

Apache Mesos – An overview
Apache mesos is an open source cluster management kernel based system. It is built on same principles as Linux kernels but at different level of abstraction. Mesos kernel runs on every machine and provide same application interface for running applications like hadoop, spark and elastic search as well. Apache Mesos use API’s for resource management and task scheduling across various datacenter for cloud systems and other data warehousing environment. Some salient features for apache mesos are, its capability of being scalable from one node to 10000 nodes, fault tolerant: using master slave relation that uses zookeeper. Linux has a feature of Dockers and containers; Apache Mesos also has facility that supports Dockers and containers. The prime feature of apache mesos is the ability of parallel application development, it supports the development languages like java, python and c plus plus.
Benefits of Apache Mesos
- Clusters are considered as collection of hosts.
- Machines are divided into smaller VM’s for better allocation of resources.
- Apache mesos maximize utilization rate, it also reduces latency rate for data updates and sync with data rates.
- We can run multiple hadoop versions, spark, heroku and many more.
- Easy integration with other frameworks and enabling newer kinds of apps.
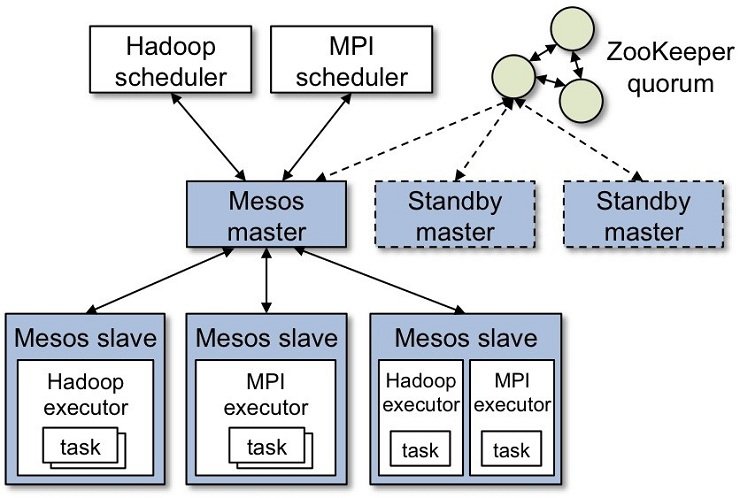
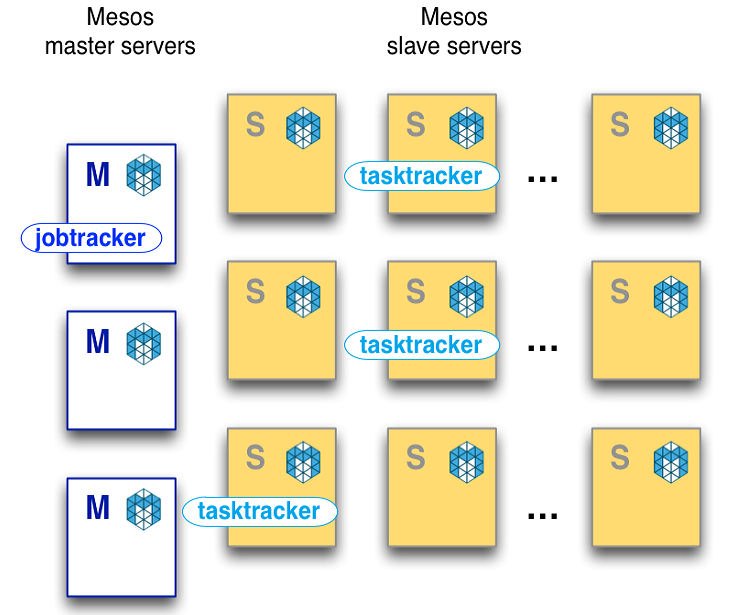
Launching an Apache Mesos Cluster
The prominent advantage of running a hadoop cluster on top of mesos enables us sharing your existing resources in conjunction with other systems for higher resource utilization. Mesos consist of set of master nodes and a set of slave nodes. Some systems are setup differently than others and certain tools might be unavailable.
Verifying the cluster up and running
Navigate to web browser at here we are running a total of 6 clusters three master mesos machines and three slave mesos machines.
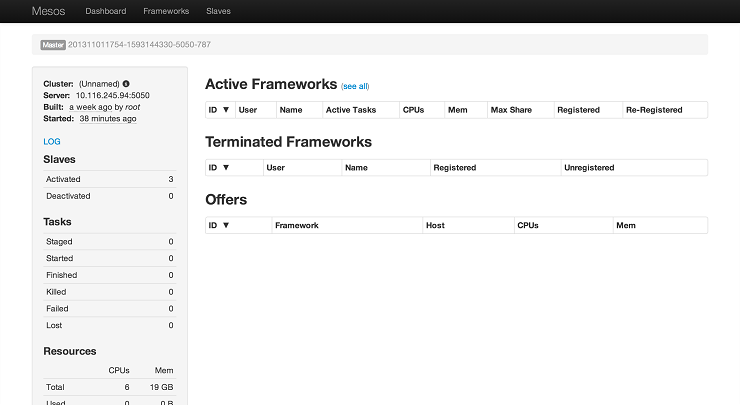
It is assumed that you are running a version of HDFS that is compatible with CDH4. If you don’t have a running version of HDFS then you have to first install the HDFS from Cloudera’s CDH tutorial.
Now using SSH to login in one of the machine running mesos master
Running apache hadoop on Mesos i.e. is also referred to HOM hadoop on mesos requires downloading some of the supported mesos libraries that consists of a scheduler for managing job tracker, an executor for launching task tracker in conjunction with some simple API for hadoop configuration. Going to the lib directory where the files are downloaded, next task is to download the hadoop or mesos extension libraries and extensions that are packed in JAR (Java Archive). As we will proceed, the contents of lib directory will automatically be loaded by hadoop class-loader. We also need hadoop/ mesos driver package that is required by every java application that is integrated directly with mesos.
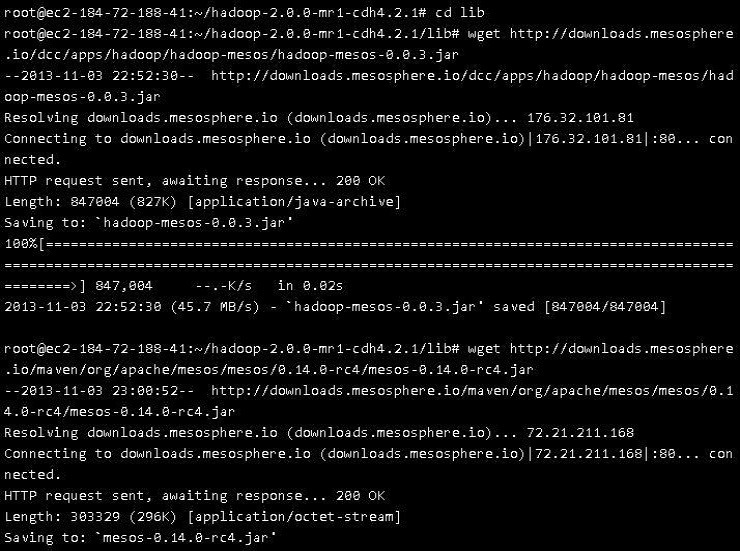
Changing the configuration files accordingly
Now all set, we are ready to modify the configuration files, making sure that hadoop and Apache Mesos can be integrated there are only two files that needs to be modified inside hadoop folder there is one conf directory where all the configuration files need to be modified. We are interested in modifying only two files, one is core-site.xml and another one is mapred-site.xml. Replace these files with some configuration parameters. But before modifying these two configuration files we need to know that on which machines we want to run JOB Tracker so as to have a regular synchronization with slave machines. For this we need to know the IP addresses and two available ports of the machines as well as IP address of the machine running NAMENODE. You can easily get the Ethernet address of your machine using IFCONFIG command. The next step is to select any two ports that are not engaged with any process for running MAPREDUCE framework, in this example we have taken port number 7677 and 7676, but the choice is yours to take any two ports that are available for use. You can also check whether ports are available or not by using NETSTAT command and “AWKING” all the ports with 767. Here is the example of how to perform this operation.


Editing mapred-site.xml and core-site.xml
Now start editing these two files, you can use any editor to modify the configuration files, we have used VIM editor to modify the files
vim mapredsite.xml
There are basically 4 key-value pairs that needs to be modified and inserted in to the XML file
Mapred.job.tracker
Insert the IP address and port number where you want to bind the hadoop remote procedure call. In other words we need task tracker to inform where they can find their master process i.e. job tracker.
Mapred.job.tracker.https.address
Again you need to specify the IP address and port number (sometimes refer to socket address)
Mapred.mesos.master
This configuration address is used to identify one or more than one mesos master nodes. Whenever the hadoop daemons start i.e. job tracker and task tracker they will attempt to find the mesos master node.
Mapred.mesos.executor.uri
This address points to the location of tar archive file that contains the modified XML file and some other necessary files that are needed to launch a task tracker.
![]()
Editing core-site.xml
You just need to fill in fs.defaultFS and fs.default.name, this should be identical and always point towards name node location.
Now that you have modified these two files you need to repackage the hadoop files so that it can be distributed across the cluster.
Tar czf command will repackage the hadoop files and then files will be uploaded to HDFS so that mesos slave daemon can automatically download and access it.
Next step is to make mapreduce the owner of hadoop directory so that job tracker can create any directory for logging type. We can do this by running following command
Sudo chown -R mapred:hadoop ./hadoop-2.0.0-mr1-chd4.2.1
Before starting hadoop daemon make sure that hadoop mesos extension must be able to find its native library called as libmesos.so
Conclusion
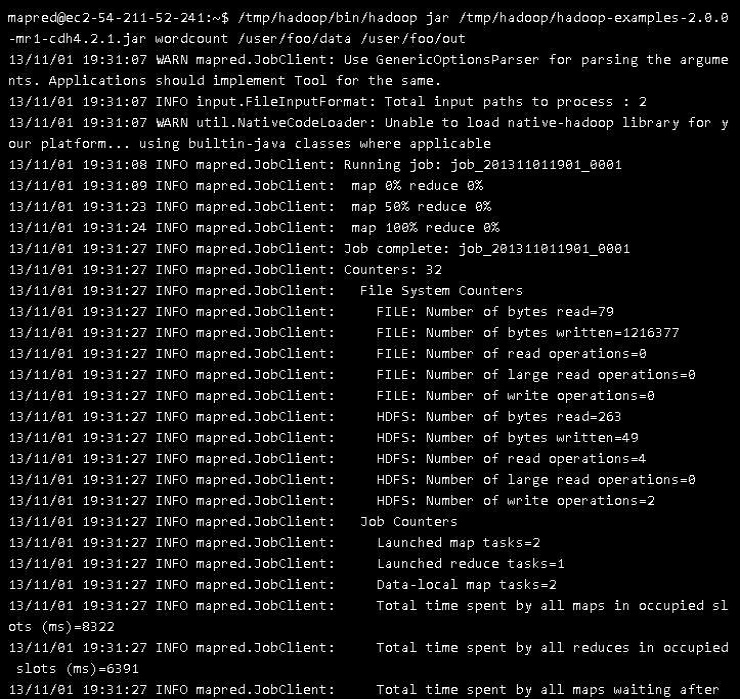
This way we can configure Apache mesos in conjunction with apache hadoop and if we want to test the proceeding than we can run a word count program for testing purpose, if everything goes perfectly fine then it should show the output like this-:
Apache mesos is very much helpful in managing the cluster nodes and maintaining a load balancing among various data sequences and easily integrated with tools like hadoop and other cloud based modules.


{kind=link}