

Introduction to big data
Have you ever introspect of how Facebook actually works, how is it viable that your click streams are based on your interest, your likes are based on your interest and what you think, how you behave depends upon how you use the social networking sites. Visit amazon, you will find the right choice for your right fascination. How and when is the biggest question, the answer is simple; it’s all about big data analysis, whenever you buy a product on any ecommerce website, the site starts showing you results based on your previous interest, this is the power of big data.
Now let’s discuss what exactly big data technology is and why it has emerged as the most powerful technology, leaving behind many dominants like cloud computing and machine learning. Big data is basically a data that has capabilities way beyond a normal structured data; let’s first know what the difference is between structured and unstructured data are.
A structured data is one that is stored, managed and analysed using normal relational database for example relational database management systems like oracle’s version of RDBMS or MYSQL or MSSQL server,
while unstructured data is one that has some complexities regarding the data storage as well as data analysis, unstructured data is one that is in the form of log files, click streams, videos, audio’s and other files that cannot be stored and handled with normal relational database.
Apart from this structured and there is one more variation known as semi structured data that is in the form of xml files and emails. Due to the incapabilities of managing the unstructured data using traditional database software systems the researchers founded a novel approach to improve the data analysis and data storage by taking into account to analyse the data that is not even processed by regular software’s to improve the machine learning and give a new scope for business intelligence.
Some of the examples of big data use cases are LinkedIn, Facebook, twitter and many of the e shopping stores that are now days gaining a massive business in terms of online buy and sell. Facebook generates about 500+ terabytes of data per day, and with this data Facebook regularly analyse the instances based on a particular user’s interest and regularly perform trend analysis over the data. This is how big data gain popularity among researchers, business holders, software experts and other experts. The biggest challenge was how to manage this type and this amount of massive data that is why big data is always represented by (VVV) that is volume variety and velocity. The rapid speed at which data is coming, the variety of the data and the amount of the data signifies the need of the big data. According to Gartner (a research and development company) by the end of year 2016, most of the business challenges whether related to IT or not will be solved using big data analysis and now days many of the tools are easily available in market to analyse and manipulate the unstructured data.
Hadoop – A tool for big data analysis
To solve the problem of big data, there was always a need of a mechanism that manages all these unstructured stuff, because it was out of the scope and capabilities of traditional databases to manage and not even by data mining and clustering algorithms too. So for that purpose Hadoop was invented, basically this term was coined way back in 2004 when Google invented an algorithm known as map reduce, it is a programming model that Google used for managing the web pages for its search engine and released a white paper regarding the map reduce programming model. Hadoop has mainly two of its core components i.e. HDFS (for raw and unstructured data storage) and map reduce (a reliable and distributed programming model for unstructured data analysis), rest of them were incorporated as time passed so that to make Hadoop framework more reliable and ready to work for any type of unstructured data, with keeping in mind to reduce the analysis time.
Some real world examples of Hadoop
Banking and finance sector uses Hadoop for keeping their customers information related to their transactions. Bank of America uses Hadoop for keeping their critical data for storage and analysis. Healthcare sector uses Hadoop, Facebook uses Hadoop for various purposes and HBASE as well for keeping the column oriented database records for quick analysis. Facebook also uses HDFS, and hive for running SQL statement. Twitter uses Hadoop to analyse following records.

Apart from this, insurance sector uses Hadoop for risk profiling and setting up the policies terms and conditions and offers for individual users. Oil and gas sector also uses Hadoop.

Defining Hadoop and knowing more about it
Now days there are many flavours of Hadoop including oracle’s version of Hadoop, but if we talk specifically about apache Hadoop then “it is a framework that enables us to perform distributed processing of large datasets across clusters that are running over commodity hardware”. Commodity hardware simple means that we don’t have to purchase heavy loaded servers and other costly components, it is valid to store the data on normal computing machines and doesn’t require high end server for data storage.
Hadoop eco system/ framework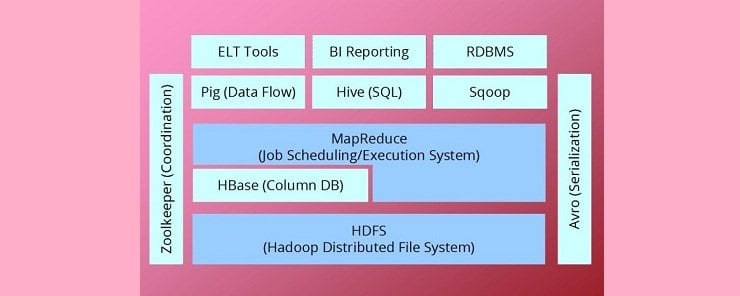
At bottom, is HDFS that is used for storage of unstructured data, map reduce is the traditional programming model for data analysis and data sorting and also performing some useful functions on data for some results. Pig is a dataflow language and execution environment for exploring very large datasets for making some useful knowledge out of it. SQOOP is a tool for moving the data in and out of HDFS i.e. SQL to Hadoop in other words extracting the data from a SQL database and dumping it to HDFS for analysis. Hive is a data warehousing tool and it is same as running SQL statements and works as an OLAP (online analytical processing) the queries are translated by a runtime engine and invokes a map reduce job for data processing. Zookeeper is a coordination service used in conjunction with HBASE. HBASE is a new way of setting up a database and sometimes also refers to NOSQL databases i.e. (Not only SQL). It stores the data in a column format sometimes also known as column family, it is a very important part of Hadoop eco system as Facebook mainly uses this tool for maintaining the relational database records.
Deep Dive into Hadoop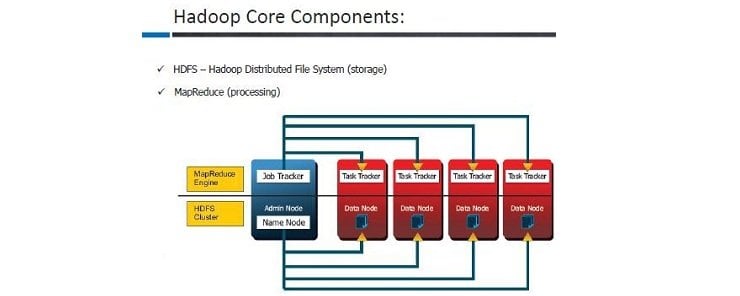
Here Data Nodes are mainly slave nodes in the cluster, where the data is actually stored. Name node is the master or admin of the cluster, name node contains the metadata whereas data nodes stores the data block. Job tracker is like the administering tool for all the data nodes and task trackers process the execution task given by job tracker.
How the read and write operations are performed (WORM) Write once Read Many times
A rack is a physical storage of data together. It is also a collection of physical machines in same location. The data is replicated according to the replication factor configured in the name node and if the data is to be replicated then the client will write the data on all the data nodes according to the replication factor. The read operation will directly be done between the client and the Data Node; name node will not be involved in any read write operation.
Benefits of this technology and future aspects
As we know that the future of this world is “data”, it’s all about data from personal computers to small android devices to large servers like Facebook scribe server or any big data centre. The prime issue is how can we store analyse and extract some useful information out of it. We are setting new parameters to the perception for analysing the data of any type and any quantity. Its way beyond data mining technologies and those orthodox data mining algorithm, big data is all about dealing with a huge data and the future of computing is big data, the future of knowledge extraction is big data, analysing and performing miracles to business giants and gaining a business insight to increase their productivity is big data.
The usage of this technology will affect the business companies whether IT or non IT and will result in a significant boost in increasing their business and will provide a new stepping stone for business era, it will also help in enhancing the technologies by emphasizing and privileging more research and development tools and techniques for better future and ease to live. Apache Hadoop will be enhanced with new features and functionality, as open source technologies are capable of incorporating new features and technologies for enlarging the existing Hadoop framework with more advance tools.


{kind=link}