

Machine learning and deep learning emerged as the next big thing in the 2000s, with the power of revolutionizing the whole information technology sector. Everyone was in fear of losing their jobs because of automation. However, ML existed even back in1958, it truly gained visibility in 2012 after Geffory Hinton and his team came up with the best solutions to implement it. Changes in IT sector work like a game of dominos. A new change happened. And with this new change, several other changes rippled through the IT industry.
Right now every organization is looking forward to riding on this AI or Machine Learning trend. Everyone wants to be part of this story. Organizations have started their planning to launch data-driven products empowered by these technologies. Data-driven products involve various teams within an organization to deploy one single product. The process-driven methodology which automates the deployment process is known as DataOps.
It includes professions like:
- Data engineer
- Data scientist
- Developers
- Data analyst
- And Operations team
The top four teams or professions come under the umbrella of the DATA team of DataOps, and the operations team constitutes for OPs. Data team takes care of the following activities:
- Understanding the requirements of end-users/clients.
- Designing the solution
- Implementing the designed solution
Data engineer who focusses on building efficient pipelines of data for the ease of data analyst and data scientist. Developers mainly focus on the software engineering side of data-driven products

And the operation team mainly cares about:
- Deployment of the solution build by Data team
- Regular security checkups
- Monitoring (taking care of 99% up-time)
- Taking Backups
The Problem That DataOps Solve

To develop a successful data-driven product, the contribution of both teams is equal and very crucial. From the organization’s perspective, they want to build and deploy the product as soon as possible for their end-users.
End-users want to enjoy the new features and updates as early as possible. But it does not happen like that. There are various hurdles in the process. The data and operation team used to work separately in an organization with different goals and stay on different pages.
The operation team gets paid to maintain and stabilize the production environment as much as possible with minimal changes, and the Data team gets paid to build new features as early as they can. A massive gap in between both of the teams arises due to different departmental goals. They go and work in opposite directions. This gap leads to a considerable time gap in integrating the new features. At last, it’s the organization that suffers. How? New users are more likely to switch to the competitors’ products in this meantime. It’s a very big problem for large organizations.
And this is where DataOps comes into the picture. This is the exact problem that DataOps try to solve.
To be more precise, DataOps is not about:
- New technology
- A new programming language which you need to master
- A new framework that you need to learn
Then what DataOps is all about?
It’s more about culture shift within the organization. DataOps is not something you can master; it’s the mindset shift that you need to adapt to bring the change in the organization. It mainly focuses on changing how different teams used to work to build and deploy a data-driven product.
A data-driven product requires both continuous additions of new features and deployment as well. It’s an infinite cycle and a never-ending process. Both teams need to collaborate very well to achieve the common goal of the organization. This is the only way through which a data-driven product can be successful.
DataOps is the philosophy of micro experimentation and a culture shift.
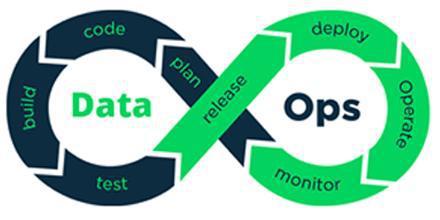
Significance of the Logo of Dataops
The logo(unofficial) of DataOps truly captures the whole development life cycle of the data-driven product by infinity. Infinity signifies that this is a never-ending process and needs continuous contributions from both the data team and the operation team.
 There are three pillars of DataOps:
There are three pillars of DataOps:
- People
- Process
- Product
People
This is an essential part of DataOps. DataOps places people over everything else, be it tools or processes. Teams are the core of any product, and they need to work together to build the product. DataOps ensure that every individual of the team should work only on one specific organizational goal; it does not matter whether he/she is in a data team or operations team. It is to make sure that different groups don’t work only for themselves but for the organization as a whole. There should not be any contradiction between the two teams. If an organization can’t assure this, then they can’t establish the Dataops philosophy in the organization.
Process
The main goal of Dataops is to: Deliver value continuously to the end-users.
If the users are not happy with the changes, then there is no point in doing them. The process aspect of Dataops focuses precisely on this. It ensures to continuously receive feedback from users to build only the required features. DataOps is the engine that fuels the value addition.
Product
The primary end goal of DataOps is to deploy faster and smoothly, and this is where various tools and products come into play. These products come in a lot of varieties ranging from data related to operation related. They help to automate the essential and essential activities of each phase of data-driven products.
Conclusion
DataOps focusses on developing and deploying data-driven applications faster by collaborating different teams together to bring clarity within the team so that all of them can focus on a single organizational goal. With the increasing use cases of ML, automation in data analysis have become inevitable, and DataOps is the way to future.







I love your blog. This all provided knowledge are unique than other python blog.
good explain, keep updating