

Within the Hadoop ecosystem Hive is considered as a data warehouse. This could be true or false depending on how you look at it. Considering the tool set available in Hive it can be used as a data warehouse but its business intelligence (BI) capabilities are limited. To remedy the weakness of BI capabilities in Hive Simba Technologies provides an ODBC connector that enables BI tools like Tableau, Excel and SAP Business Objects to connect to Hive. Therefore it is good to look at Hive as one of the tools available for BI and analytics, instead of their replacement.
In this tutorial we will take a practical approach of getting data, designing a star schema, implementing and querying the data. This tutorial assumes you have basic understanding of Hadoop and Hive. It also assumes you have Hadoop and Hive installed and running correctly. If not please refer to learn how to set up Hadoop tutorial and learn how to process data with Hive for a review of basic concepts and installation.
When building a data warehouse the star schema offers the best way to store and access data. In this design you create a fact table containing business metrics and dimension tables that store descriptive information about metrics. Because our main objective is to query the data we denormalize the tables in order to provide better query response times.
In this tutorial we will use baseball data that is available here http://www.ibm.com/developerworks/apps/download/index.jsp?contentid=934529&filename=lahman2012-csv.zip&method=http&locale=. Before we begin working on the data it is important to have a good understanding of the data. This data contains observations on baseball batting and pitching
Download the data and extract it so that we can inspect the files available. The data has many csv files which is the equivalent of normalized tables. From these tables we need to denormalize the data so that all columns that contain statistical data from each of the tables into one table that will become our fact table. Then in tables that will be dimension tables we remove any columns that contain statistical information.
Our data warehouse design will have one fact table named fct_players_analysis that will store denormalised metrics. The metrics are stored in normalized tables: AllStarFul, hall of Fame, BattingPost, PitchingPost, FieldingOF, Salaries, AwardsPlayers and AwardsSharePlayers. We will create four dimension tables that will be used to describe metrics stored in the fact table. Our first dimension table is dim_player_bio that stores information on name, birth date and other personal information. Data in the TeamFranchise table will be stored in a dimension table called dim_Franchise. Data in schools table will reside in a dimension table called dim_schools. To support analysis of data by time we will construct a time dimension called dim_year to hold month and year information.
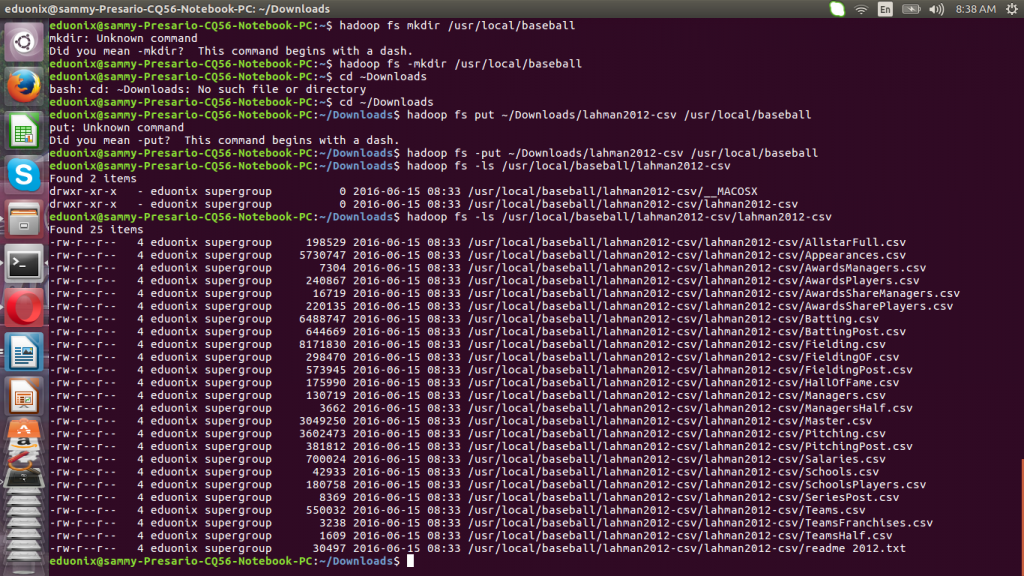
We cannot directly import data from csv files into our star schema. First we need to load the data into have tables from where we can select only the columns required in the data warehouse. This is just data staging to help us get our final data. We make a directory on HDFS and place the csv files there using the commands below.
hadoop fs -mkdir /usr/local/baseball hadoop fs -put ~/Downloads/lahman2012-csv /usr/local/baseball
Explore the directory where the data was load to confirm the files are there.
hadoop fs -ls /usr/local/baseball/lahman2012-csv/lahman2012-csv
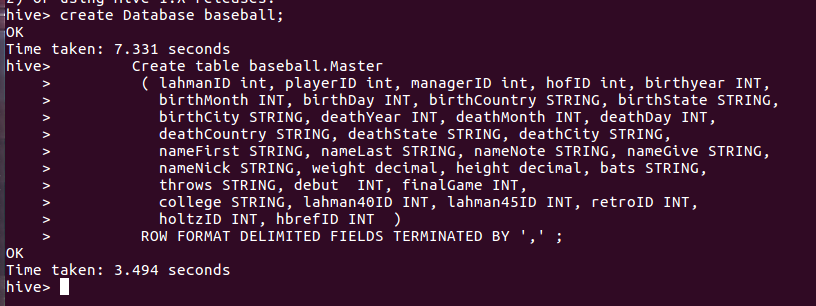
Invoke Hive shell by running hive at the terminal. We will use the shell to create staging database, columns and load data. Due to space limitations only loading of Master.csv will be demonstrated in this tutorial. Create a Hive database baseball and a table Master to hold csv data. You need to repeat this process for all tables identified previously as contributing data to our warehouse.
create Database baseball; Create table baseball.Master ( lahmanID int, playerID int, managerID int, hofID int, birthyear INT, birthMonth INT, birthDay INT, birthCountry STRING, birthState STRING, birthCity STRING, deathYear INT, deathMonth INT, deathDay INT, deathCountry STRING, deathState STRING, deathCity STRING, nameFirst STRING, nameLast STRING, nameNote STRING, nameGive STRING, nameNick STRING, weight decimal, height decimal, bats STRING, throws STRING, debut INT, finalGame INT, college STRING, lahman40ID INT, lahman45ID INT, retroID INT, holtzID INT, hbrefID INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
Once the table to hold the data has been created we can load Master.csv data into it.
LOAD DATA INPATH “/usr/local/baseball/lahman2012-csv/lahman2012-csv/Master.csv” OVERWRITE INTO TABLE baseball.Master;

With all csv tables that will contribute data to our data warehouse loaded we can go ahead and create the data warehouse tables. We create a database playerstats to hold our dimension and fact tables. The query below will create a dimension table dim_Player and load it with relevant data from Master table.
Create database baseball_analysis; create table baseball_analysis.dim_Players AS SELECT lahmanID int, playerID int, managerID int, hofID int, birthyear INT, birthMonth INT, birthDay INT, birthCountry STRING, birthState STRING, birthCity STRING, deathYear INT, deathMonth INT,deathDay INT, deathCountry STRING, deathState STRING, deathCity STRING, nameFirst STRING, nameLast STRING, nameNote STRING, nameGive STRING, nameNick STRING, weight decimal, height decimal, bats STRING, throws STRING, debut INT, finalGame INT, college STRING, lahman40ID INT, lahman45ID INT, retroID INT, holtzID INT, hbrefID INT FROM baseball.Master... ;
Using this approach we load all csv files into staging tables then query staging tables for columns relevant to the data warehouse. The fact table and dimension tables are populated with data using this iterative approach.
This tutorial introduced Hive as a platform that can be used to build a data warehouse. The star schema was introduced and the concept of a star schema consisting of fact tables and dimensions was explained. The baseball data was described and the star schema that will be used to support queries on that data was introduced. Creating databases in Hive, tables and loading data was demonstrated. Finally querying loaded data was shown.


{kind=link}