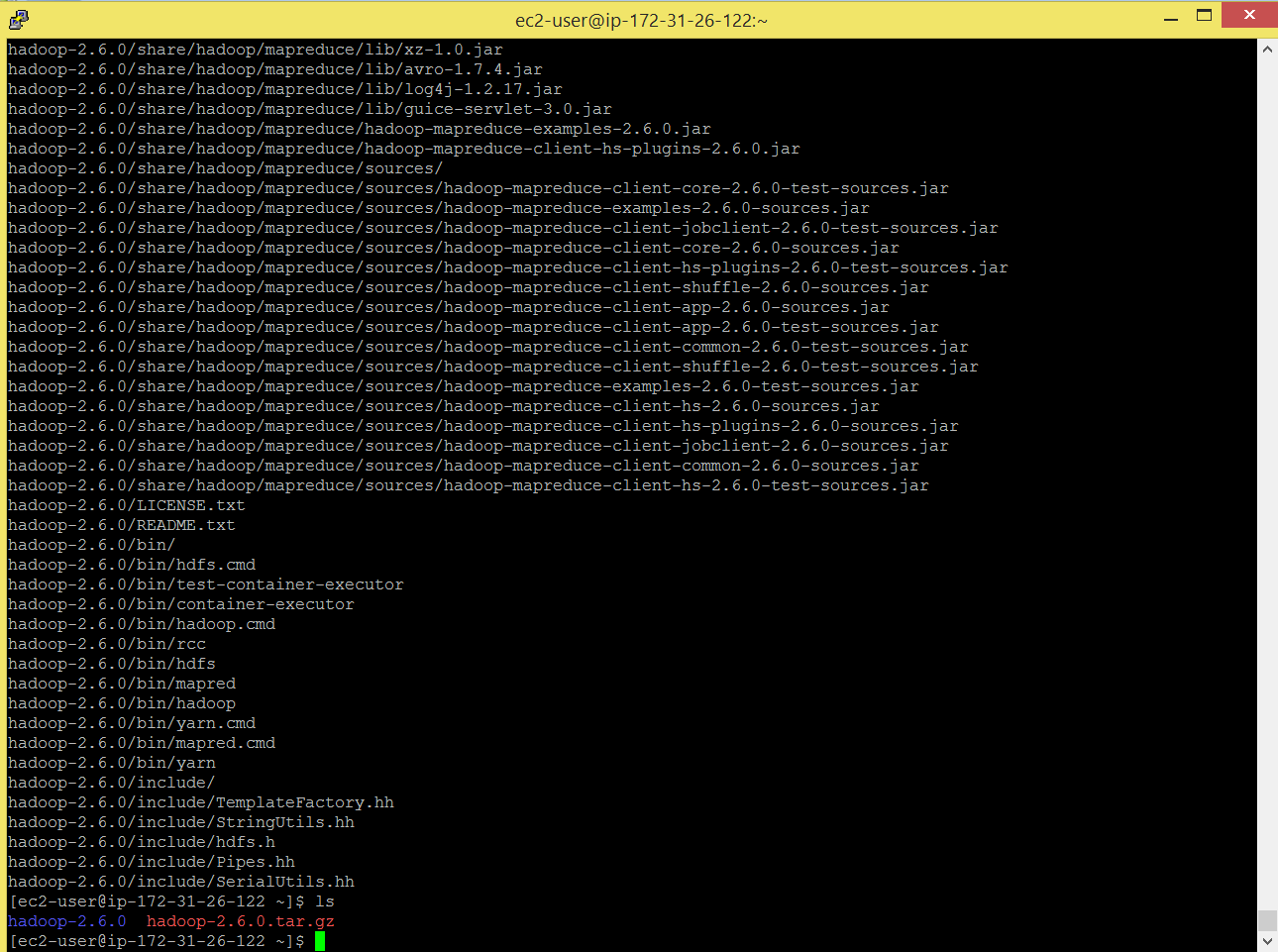
Command: ls
Untar the file.
Command: tar -xvf hadoop-2.6.0.tar.gz

Make hostname as ec2-user
Command: sudo hostname ec2-user
Command: hostname

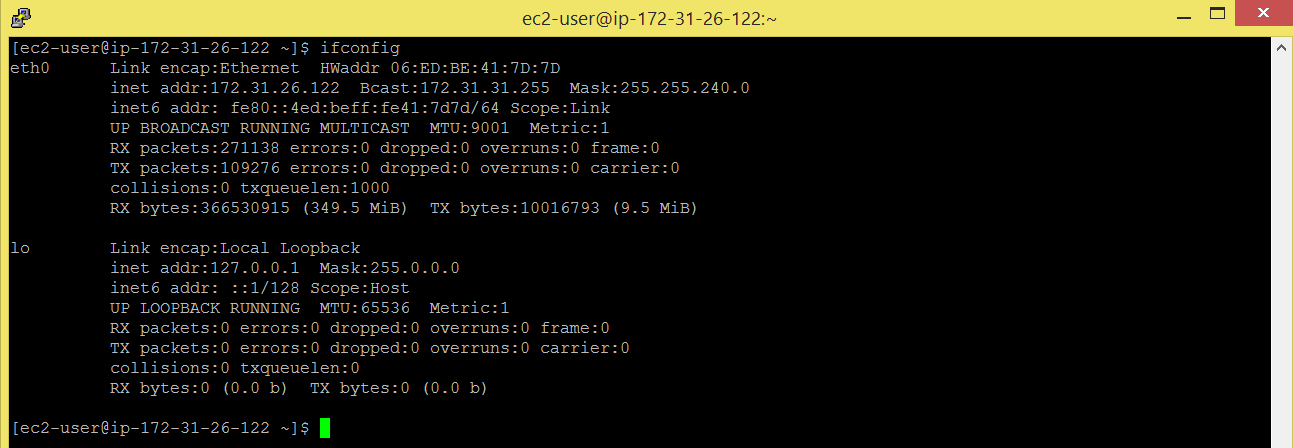
Below command will give you ip address, for me its 172.31.26.122
Command: ifconfig
Edit /etc/hosts file.
Command: sudo vi /etc/hosts

Put ip address and hostname as below, save the file and close it.

The ‘ssh-agent’ is a background program that handles passwords for SSH private keys.
The ‘ssh-add’ command prompts the user for a private key password and adds it to the list maintained by ssh-agent. Once you add a password to ssh-agent, you will not be asked to provide the key when using SSH or SCP to connect to hosts with your public key.
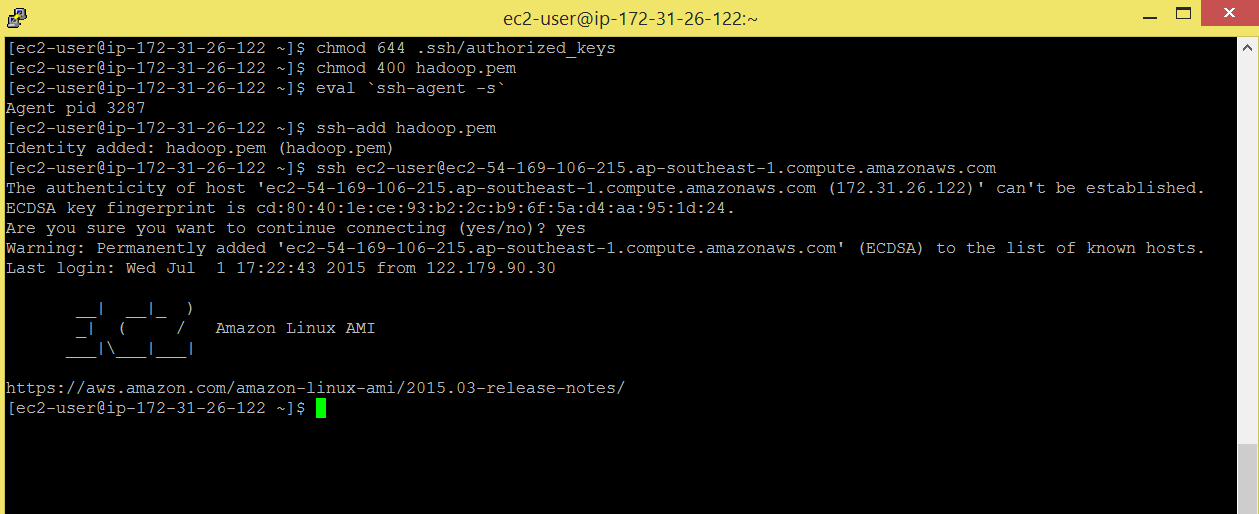
You will get .pem file from your amazon instance settings, copy it on amazon cluster, I have copied hadoop.pem file on my amazon ec2 cluster.
Protect key files to avoid any accidental or intentional corruption.
Command: chmod 644 .ssh/authorized_keys
Command: chmod 400 hadoop.pem
Start ssh-agent
Note: Make sure you use the backquote ( ` ), located under the tilde ( ~ ), rather than the single quote ( ‘ ).’ ).
Command: eval `ssh-agent -s `
Add the secure identity to SSH Agent Key repository
Command: ssh-add hadoop.pem
Command: ssh [email protected]
You will be able to login without password.
Come out of the login.
Command: exit
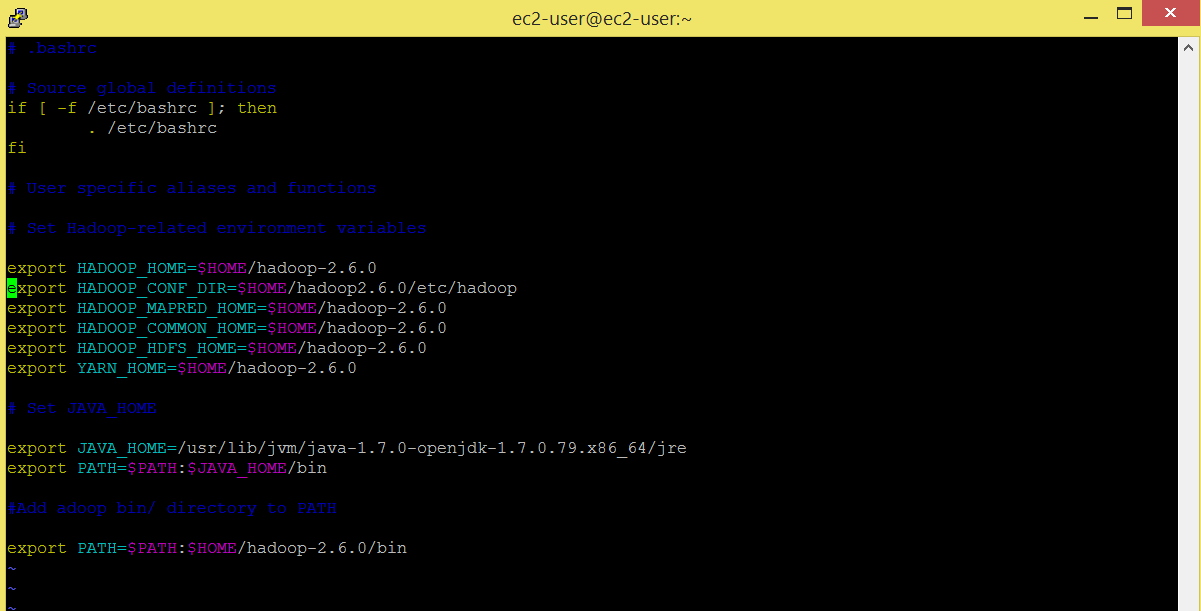
Now we will add hadoop and java environment variables in .bashrc file.
Command: sudo vi .bashrc

# Set Hadoop-related environment variables export HADOOP_HOME=$HOME/hadoop-2.6.0 export HADOOP_CONF_DIR=$HOME/hadoop2.6.0/etc/hadoop export HADOOP_MAPRED_HOME=$HOME/hadoop-2.6.0 export HADOOP_COMMON_HOME=$HOME/hadoop-2.6.0 export HADOOP_HDFS_HOME=$HOME/hadoop-2.6.0 export YARN_HOME=$HOME/hadoop-2.6.0 # Set JAVA_HOME export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre export PATH=$PATH:$JAVA_HOME/bin # Add Hadoop bin/ directory to PATH export PATH=$PATH:$HOME/hadoop-2.6.0/bin
Command: source .bashrc

Enter hadoop command and check if you get a set of options.
Command: hadoop
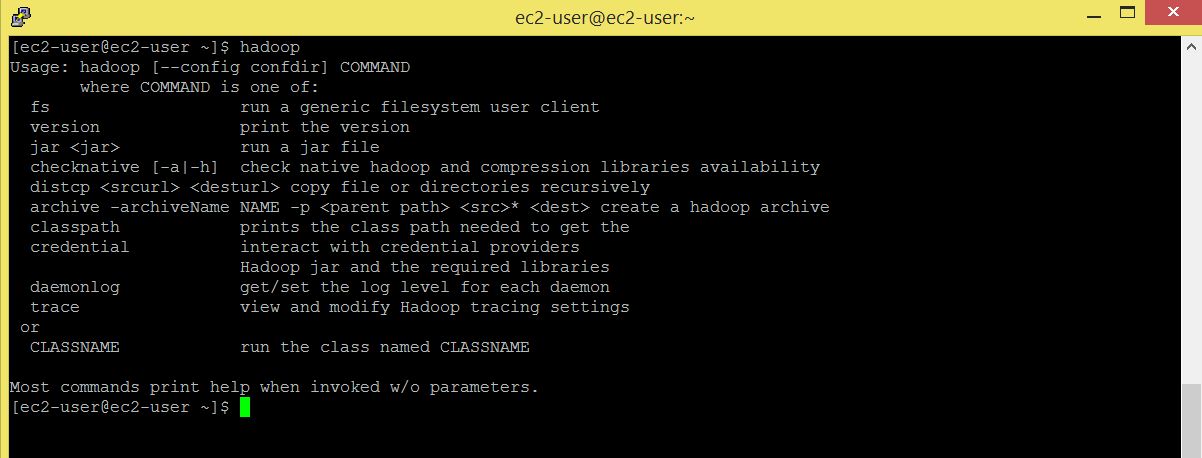
check out the directories present in hadoop-2.6.0
Command: cd hadoop-2.6.0

share directory contains all the jar files.
Command: cd share/hadoop

sbin directory contains all the script files to run or stop hadoop daemons/cluster.
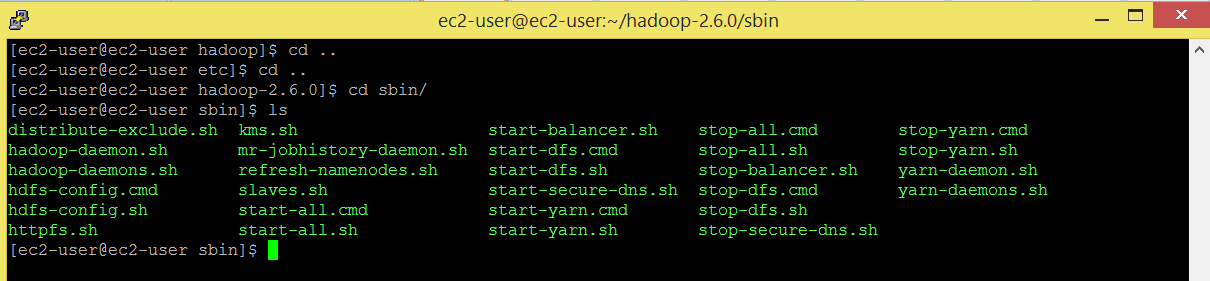
etc directory contains all the configuration files. We will edit few configuration files. Go to etc/hadoop/ directory.
Command: cd ..
Command: cd ..
Command: cd etc/hadoop
Command: ls
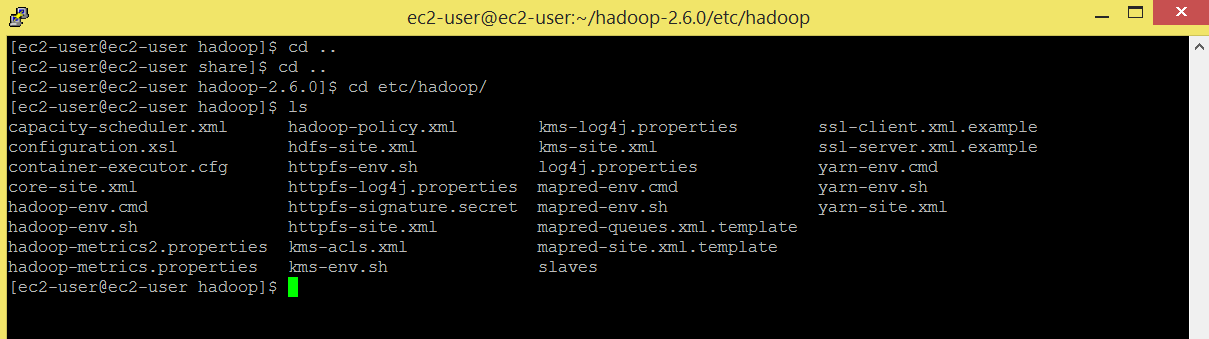
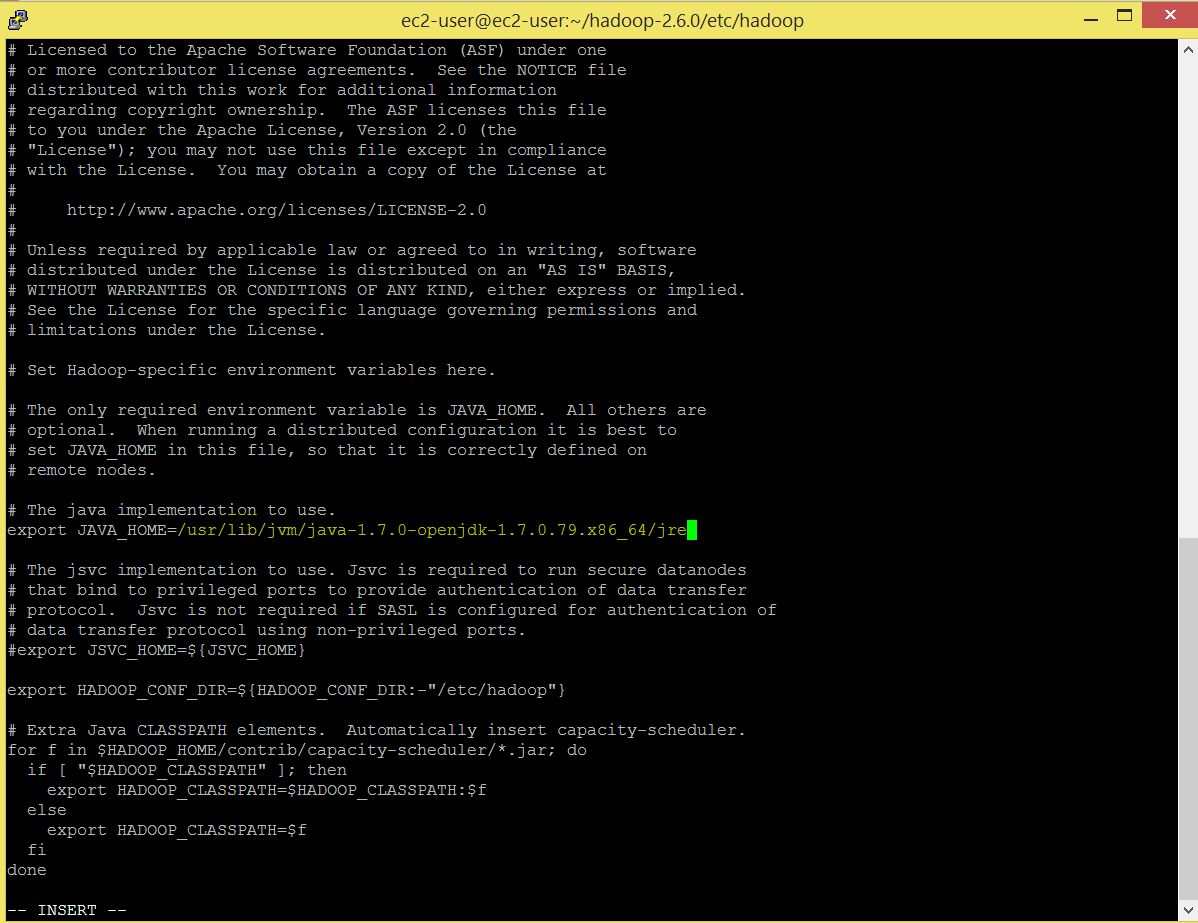
Set java home in hadoop-env.sh file.
# Set JAVA_HOME export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre
Command: sudo vi hadoop-env.sh

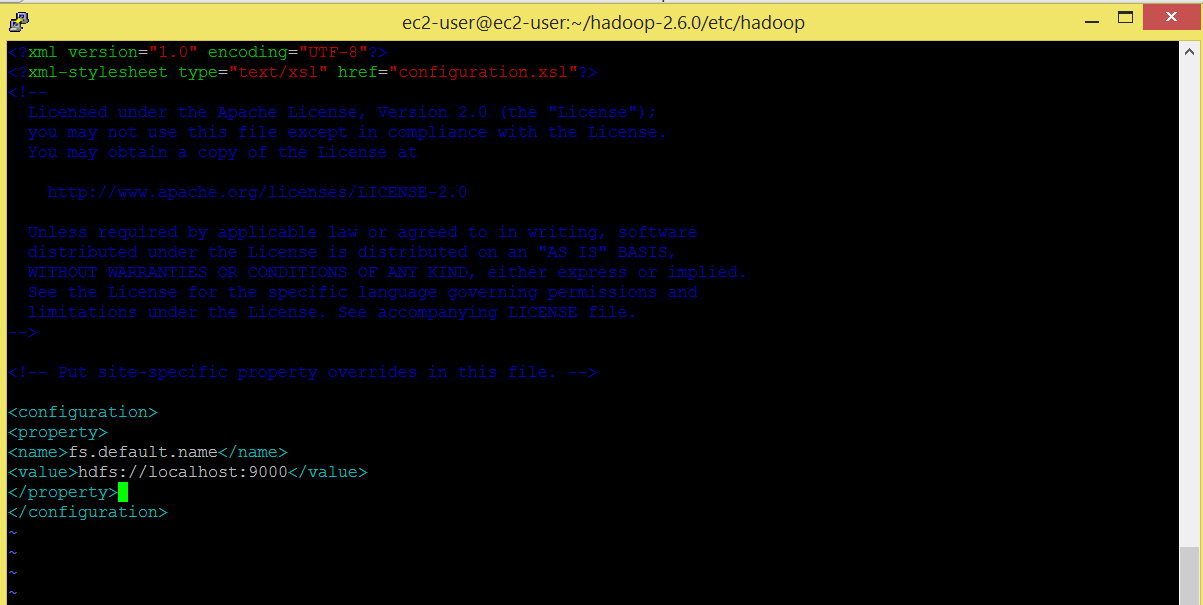
Edit core-site.xml file. This file contains the configuration settings for Hadoop Core such as I/O settings that are common to HDFS and MapReduce.
Command: vi core-site.xml

<strong><configuration> </strong> <strong><property> </strong> <strong><name>fs.default.name</name> </strong> <strong><value>hdfs://localhost:9000</value> </strong> <strong></property> </strong> <strong></configuration></strong>
Make namenode and datanode directory.
Command: mkdir -p /home/ec2-user/hadoop-2.6.0/hdfs/namenode
Command: mkdir -p /home/ec2-user/hadoop-2.6.0/hdfs/datanode

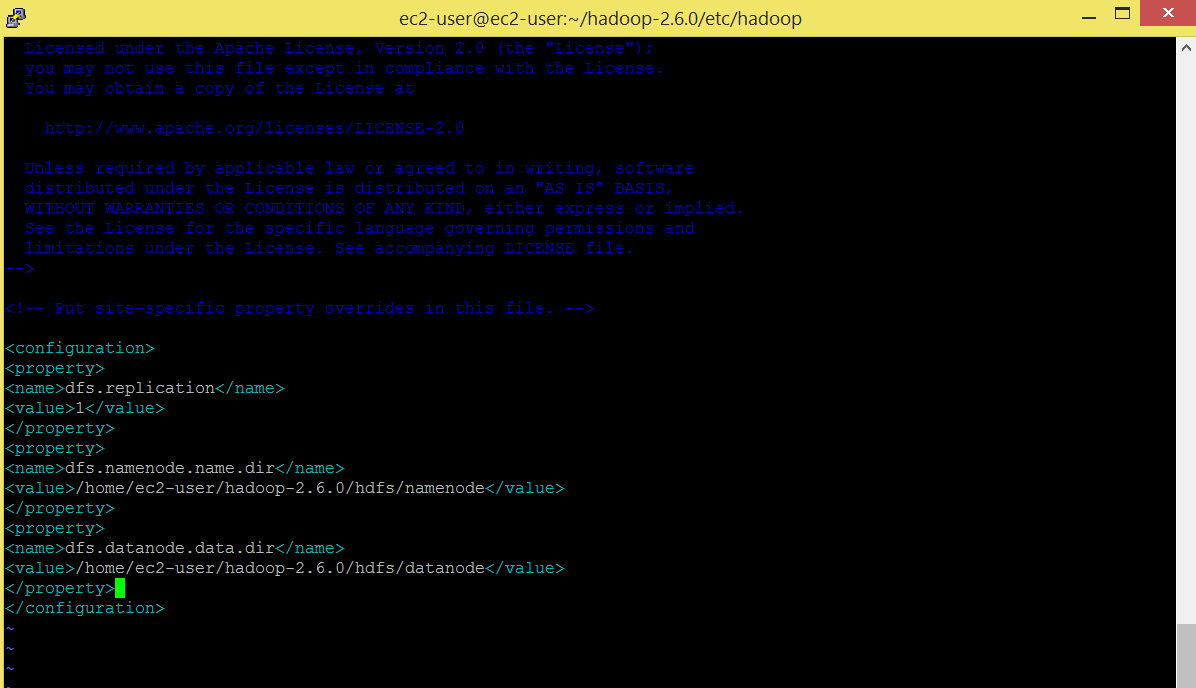
Edit hdfs-site.xml. This file contains the cconfiguration settings for HDFS daemons; the Name Node, the secondary Name Node, and the data node.
Command: vi hdfs-site.xml

<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/ec2-user/hadoop-2.6.0/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>>/home/ec2-user/hadoop-2.6.0/hdfs/datanode</value> </property> </configuration>
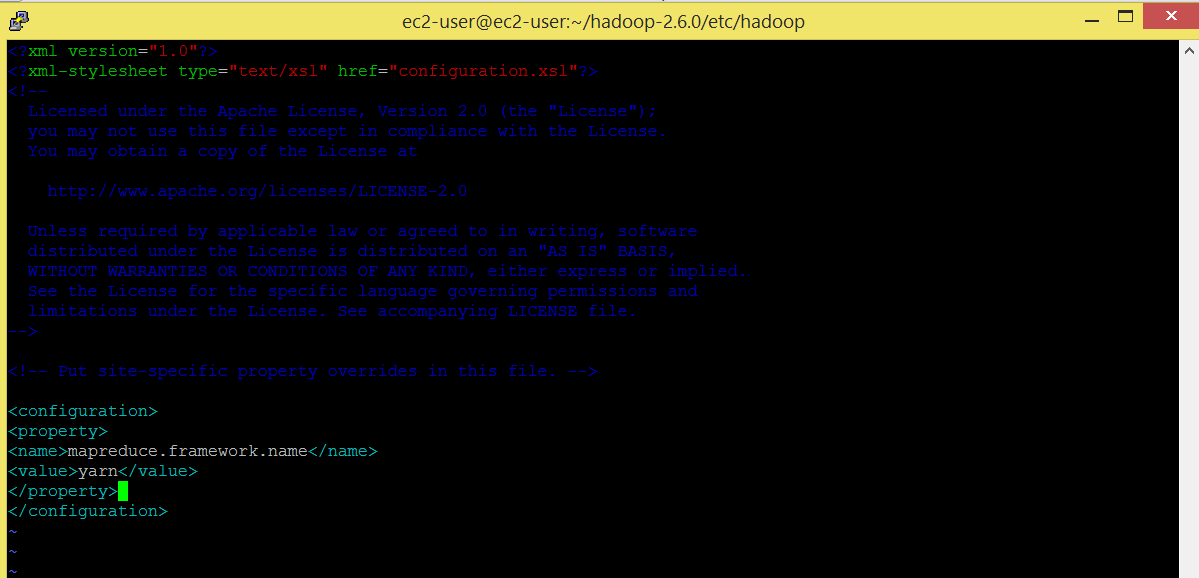
Edit mapred-site.xml. This file contains the configuration settings for MapReduce daemons.
Command: cp mapred-site.xml.template mapred-site.xml
Command: vi mapred-site.xml

<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
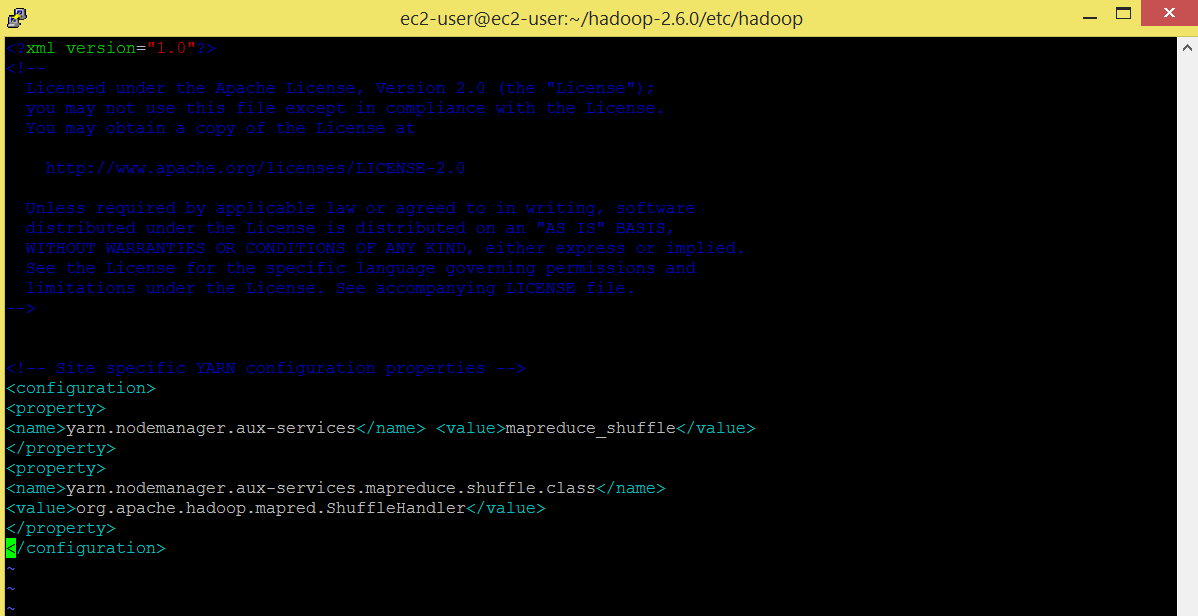
Edit yarn-site.xml. This file contains the configuration settings for YARN.
Command: vi yarn-site.xml

<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
Now we are ready to start the cluster. We will format the namenode.
Command: cd
Command: hadoop namenode -format

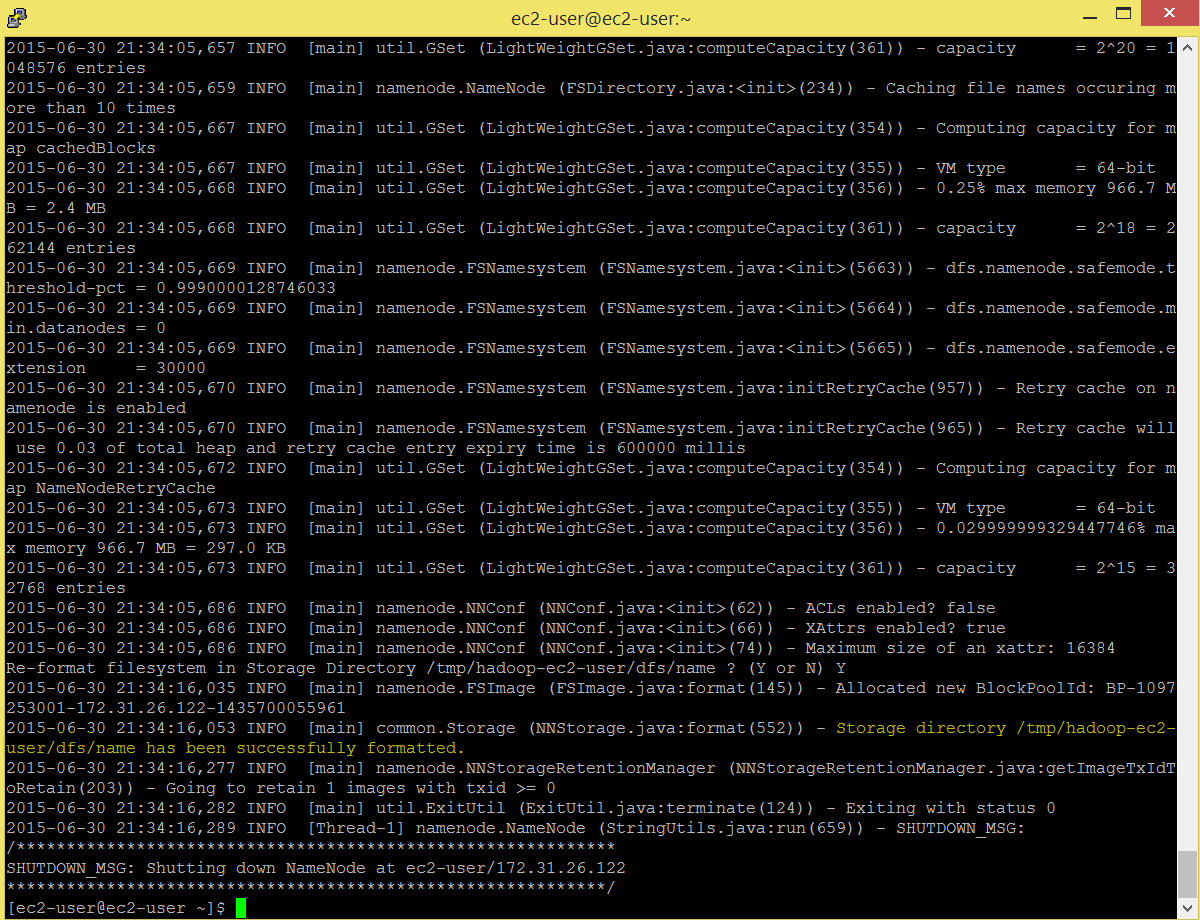
After we format the namenode successfully, we will start all the hadoop daemons.
You are now all set to start the HDFS services i.e. Name Node, Secondary Name Node, and Data Node on your Hadoop Cluster.
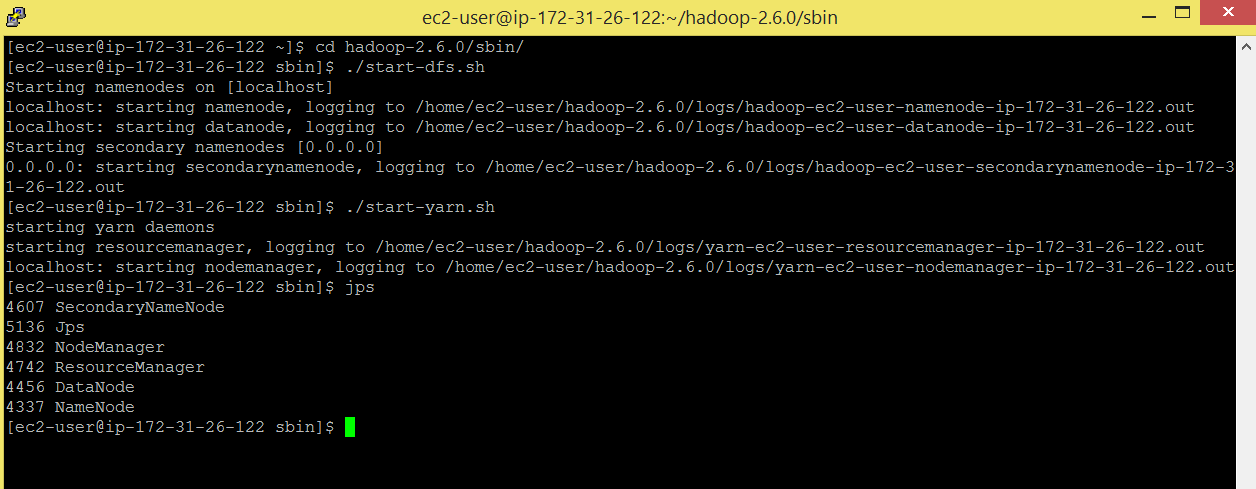
Command: cd hadoop-2.6.0/sbin/
Command: ./start-dfs.sh
Start the YARN services i.e. ResourceManager and NodeManager
Command: ./start-yarn.sh
Now run jps command to check if the daemons are running.
Command: jps
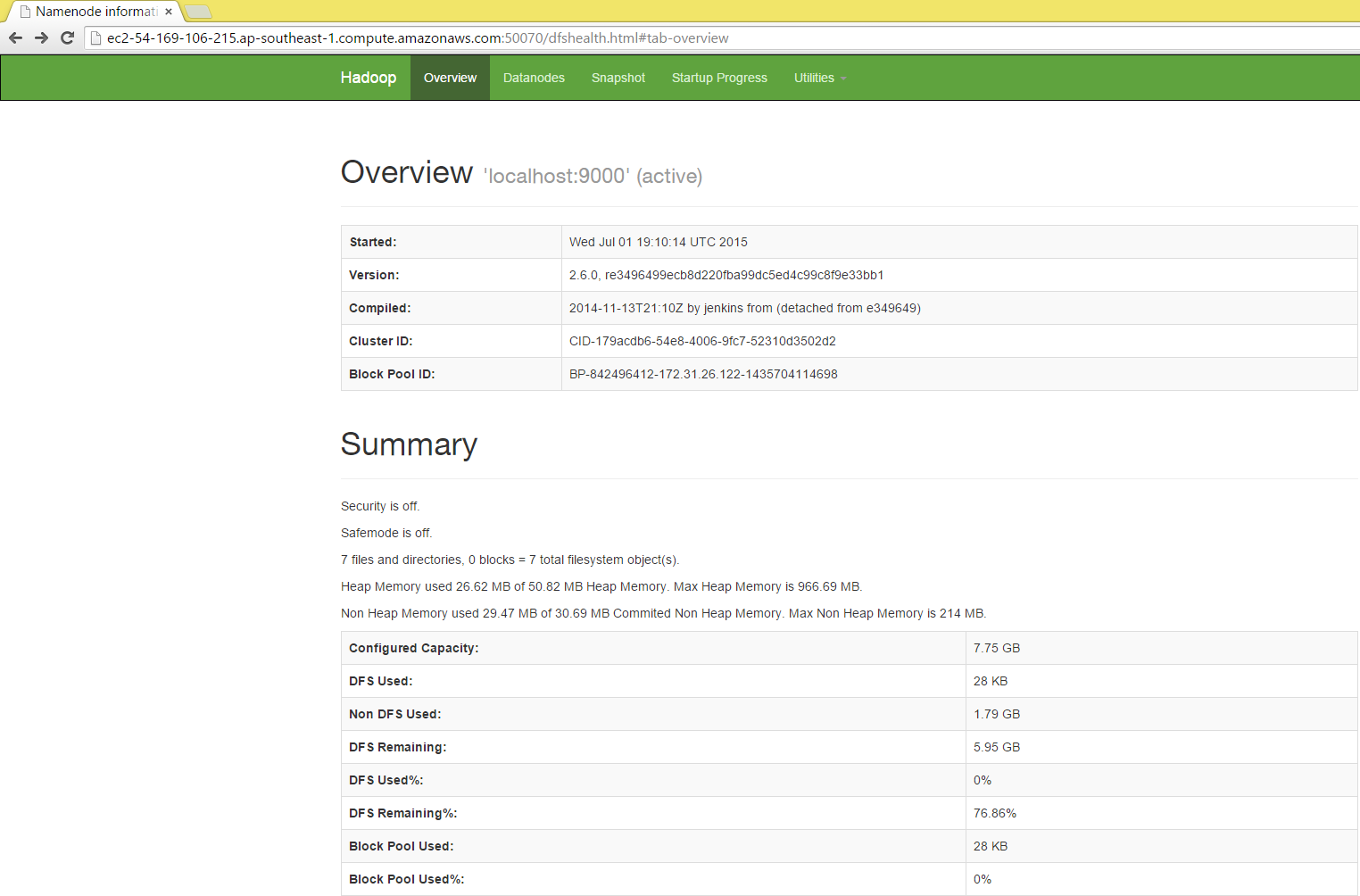
Now open a browser o your system and browse:
ec2-54-169-106-215.ap-southeast-1.compute.amazonaws.com:50070
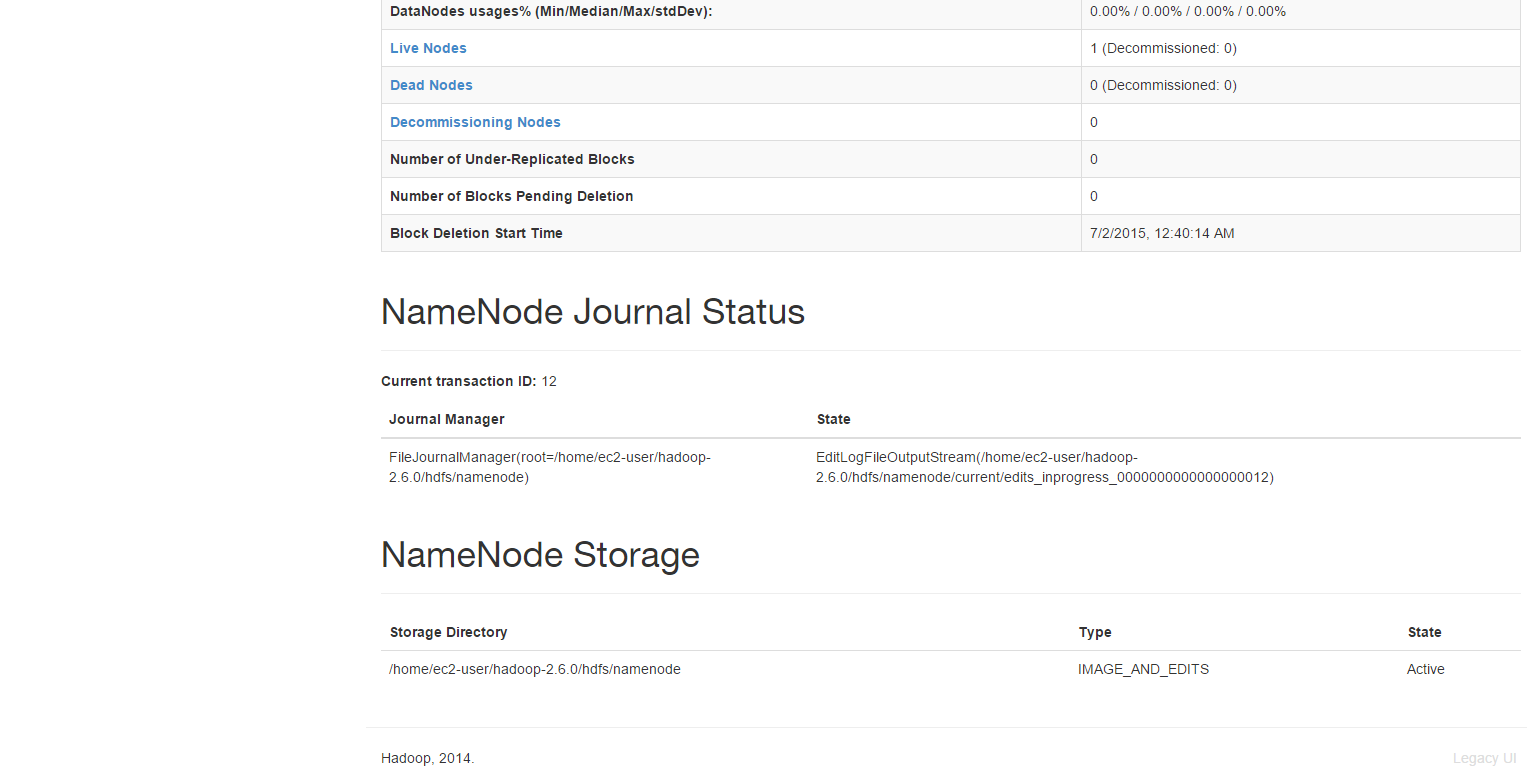
Congratulations your cluster is up and running.


{kind=link}
Hello, I followed the steps above , but datanode not running!!!!
Chnage the Ownership
sudo chown -R ec2-user /home/ec2-user/hadoop2.6.0