

Hadoop as a production platform is supported on Linux but Windows and other flavors of UNIX such as Mac OS X can be used as a development environment. Red Hat Enterprise Linux (RHEL), Ubuntu, CentOS, Fedora, Debian and OpenSuse take up the major share of commercially deployed Linux systems. Therefore most Hadoop installations exist on these systems. The different Linux flavors have differences in the way they are administered. Therefore, the choice of Linux system to run Hadoop will be greatly influenced by existing skills. It is better to use a platform you are already comfortable with.
This tutorial assumes a basic understanding of configuration files and use of command line interface. Configuration file options are highlighted in green while shell commands are highlighted in green.
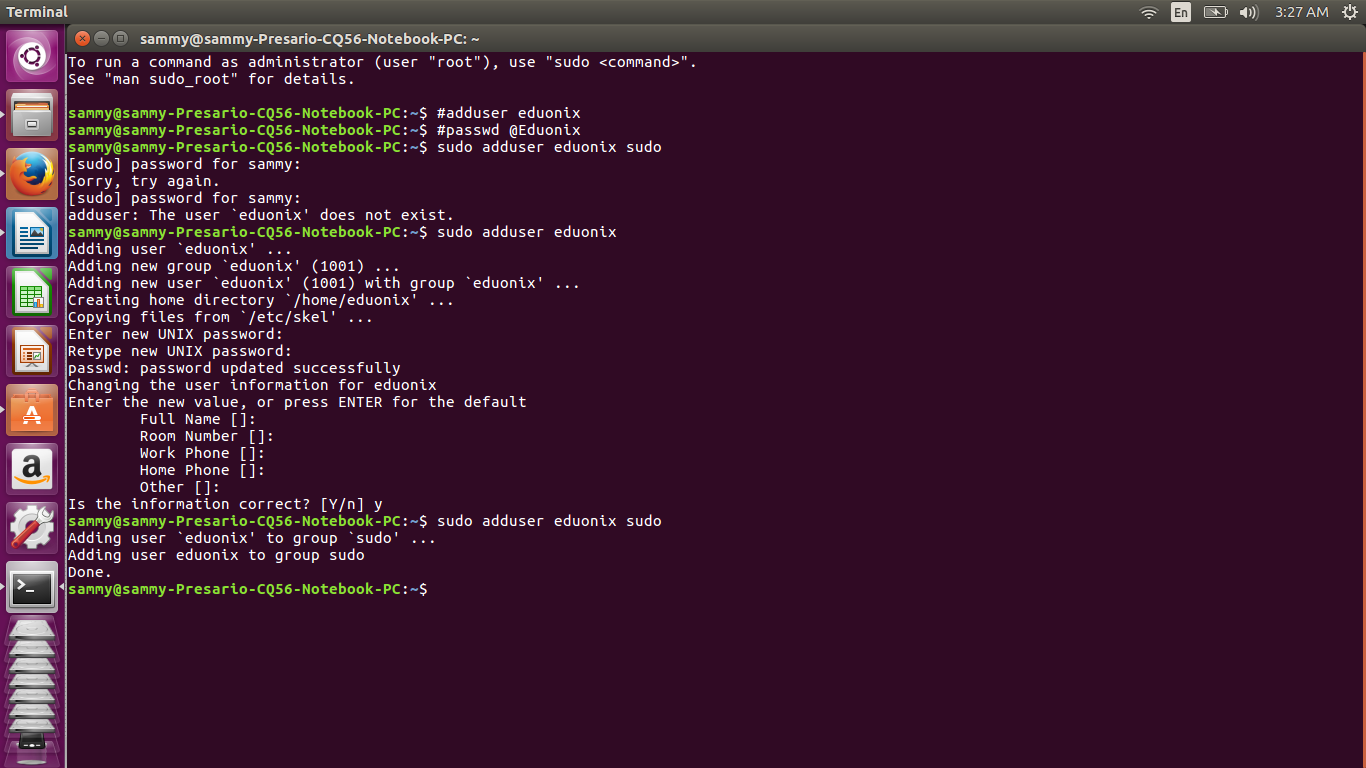
To begin, we need to create a separate user for running Hadoop. The commands below will add a user eduonix with password @Eduonix1
# adduser eduonix
# passwd @Eduonix1
Login as a root user and run this command sudo adduser eduonix sudo. This gives user eduonix root privileges. Once you have created eduonix and added the user to sudo group, login as eduonix
Since Hadoop runs on the local machine and remote machines, it requires SSH. For a single node set up SSH access needs to be configured to allow access to localhost for user eduonix created above. SSH is enabled by running the command below.
sudo apt-get install openssh-server
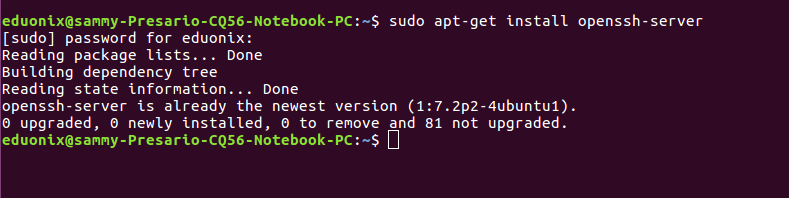
If SSH is already installed, you will get the above output. If it is not installed it will be installed.
After the SSH server is installed, configuration can be done by editing sshd_config that resides in the /etc/ssh directory. It is important to note sshd_config is for the SSH server while ssh_config is for the SSH client. Create a backup copy of sshd_config that can be used to restore your configuration by running the command below.
sudo cp /etc/ssh/sshd_config /etc/ssh/sshd_config.factory-defaults
Open sshd_config in a text editor by running the command below for Ubuntu versions higher than 12.04. In lower versions replace sudo with gksudo.
sudo gedit /etc/ssh/sshd_config
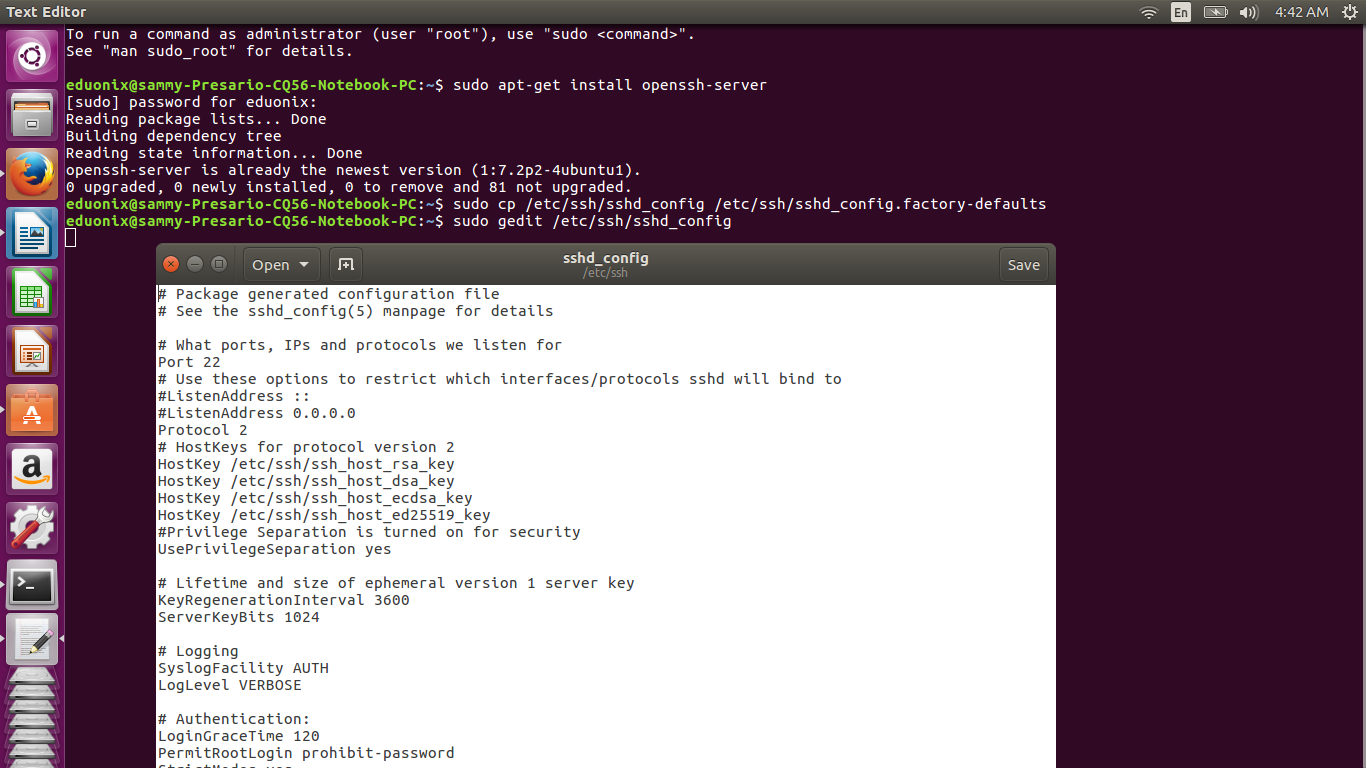
Some changes need to be made on sshd_config. Disable password authentication by changing this line in the configuration file #PasswordAuthentication yes to PasswordAuthentication no. Note that lines beginning with # are comments. Specify that user eduonix has permission to use SSH by adding the line below at the bottom of sshd_config.
AllowUsers eduonix
Add the line below to disable root login to the server.
PermitRootLogin no
Add the line below to allow public key authentication
PubkeyAuthentication yes
Increase the log level to verbose to monitor if there is any malicious traffic by changing this line LogLevel INFO to LogLevel VERBOSE.
Save the changes and run the command below to apply them.
sudo restart ssh
If you get an error “Unable to connect to Upstart” use the command below
sudo systemctl restart ssh

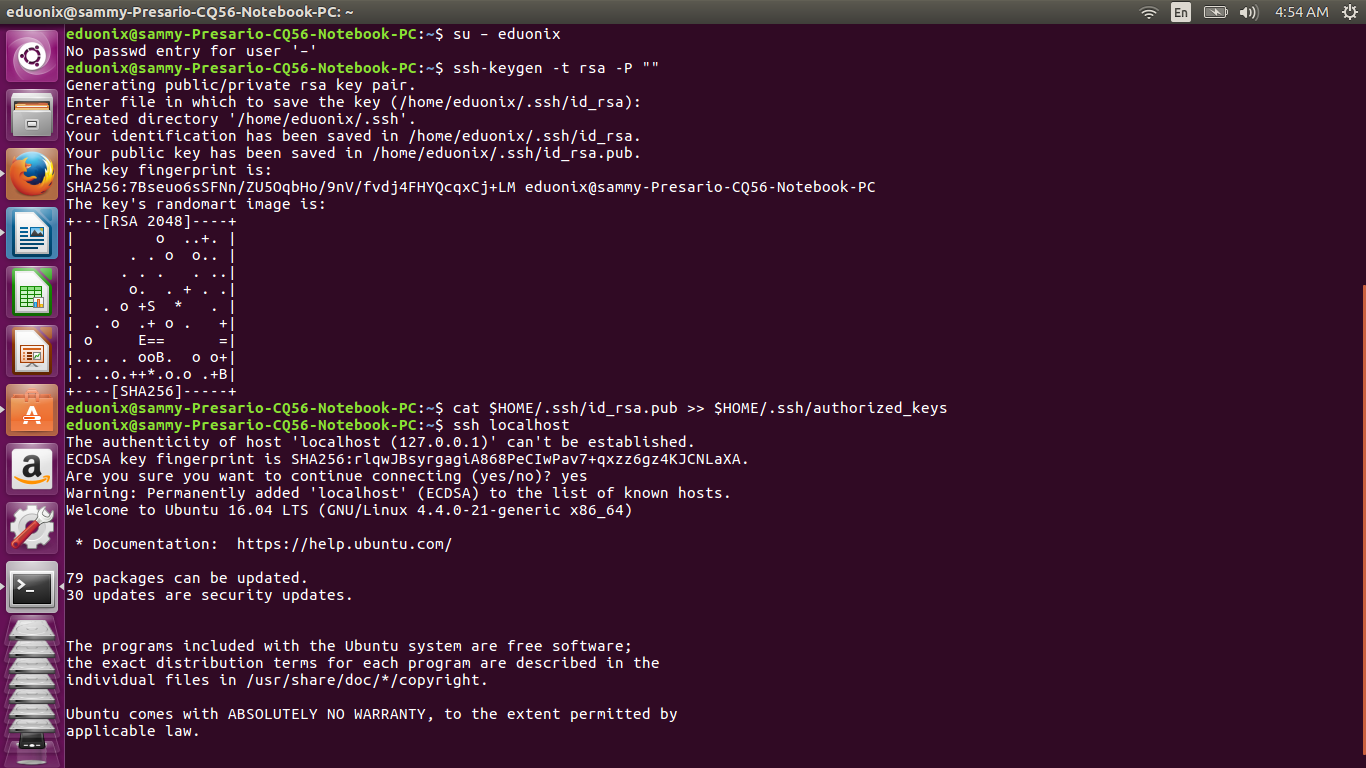
After SSH is configured, an SSH key for the user eduonix is generated by running the commands below. They create an RSA key pair without a password. A password would be required every time Hadoop interacts with its nodes so we can save ourselves the bother of being prompted for a password every time.
su – eduonix
ssh-keygen -t rsa -P ""
After the key has been created, we use it to enable SSH access to the local machine by running the command below which adds it to the list of known keys.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
The last step is testing the SSH setup and saving the local machine’s host key fingerprint to eduonix user’s known host file by running the command below.
ssh localhost
Java is required to run Hadoop on any system, therefore the first step is to install a version of Java that supports the Hadoop version you intend to run. Hadoop versions later than 2.7.0 require at least Java 7 while versions 2.6 and earlier are supported by Java 6. In this tutorial we will install Hadoop 2.7.1, so we will begin by installing Java 8.
Execute the commands below at the terminal to install Java.
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer
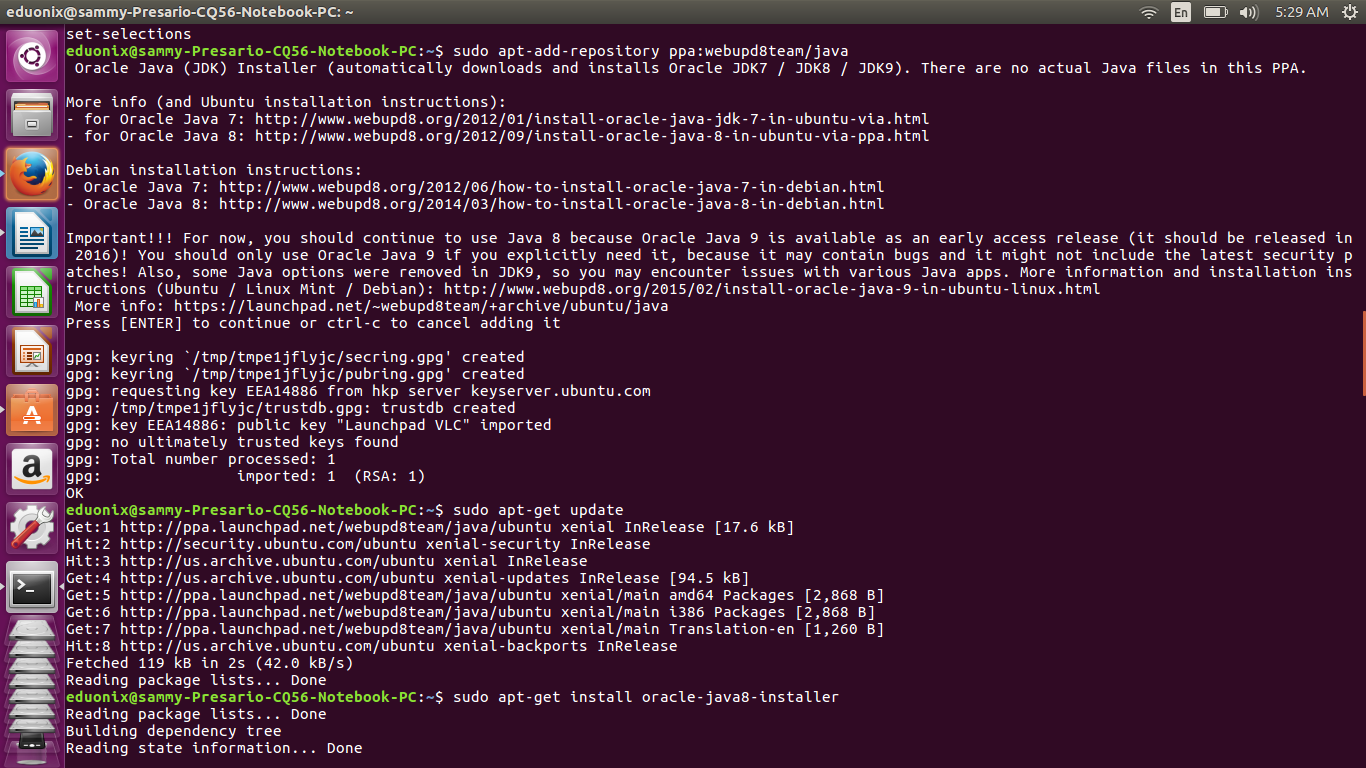
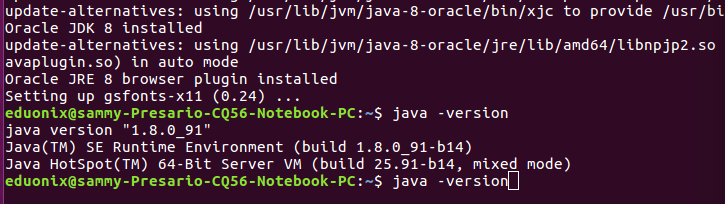
Check that Java has been correctly installed by running the command below.
java -version
Download Hadoop 2.7.1 from the closest Apache mirror site and extract the contents to the directory of your choice. In this tutorial, we will extract the contents to /usr/local/hadoop . Change the ownership of all the files to the user eduonix. If the commands fail to download Hadoop just navigate to closest Apache mirror and download Hadoop. I downloaded it from the url shown below. Hadoop will be downloaded into the Downloads directory.
Move to the downloads folder by typing this command cd ~/Downloads
Extract the hadoop download
sudo tar xzvf hadoop-2.7.1.tar.gz
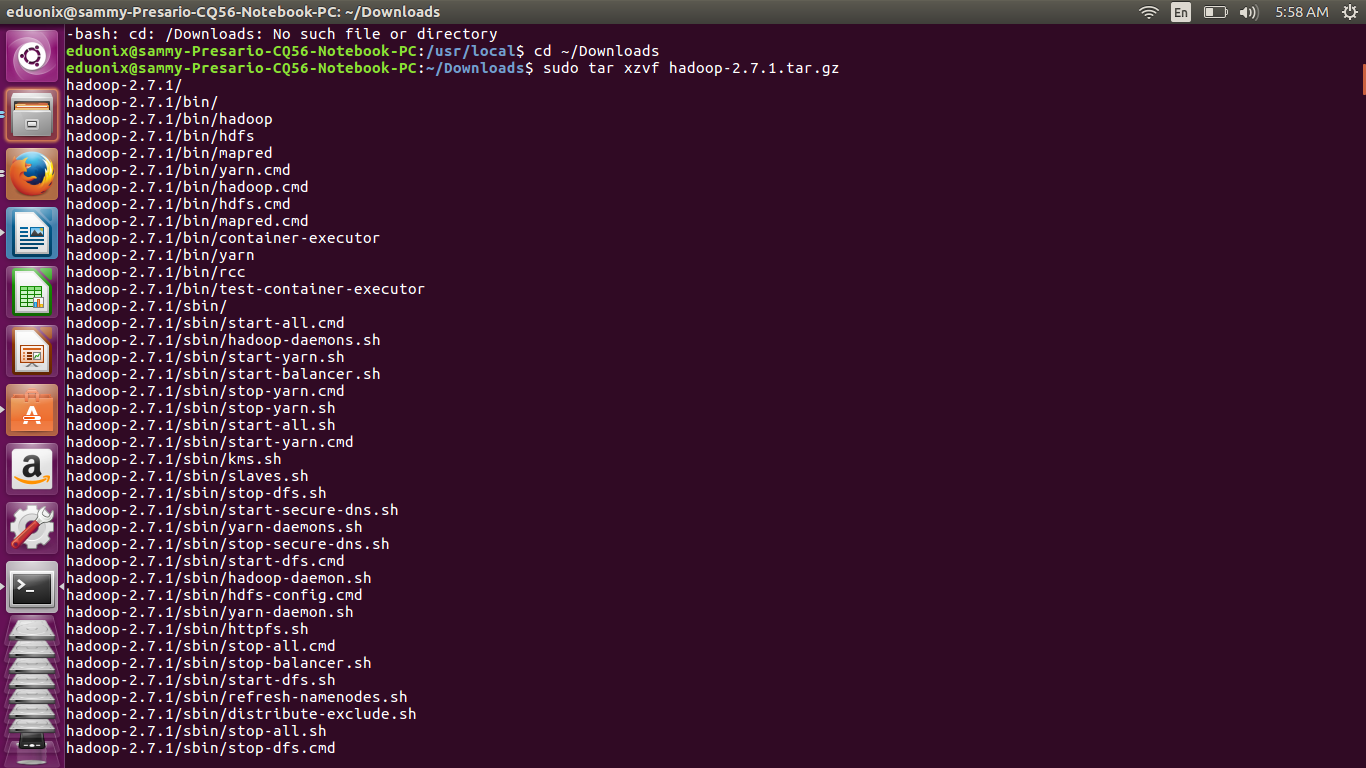
Make a directory for installing Hadoop
sudo mkdir /usr/local/hadoop
sudo mv hadoop-2.7.1.tar.gz /usr/local/hadoop
sudo chown -R eduonix /usr/local/hadoop

You need to edit .bashrc file for the user eduonix, so open it in a text editor by running gedit ~/.bashrc from a terminal.
Check where java is installed by running readlink -f /usr/bin/java. You should substitute the correct path when adding the lines below at the end of .bashrc file.
export JAVA_HOME=/usr/lib/jvm/java-8-oracle export HADOOP_INSTALL=/usr/local/hadoop/hadoop-2.7.1 export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib/native"
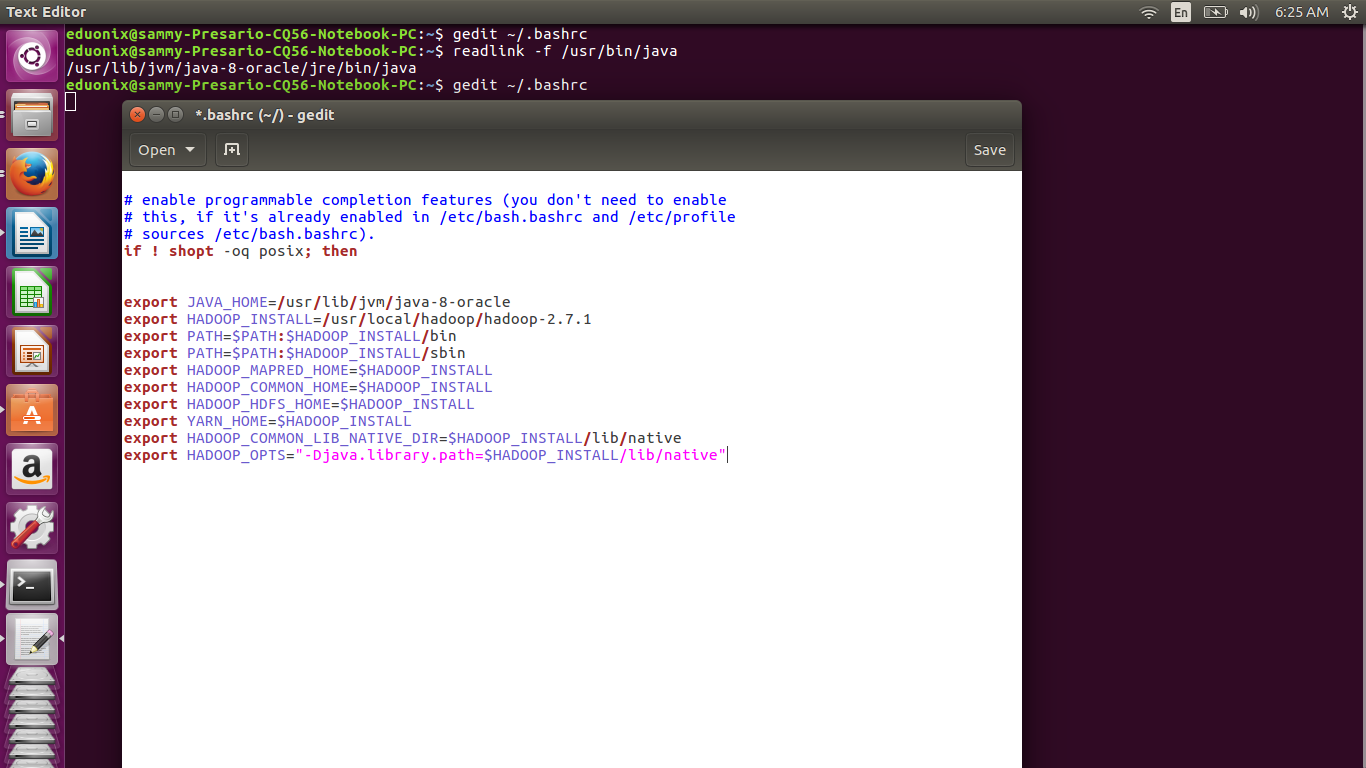
Save the file and reload it by running source ~/.bashrc
The directory /usr/local/hadoop/hadoop-2.7.1/etc/hadoop contains configuration files. Open hadoop-env.sh in a text editor and set JAVA_HOME variable by adding the line below. This specifies the java installation that will be used by Hadoop.
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
Create a directory that will act as the base for other temporary directories and assign it to the user eduonix by running the commands below.
sudo mkdir -p /app/hadoop/tmp
sudo chown eduonix /app/hadoop/tmp

All the Hadoop configuration files reside under usr/local/hadoop/hadoop-2.7.1/etc/hadoop
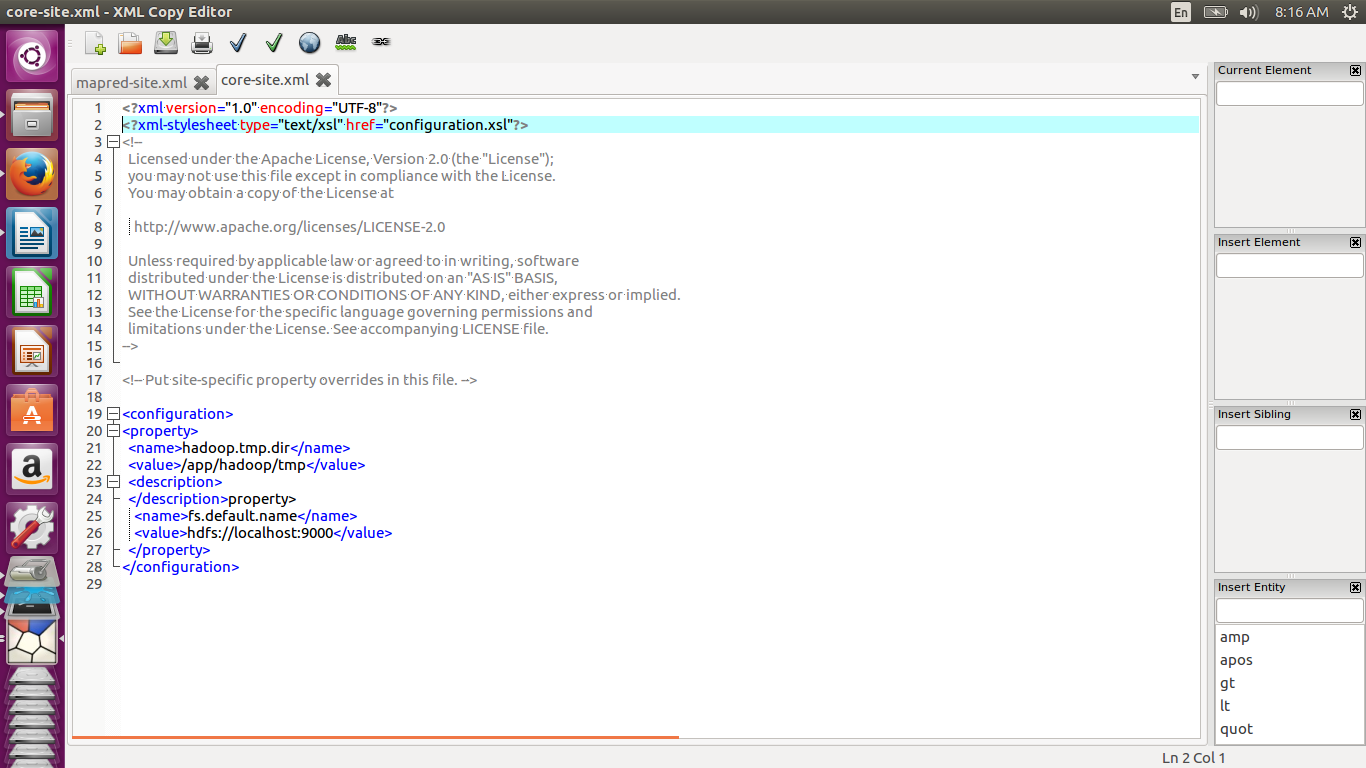
Modify core-site.xml to what is shown below. This file shows Hadoop daemon where the namenode is running in the cluster. This is specified by the fs.default.name parameter. The hadoop.tmp.dir specifies the directory that is used by the local file system and HDFS as a temporary directory.
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description> </property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Create a mapred-site.xml from the template provided by copying and renaming the template.
cp /usr/local/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.xml
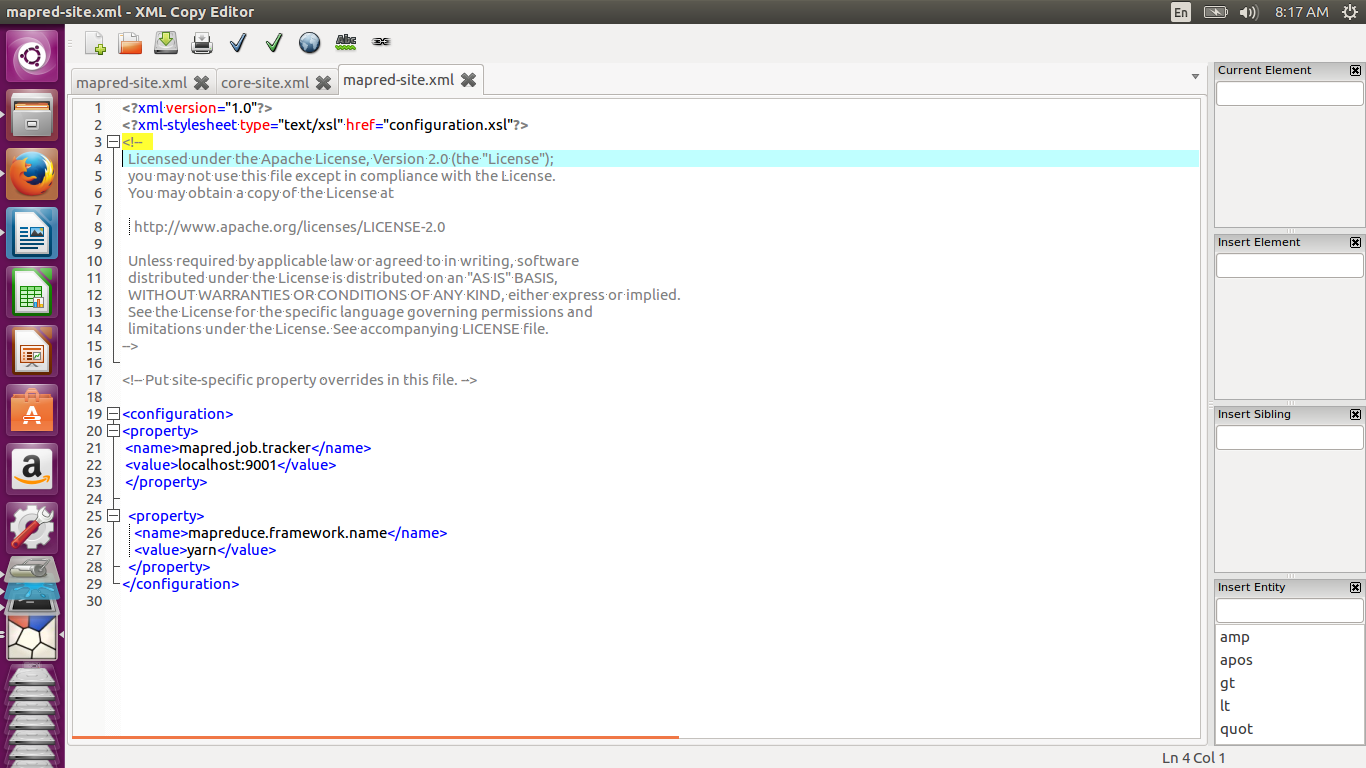
Modify mapred-site.xml as shown below. The mapred.job.tracker parameter specifies the IP and port of of the jobtracker. The mapreduce.framework.name specifies the framework to be used for mapreduce. It can be set to yarn, classic or local
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
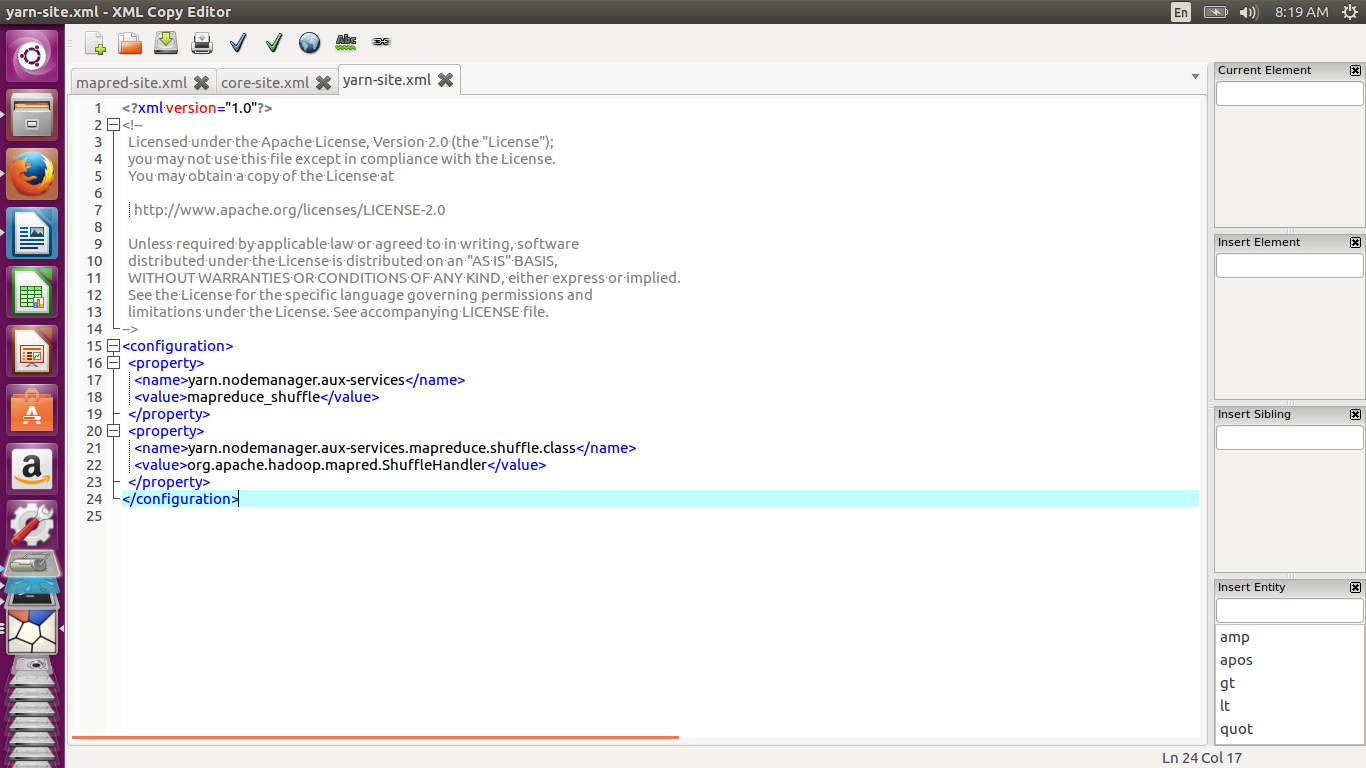
Modify yarn-site.xml as shown below
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
The hdfs-site.xml is used to specify the namenode and datanode directories. Before modifying this file, we create the namenode and datanode directories.
sudo mkdir -p /usr/local/hadoop_store/hdfs/namenode
sudo mkdir -p /usr/local/hadoop_store/hdfs/datanode
sudo chown -R eduonix /usr/local/hadoop_store

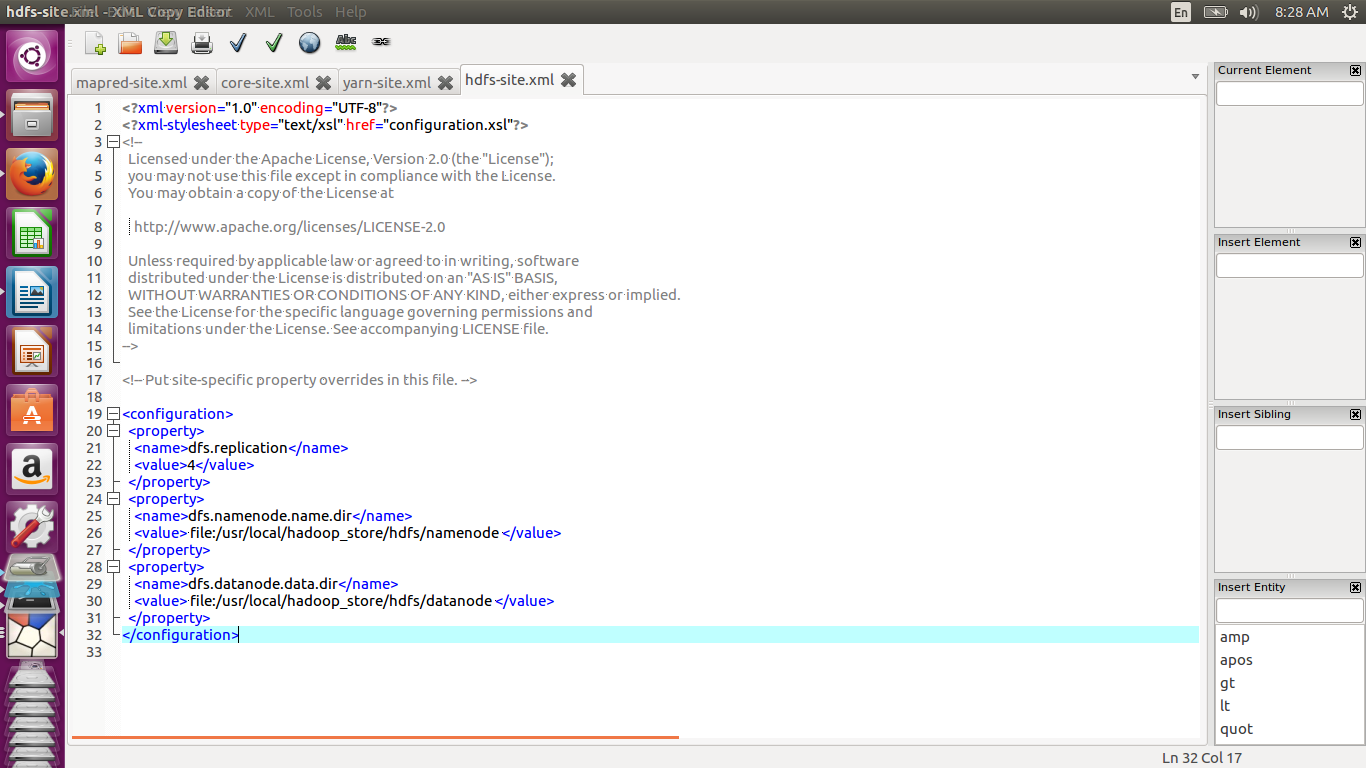
Modify hdfs-site.xml as shown below. The dfs.namenode.name.dir parameter specifies where the namenode stores namespace and transaction logs. The dfs.datanode.data.dir shows where the datanode stores its blocks. The dfs.replication parameter specifies the replication factor for the cluster. For each block stored on HDFS there will be n-1 duplicates across the cluster. If we specify the value as 4, the replication factor is 3 and there will be one original block and two duplicates
<configuration> <property> <name>dfs.replication</name> <value>4</value> </property> <property> <name>dfs.namenode.name.dir</name> <value> file:/usr/local/hadoop_store/hdfs/namenode </value> </property> <property> <name>dfs.datanode.data.dir</name> <value> file:/usr/local/hadoop_store/hdfs/datanode </value> </property> </configuration>
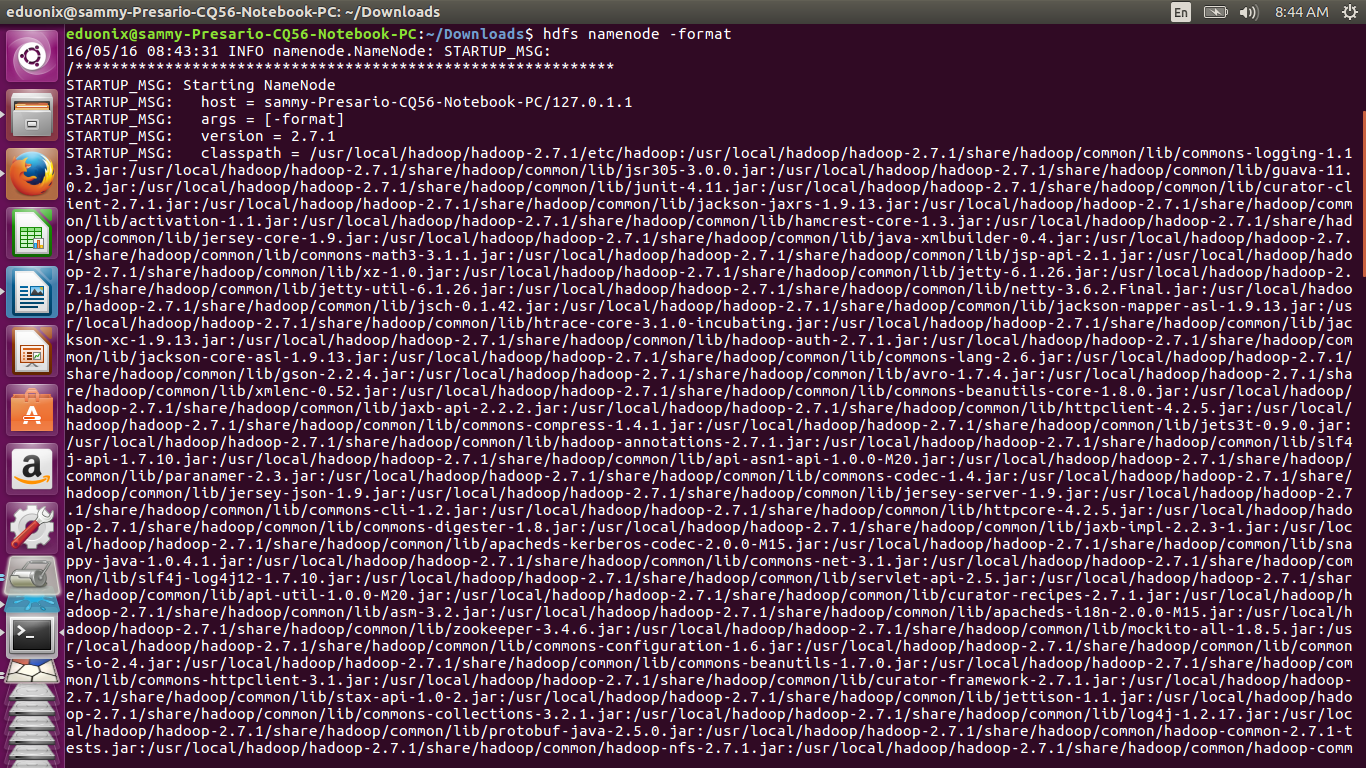
Format the file system by running hdfs namenode -format to initialize the file system
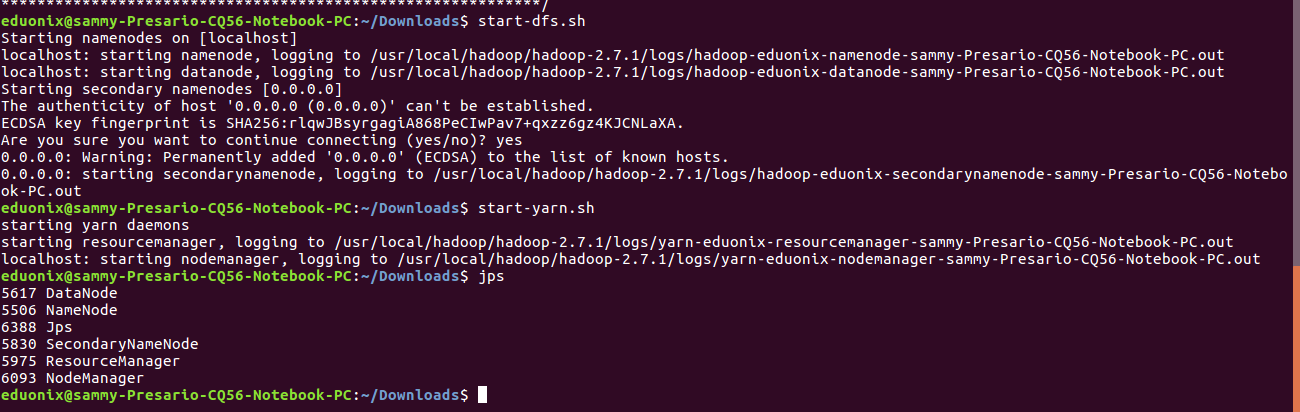
Start the single node cluster
start-dfs.sh
start-yarn.sh
Run jps at the terminal to check all services that are running
jps
The objective of this tutorial was to demonstrate how to set up a single node cluster on Ubuntu. The tutorial explained how to create a user in Ubuntu, how to install java 8, how to install and configure a SSH server. The tutorial also demonstrated how to install Hadoop and use configuration files to control the behavior of Hadoop. Although, the tutorial assumed basic understanding and use of the Ubuntu terminal basic concepts like creating directories, moving directories, extracting archives, assigning permission on folders and navigating the file system have been demonstrated.


{kind=link}
Hi, i can’t start all the processes. Can someone help me please?