
In this chapter, we are going to learn about the concept of Data Modelling as well as various relationships that we can use to model data in MongoDB. Let’s quickly review the concept of data modelling, which we have already explained in the previous chapter of this tutorial series.
Concept of Data Modelling
In MongoDB, the data structure is very flexible as the schema that has documents in the same collection can hold different set of fields or structure. Also, the common fields are capable of holding different types of data in a collection’s documents. The following are the few considerations to keep in mind while we design a Schema in MongoDB.
- First and the foremost thing is to design the schema according to the user requirements.
- Identify the objects that can be used together and club them into one document. If they cannot be used together, then separate them and make sure that there is no need of using joins.
- Depending on the frequency of the use cases, we should optimize our schema.
- We can do complex aggregation in our schema.
- In MongoDB, compute time is given higher priority over the disk space. Therefore, we can duplicate the data but up to a certain limit.
- Joins are recommended on write operations and not on read operations.
Relationship in MongoDB
Relationship is an approach practised during data modelling which represent the way various documents are logically related to each other. There are two approaches to model relationships in MongoDB. They are Embedded and Referenced approaches of relationship. These relationships could be of 1:1 (one to one), 1:N (one to many), N:1 (many to one) or N:N (many to many) type.
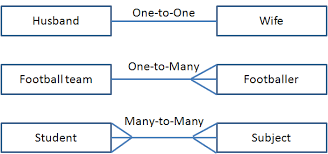
Example
Let’s consider an example of 1 : N (one to many) relationship, where a single blog may have multiple comments. Therefore, a single blog with two or more comments corresponds to 1 : N relationship. The following will be the document structure for blog and comment.
Document structure for a Blog
{
heading: 'Life of an awesome girl',
publish_date: '2016-11-27',
description: 'An awesome girl...',
permalink: 'http://awesomeblog.com/2016/12/life-of-an-awesome-girl',
categories: ['Make', 'Travel', 'Fiction', 'girl'],likes: 56,
}
Document structure for a Comment
{
name: 'Mohit',
email:'[email protected]',
phone:'123456789',
message:'awesome blog',
creationDate:'2016-11-27',
like_flag:true
}
Embedded Data Modelling in MongoDB using one to Many Relationship
In the embedded approach to model relationship, we will embed the comment document inside the Blog document as shown below.
db.DATA_MODEL.save ({
heading: 'Life of an awesome girl',
publish_date: '2016-11-27',
description: 'An awesome girl...',
permalink: 'http://awesomeblog.com/2016/12/life-of-an-awesome-girl',
categories: ['Make', 'Travel', 'Fiction', 'girl'],likes: 56,
comments: [
{
name: 'Mohit',
email:'[email protected]',
phone:'123456789',
message:'awesome blog',
creationDate:'2016-11-27',
like_flag:true
},
{
name: 'Manu',
email:'[email protected]',
phone:'123456789',
message:'I like this blog very much',
creationDate:'2016-11-29',
like_flag:true
},
{
name: 'Appy',
email:'[email protected]',
phone:'123456789',
message:'Simply Awesome',
creationDate:'2016-11-28',
like_flag:true
}
]
}
)
Advantages of Embedded Data Modelling
- In this approach, we can maintain all the data in a single document after establishing a relationship.
- It is easy to retrieve and requires minimum maintenance.
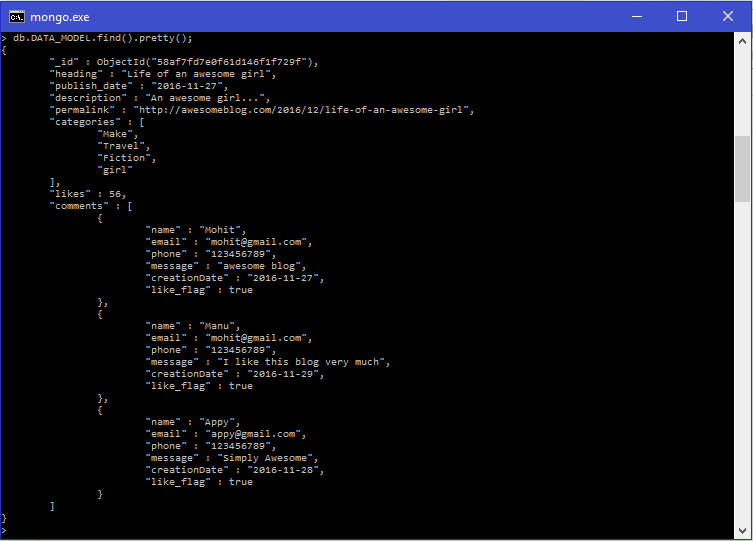
- We can retrieve whole document by simply executing a single query as shown below.
> db.DATA_MODEL.find().pretty();
Disadvantages of Embedded Data Modelling
- When we have multiple documents to embed which keeps on growing in size, then it may deteriorate the overall read and write performance.
Referenced Data Modelling in MongoDB using one to Many Relationship
In the referenced approach to model relationship, both blog and comment documents will be maintained separately, but the blog document will contain a field which will reference the comment document’s id field as shown below.
> db.REFERENCE_MODEL.save ({
name: 'Mohit',
email:'[email protected]',
phone:'123456789',
message:'awesome blog',
creationDate:'2016-11-27',
like_flag:true
});
> db.REFERENCE_MODEL.save ({
name: 'Manu',
email:'[email protected]',
phone:'123456789',
message:'I like this blog very much',
creationDate:'2016-11-29',
like_flag:true
});
> db.REFERENCE_MODEL.save ({
name: 'Appy',
email:'[email protected]',
phone:'123456789',
message:'Simply Awesome',
creationDate:'2016-11-28',
like_flag:true
});
> db.REFERENCE_MODEL.find();
{ "_id" : ObjectId("58af83ffe0f61d146f1f72a0"), "name" : "Mohit", "email" : "[email protected]", "phone" : "123456789", "message" : "awesome blog", "creationDate" : "2016-11-27", "like_flag" : true }
{ "_id" : ObjectId("58af840ce0f61d146f1f72a1"), "name" : "Manu", "email" : "[email protected]", "phone" : "123456789", "message" : "I like this blog very much", "creationDate" : "2016-11-29", "like_flag" : true }
{ "_id" : ObjectId("58af8420e0f61d146f1f72a2"), "name" : "Appy", "email" : "[email protected]", "phone" : "123456789", "message" : "Simply Awesome", "creationDate" : "2016-11-28", "like_flag" : true }
>
db.REFERENCE_MODEL.save ({
heading: 'Life of an awesome girl',
publish_date: '2016-11-27',
description: 'An awesome girl...',
permalink: 'http://awesomeblog.com/2016/12/life-of-an-awesome-girl',
categories: ['Make', 'Travel', 'Fiction', 'girl'],likes: 56,
comments: [
ObjectId("58af83ffe0f61d146f1f72a0"),
ObjectId("58af840ce0f61d146f1f72a1"),
ObjectId("58af8420e0f61d146f1f72a2")
]
});
Advantages of Referenced Data Modelling
- In this approach, the blog document contains the array field comments which contains ObjectIds of corresponding comments.
- We can use these ObjectIds to query the comment documents and get comment details from there.
- It will overcome the performance issue on read and write operations caused due to a large number of embedded documents.
- With the help of this approach, we will require to write two queries. The first query will fetch the comment ids field from the blog document and the second query will fetch the comments from comment collection as shown below.
>var result = db.REFERENCE_MODEL.findOne({"heading":"Life of an awesome girl"},{"comment_ids":1})
>var comments = db. REFERENCE_MODEL.find({"_id":{"$in":result["comment_ids"]}})
Conclusion: –
In this chapter, we have revised the concept of data modelling in MongoDB and explained data modelling using various relationships i.e., 1:1 (one to one), 1:N (one to many), N:1 (many to one) or N:N (many to many) type in the two approaches namely embedded and referenced relationship.


{kind=link}