

Sqoop is a tool in the apache ecosystem that was designed to solve the problem of importing data from relational databases and exporting data from HDFS to relational databases. Sqoop is able to interact with relational databases such as Oracle, SQL server, DB2, MySQL and Teradata and any other JDBC compatible database. The ability to connect to relational databases is supported by connectors that work with JDBC drivers. JDBC drivers are proprietary software licensed by the respective system vendors so Sqoop is not bundled with any JDBC drivers. These need to be downloaded and copied to $SQOOP_HOME/lib where $SQOOP_HOME is the directory Sqoop is installed.
A configured set up of Hadoop is required for installation of Sqoop. If you have not installed Hadoop, please refer to the Ubuntu Tutorial – learn how to set up a single node Hadoop cluster.
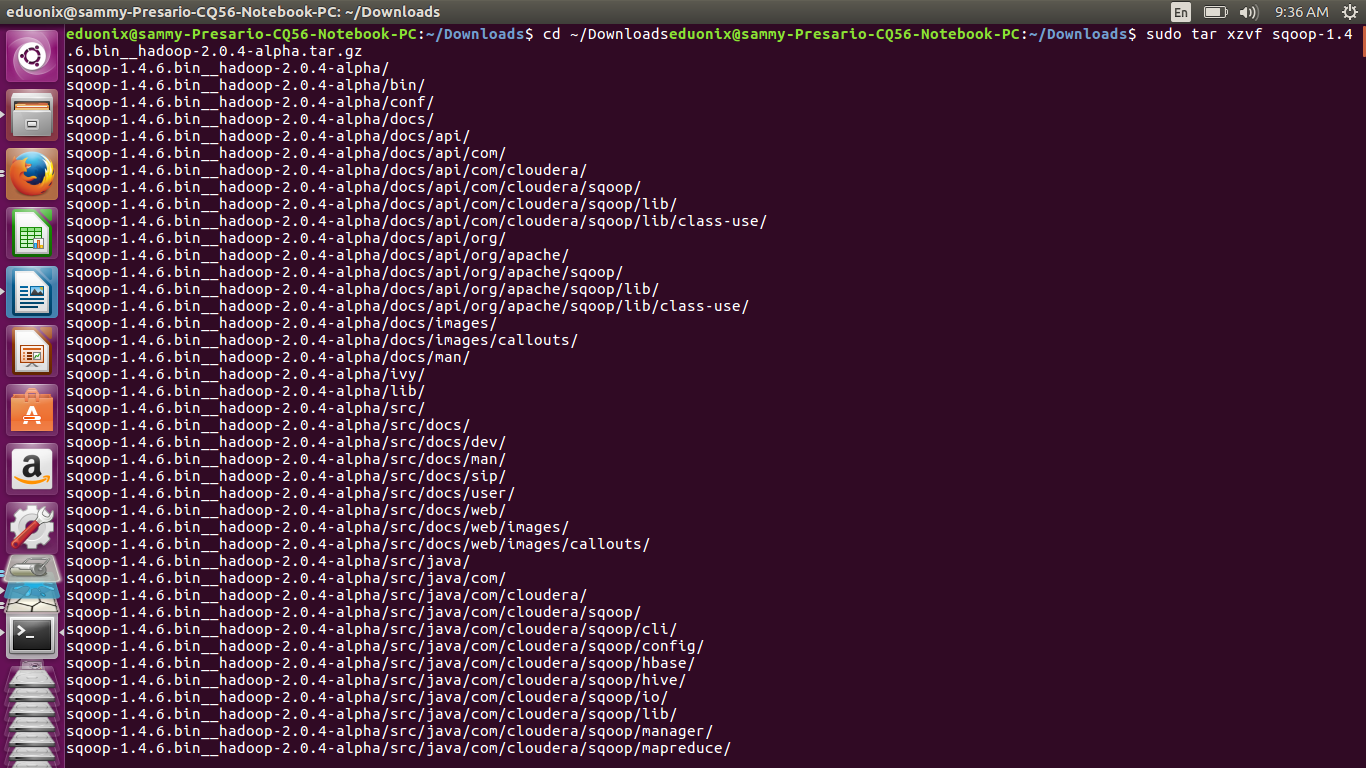
Download sqoop, unzip it and move it to an appropriate directory using the commands below. If wget returns an error just navigate to sqoop website and download it then extract and move it.
cd /usr/local
wget
sudo tar –xzvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
sudo mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha /usr/local/sqoop
sudo chown -R eduonix /usr/local/sqoop
![]()
Open .bashrc file in a text editor by running gedit ~/ .bashrc and add the lines below.
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
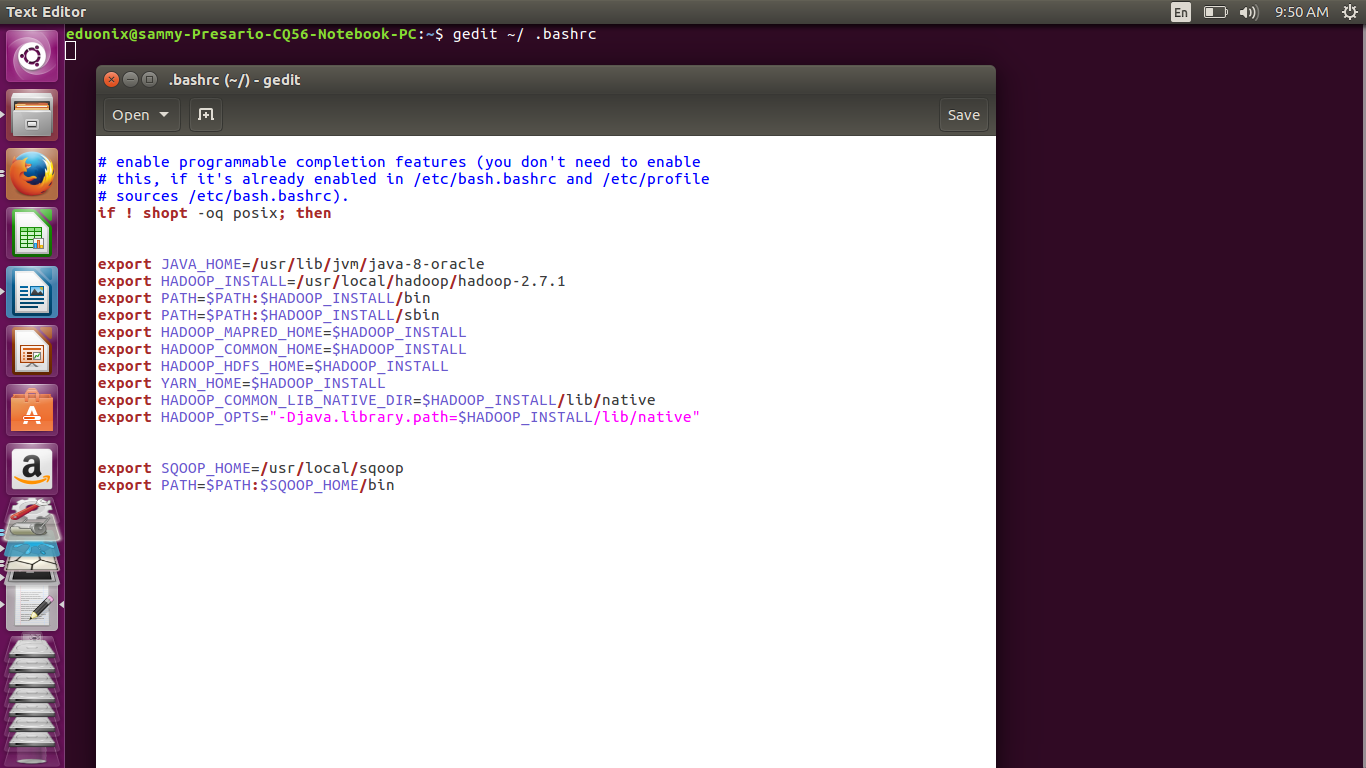
Save .bashrc and reload it by running source ~/.bashrc
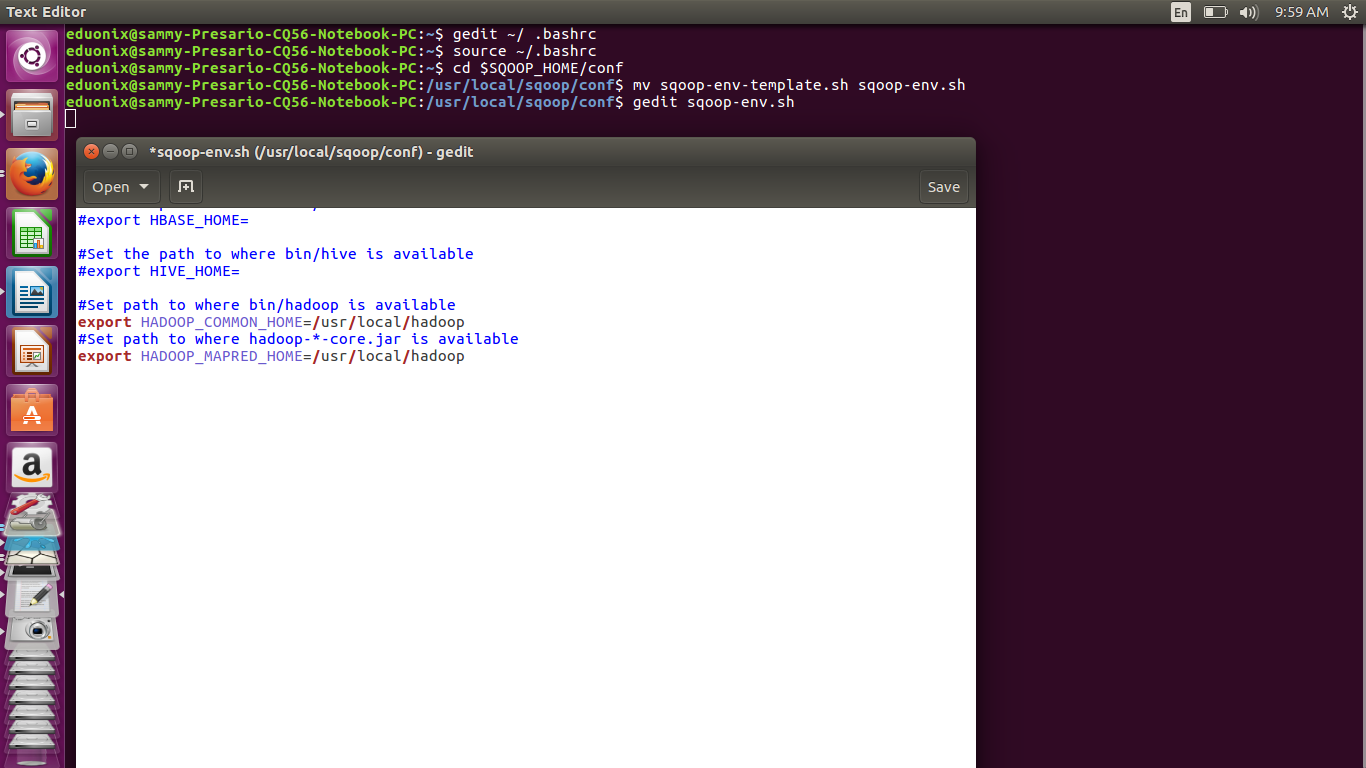
Configure sqoop by moving to $SQOOP_HOME/conf and editing sqoop-env.sh. Before editing sqoop-env.sh you need to make a copy from the provided template
cd $SQOOP_HOME/conf
mv sqoop-env-template.sh sqoop-env.sh
Open sqoop-env.sh and add the lines below
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
Check if sqoop has been correctly installed by running sqoop version at the terminal
In this tutorial, we will use MySQL to demonstrate how data is imported from a relational database to HDFS. If MySQL is not installed, run the command below to install it and set root password to @Eduonix.
sudo apt-get install mysql-server
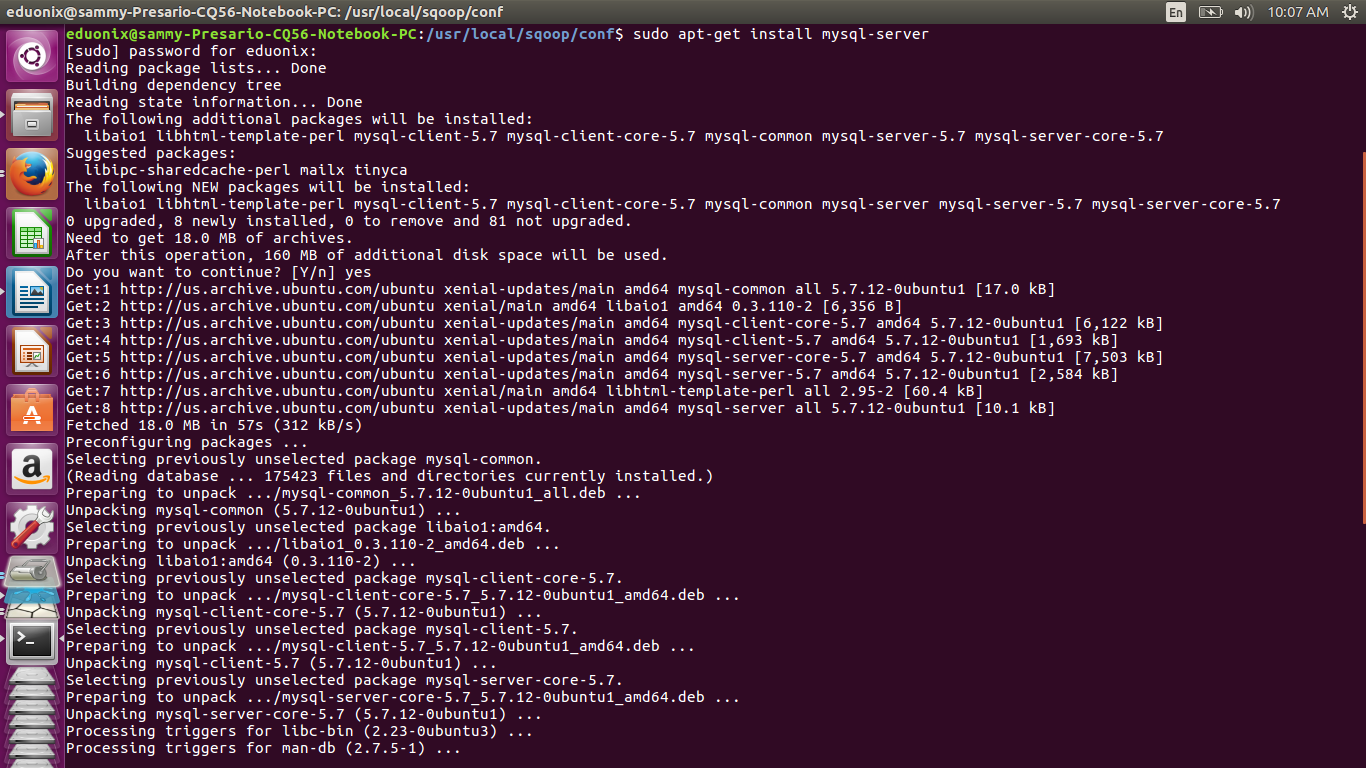
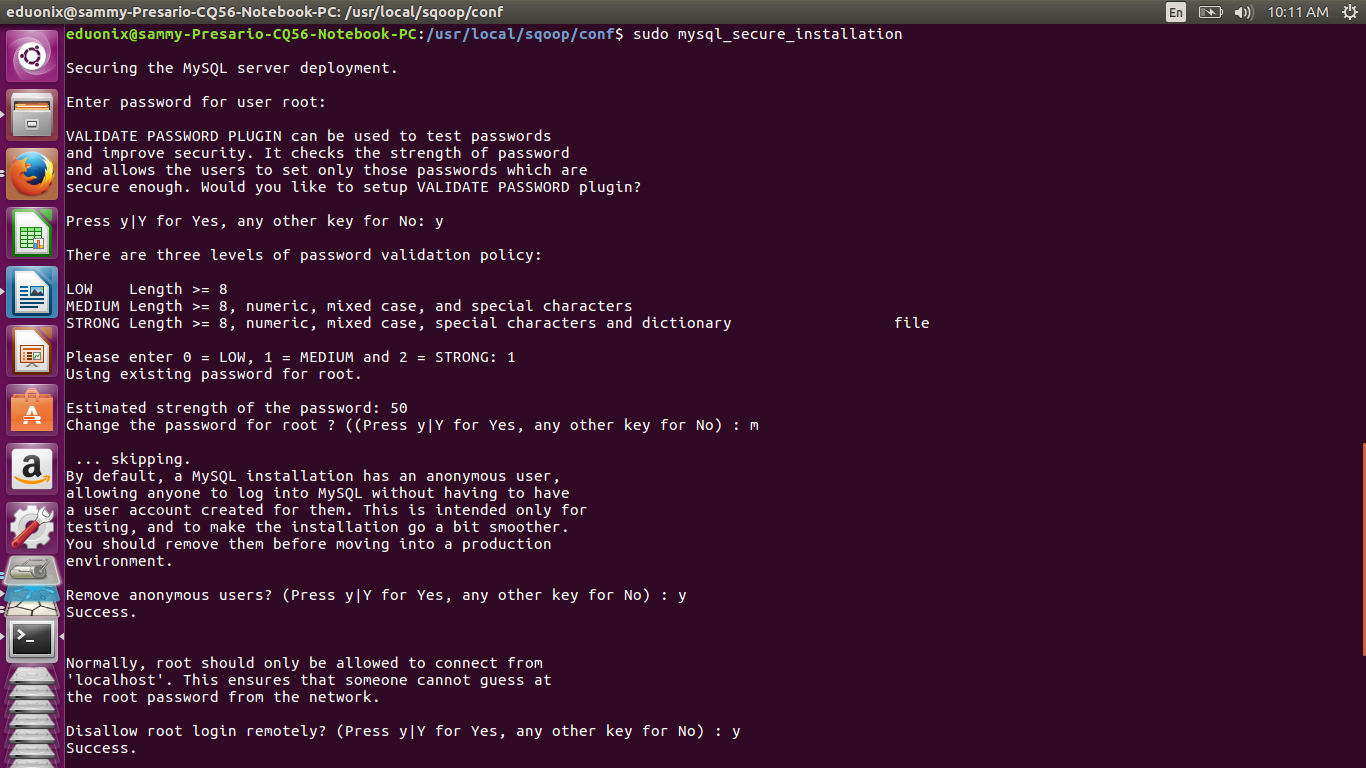
This will install MySQL using default settings. Such a setup is for demonstration purposes only and should not be used for production. Run the command below to address some security concerns in a default installation.
sudo mysql_secure_installation
Download and extract the sakila database. If wget returns an error, just download the sakila-db.tar.gz directly to the downloads directory.
cd /usr/local
wget http://downloads.mysql.com/docs/sakila-db.tar.gz
sudo tar xzvf sakila-db.tar.gz

Using the MySQL command line client, connect to server by running this command at the Ubuntu terminal
mysql -u root -p
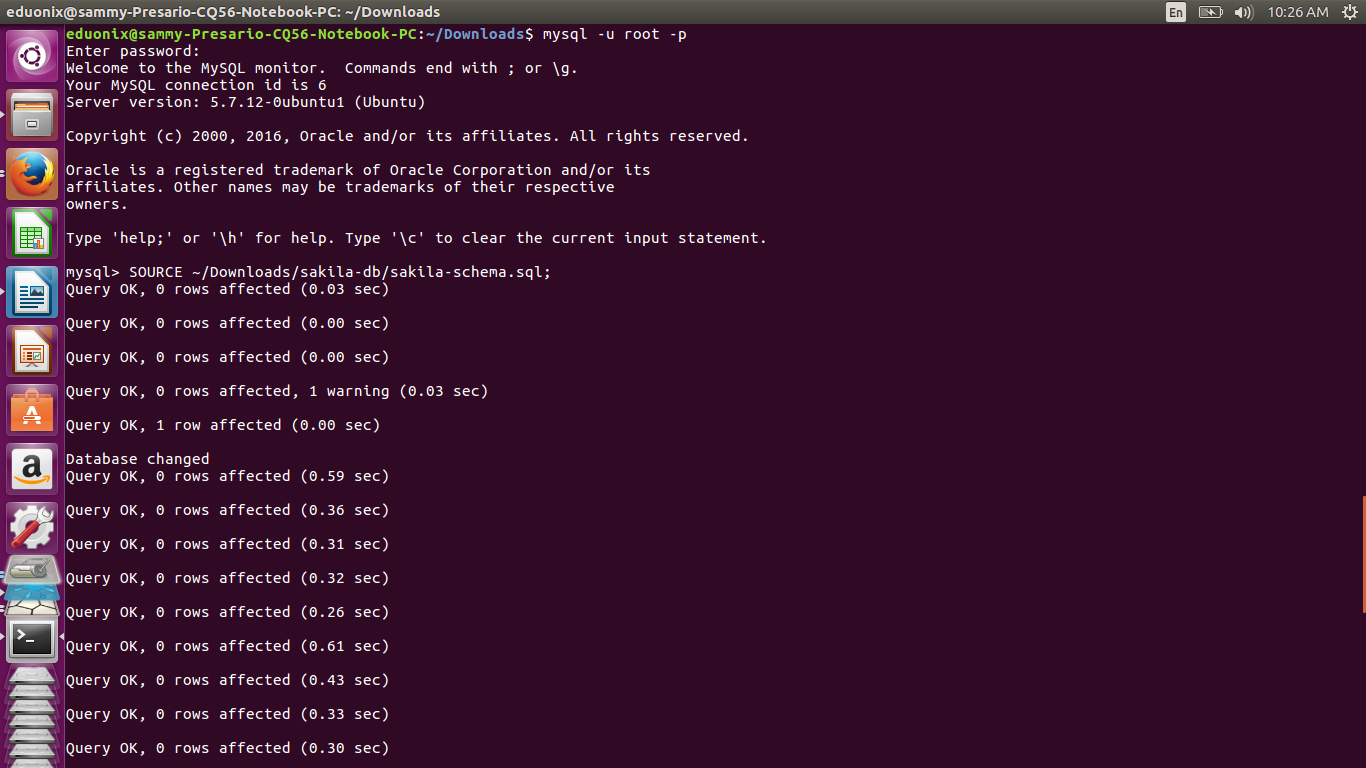
Run sakila-schema.sql to create the database structure
SOURCE ~/Downloads/sakila-db/sakila-schema.sql;
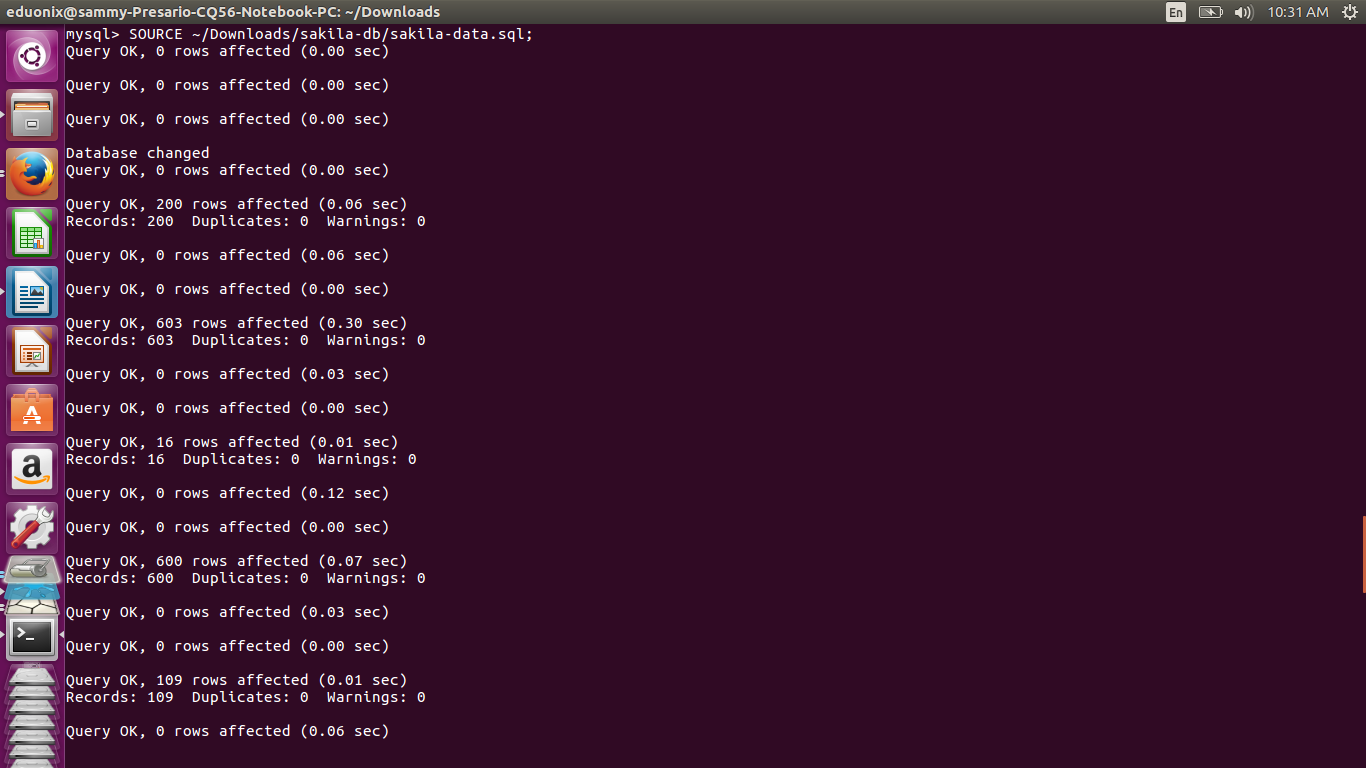
Load data into the database by running the sakila-data.sql script using the command below
SOURCE ~/Downloads/sakila-db/sakila-data.sql;
Download MySQL JDBC drivers from https://dev.mysql.com/downloads/file/?id=462849 , you will need to register if you have not already.
Move into the directory where the drivers were downloaded, extract and copy them to lib directory under sqoop
Once sqoop is installed and configured we are ready to explore the tools it offers. Sqoop has tools to import individual tables, import a set of tables, and export data from HDFS to relational databases. These are the tools we will be looking at in this tutorial. It has other tools for: importing data from a mainframe, validating imported or exported data, creating and saving jobs that remember parameters.
Sqoop import requires a connection string that includes a URL pointing to the database, a valid MySQL user name, password and the database to be imported. These values can be passed at the command line or specified in an options file. Values that don’t change with every invocation are specified in an options file and the other values are passes at the command line. Create a text file in a directory of your choice (/usr/local/options/import.txt) and add the lines below.
import --connect jdbc:mysql://localhost/sakila --username root
This specifies we would like to connect to sakila database using the root user. Replace these values with the database you would like to connect to and your user name. With the options file in place, we can invoke Sqoop using the command below to select table address. The –table parameter is used to specify the table or view to be imported.
sqoop --options-file /usr/local/options/import.txt –P @Eduonix --table address
Sqoop provides secure and insecure ways of passing a password. A password file is a secure way of providing a password while the -password or –P parameter is an insecure way of providing a password. In our case we will just use the –P parameter to prompt for a password.
Once we run the command, all columns in the address table will be imported into HDFS. If we don’t want to import all the columns, we can specify the columns to import using the –columns argument. For example, using the options below we can import only postal_code and phone columns only. The column list should be separated with commas and enclosed with double quotes.
sqoop --options-file /usr/local/options/import.txt –P @Eduonix \
--table address –columns “postal_code,phone”
The data selected can be further narrowed by an SQL where clause using the –where argument. For example, the command below will select data where postal code is 1001.
sqoop --options-file /usr/local/options/import.txt –P @Eduonix \
--table address --columns “postal_code,phone” --where “postal_code = 1001”
Instead of specifying table, columns and where clause you can provide a SQL query using the –query argument. When using a SQL query to import data a destination directory has to be specified. This is demonstrated below
sqoop --options-file /usr/local/options/import.txt –P @Eduonix \
--query ‘SELECT postal_code phone FROM address WHERE postal_code = 1001’ \
-m 1 --target-dir usr/local/
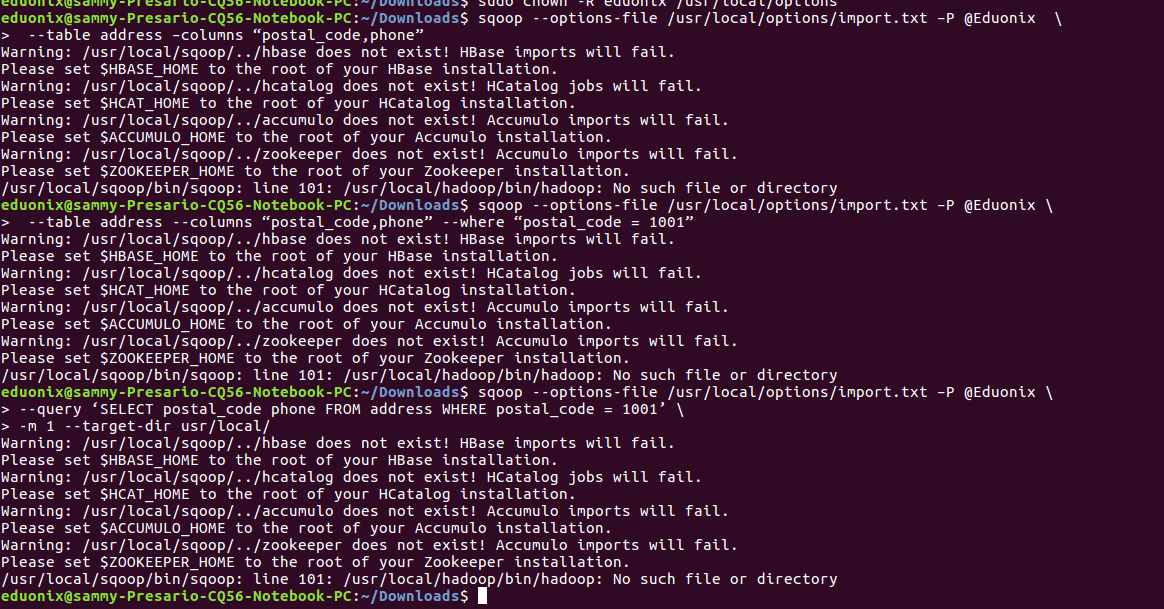
Sqoop gives warnings showing any attempt to use Hbase, Accumulo, Hcatalog, and Zookeper will fail because their parameters have not been set. We are not using these to import data into MySQL so we can ignore them for now.
Sqoop imports data in parallel and you use the –m argument to specify the level of parallelism, the default value is 4. When importing data in parallel, a criteria to split the workload is required. The primary key is identified and used by default. For example, if we have a primary with minimum value of 1 and a maximum value of 40000 and we have set a parallelism level of 4. Sqoop will run 4 tasks each operating on a range of data. One process will operate on the data in 1 to 10000 range, another process will operate on the the 10001 to 20000 range, another process will operate on 20001 to 30000 and another process will operate on the 30001 to 40000 range.
When importing data Sqoop will correctly map SQL data types to java types. However, this can be overridden using –map-column-java parameter by specifying column and data type. For example, we can specify that postal_code and phone be imported as integers by adding as an argument
--map-column-java postal_code = integer, phone = Integer
If you import data once and you only need to import new data since the last import Sqoop provides two ways to do so. The append mode is used when there is an incremental addition of rows. A column that contains the row id is specified using the –check-column argument. This column is examined and only rows with a value greater than –last-value are imported.
When you would like to capture changes that result in an update where updates are captured in a timestamp you use the lastmodified mode. You specify the column containing the timestamp as –check-column and only rows with a value more recent than –last-value are imported. By default data is imported as delimited text.
When you are interested in importing all tables from a database into HDFS you use import-all-tables tool. To use this tool, every table must have a single-column primary key, all columns of each table must be imported, a splitting column must be specified and a where clause conditions cannot be used. To import the sakila database we would use the construct below
sqoop import-all-tables --connect jdbc:mysql://localhost/sakila –P
This tutorial has demonstrated the role of Sqoop in the Hadoop ecosystem as a mechanism for bringing in data from relational databases. This tutorial has shown how to install and configure Sqoop. It has shown how to get data from a table and use the where clause to filter data. It has also shown how to import an entire database from MySQL into Hadoop.


{kind=link}