

Welcome to part three of About Text Processing Tools topic.
The AWK Tool
The awk command uses a set of user-supplied instructions to compare a set of files, one line at a time, to extended regular expressions provided by the user. Actions are then performed on each line that matches the criteria. The pattern matching of the awk command is more general than that of the grep command, and it allows the user to perform multiple actions on input text lines. awk also allows the user to use variables, numeric functions, string functions, and logical operators.
AWK as Field Extractor
Among its many uses, the awk utility can be used to achieve the same function as the cut command as a field extractor.
Examples
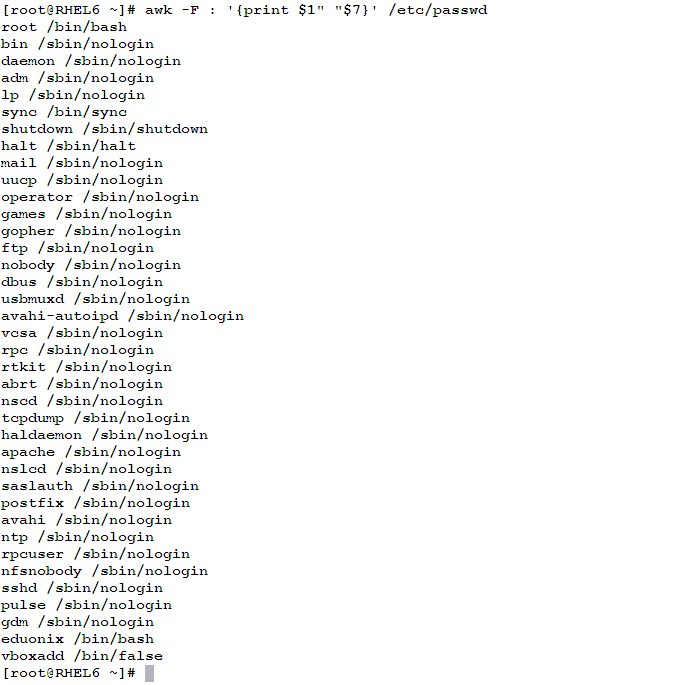
- To extract the first and seventh fields from the /etc/passwd file (that uses colons : as field separators), use the following command:
- Consider the output of the command free –o
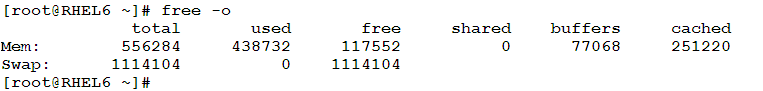
The command displays memory and swap utilization statistics. Of this output, we need to extract the physical memory total size and current utilization. To do, we should extract the second and third columns of the line started with Mem:
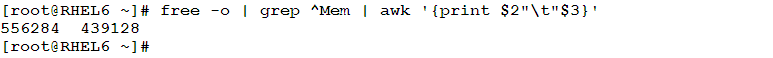
AWK as GREP
Now, we are going to see how to use awk as a pattern matching tool (like grep). When using awk, the pattern being searched for is enclosed within pair of ‘/ /’
Examples
- To get any line in the /etc/passwd file that contains the word eduonix:
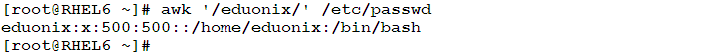
- To search the /etc/passwd file for lines NOT containing the nologin string:

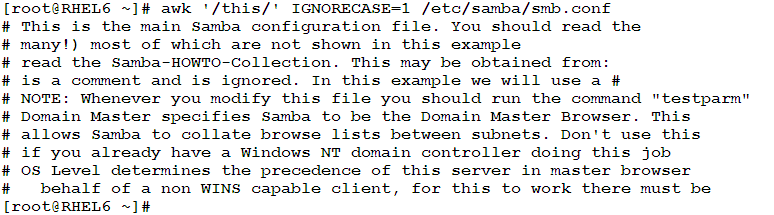
- To search for a pattern ignoring the case:
Generating Text Statistics
To get a count of the number of characters, words, and lines in one or more files (or input text coming from another command output), the wc (word count) is used.
Syntax
wc –l [FILE]… Counts lines
wc –w [FILE]… Counts words
wc –c [FILE]… Counts characters.
Examples
- To print the number of lines in both /etc/passwd and /etc/group files:
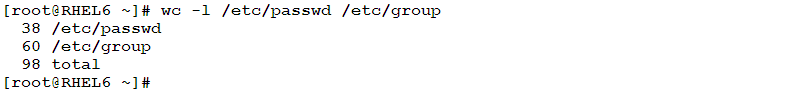
- To print the number of characters in both files:
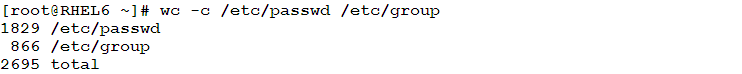
- To print the number of words in the same files:
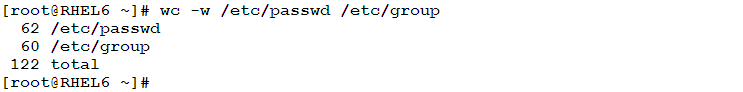
- To print all the statistics for a file:

Sorting Text
Sometimes, you need to sort data either alphabetically or numerically. For this purpose, Red Hat has the sort command.
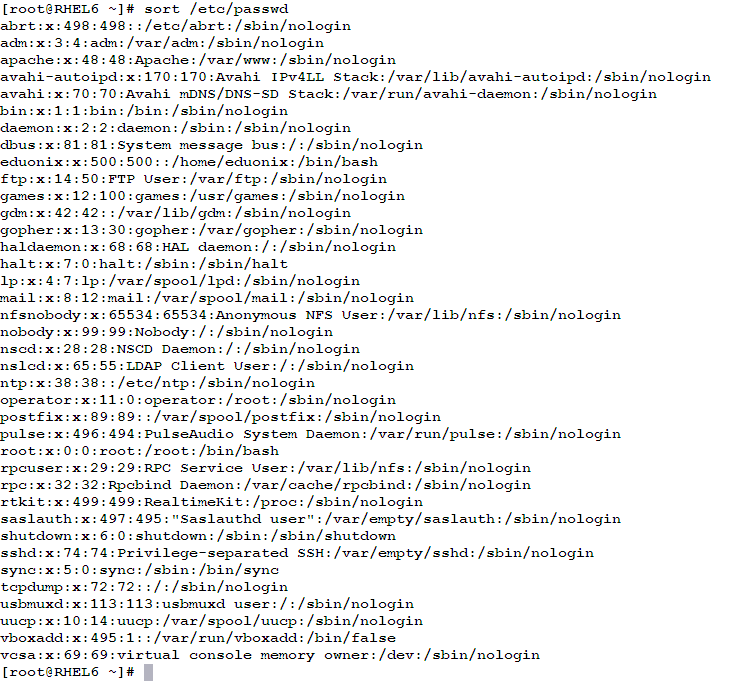
- To sort the /etc/passwd file:
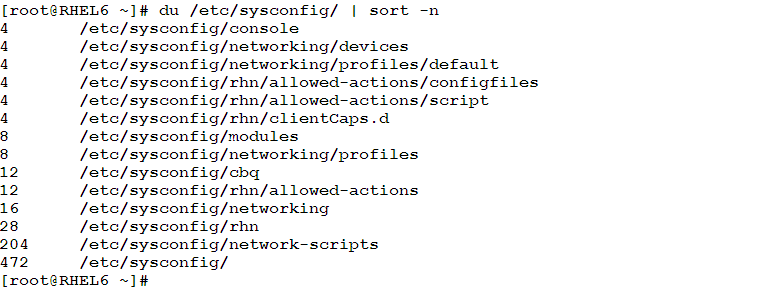
- To display the disk usage statistics of the /etc/sysconfig directory and its sub-directories sorted in ascending order according to size:
- To reverse the sort, use the –r option:

- To sort text discarding duplicates, use the –u options:Consider the file:

When sorted, duplicates appear close to each other:

To get rid of the duplicates:
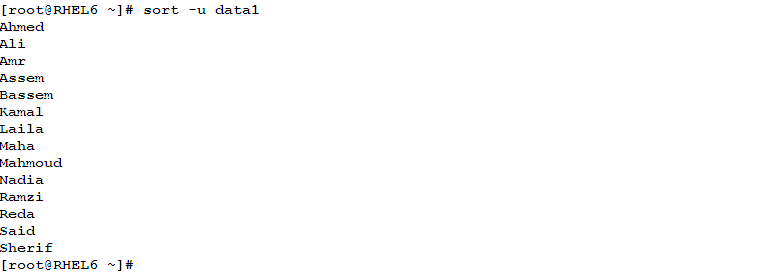
Translating and Converting Text
In some cases, you may need to translate, convert, or squeeze characters of the input text. The tr command helps you achieve what you want. It can be used to translate, delete, and squeeze characters coming from the standard input, and prints the result to the standard output.
Common uses of the tr Command
- Converting uppercase letters to lowercase and vice versa.
- Squeezing (deleting) repeated characters.
- Translating white spaces to tabs and vice versa.
- Converting a multi-line text input into one line.
- Deleting all the appearances of one or set of characters.
Syntax
The general syntax of the command is:
tr [OPTION] SET1 [SET2]
Examples
- The following shows how to convert all characters in a file to uppercase letters, and print the results to the screen:

- The following illustrates how to use tr to squeeze repeated white spaces in an input text:
Consider the following:

Let’s see the squeezed version:

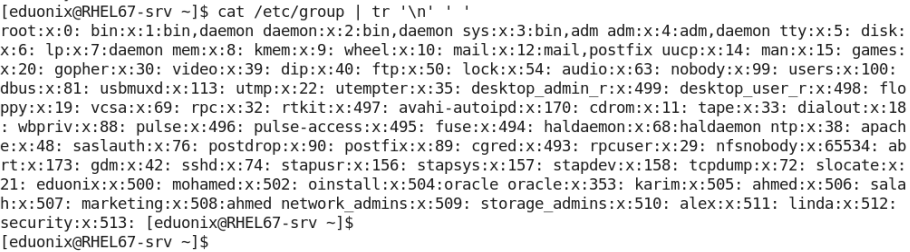
As you could see, piping the input text into the command tr –s ” ” deletes all extra white spaces. - The following command compresses a multi-line text to be one line, by converting the new line character into a normal white space:
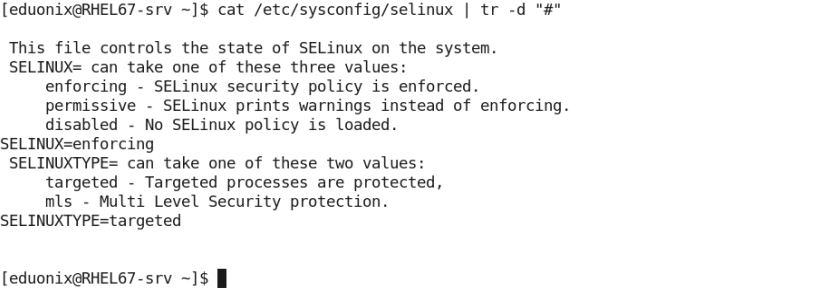
- The following prints the /etc/sysconfig/selinux file with all comments uncommented (by removing the hash # character):The file originally looks like this:

Now, print it with all appearances of the hash character removed:
Summary
The awk utility can be used as a replace to the grep command as a pattern matching tool, and to the cut command as a field extractor tool.
The word count wc command can be used to count lines, words, and characters in one or more files.
As its name tells, the sort command can be used to sort data either alphabetically or numerically.
The tr command can translate, delete, and squeeze characters of input text.
For now, that is it for Text Processing. Next is another topic. See you.


{kind=link}