

Introduction
NLTK is used to access the natural language processing capabilities which enable many real-life applications and implementations. It has been there for quite a while in use by both starters and experts for text analysis. It was designed with the intention to reduce the stress and load that surrounds Natural Language Processing(NLP). It has found its place in the data science industry as there are tons of unstructured data that needs to be cleaned and traversed to extract useful and meaningful business insights along with some other discoveries. NLP makes the process of text analysis quite easy by following these basic steps for any text processing-
- Saving the text into a Vcorpse.
- Converting all the letters in the file to lower case and remove punctuation.
- Removing the stopwords. Custom stop words can also be removed according to the user’s preference.
- Storing the entire formatted text in a Document-Term Matrix(DTM) or Term Document Matrix(TDM)
- Creating a bag of words to find a specific pattern.
Having gone through the basics of NLP and understanding where its uses lie, let’s dive further deep into this game-changing tool and try to figure out what the hype is all about!
What is Natural Language Processing?
In simple terms, Natural Language Processing is a medium of interaction or communication between computers and humans. It includes some predefined algorithms that help in understanding the actions and emotions of a person or entity.
Nowadays, tons of both, structured and unstructured data is getting generated online through social media and other means of communication. The unstructured data amounts for total 95% of the data and remaining is structured data. To handle this growing amount of unstructured data, NLP comes to the rescue as it helps in classifying text and remove the unnecessary stopwords. It accelerates the text processing and helps in normalizing the data along with the desired output which is basically getting a hint of human behaviour and emotions.
For example, sentiment analysis is a classic application of NLP. The emotions attached to a person’s tweet or opinions, whether positive or negative, is effectively expressed with the help of NLP with its inbuilt libraries.

The figure represents a word cloud
NLP has its applications in a variety of fields like spam filtration, news categorization, Named Entity Recognition(NER), paraphrase detection, suggestion answering to some generic questions which are asked randomly in a forum, machine translation, document summarization and many more.
There are a lot of NLP libraries that are useful for speech and voice recognition, language translation and sometimes even used to give suggestions to complete a sentence in emails, articles or blogs.
Some of the libraries that are used for implementing NLP-
- Natural Language Toolkit(NLTK)
- Stanford Core NLP Suite
- Apache OpenNLP
- SpaCy
We will focus on Natural Langauge Toolkit(NLTK) for our analysis.
Natural Language Toolkit(NLTK)-
Natural Language Toolkit was developed in 2001 with the idea of improving text processing and easing the workload related to text analysis. Since its advent, it has been tweaked and leveled up by its loyal supporters and helped to turn it into a capable library under NLP!
Because of its vast community and strong support, NLTK is quite popular and easy to use. It provides an array of text processing modules that are used for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
The following table will make us realize the functionalities related to each NLTK module-
| Language processing task | NLTK modules | Functionality |
| Accessing corpora | corpus | standardized interfaces to corpora and lexicons |
| String processing | tokenize, stem | tokenizers, sentence tokenizers, stemmers |
| Collocation discovery | collocations | t-test, chi-squared, point-wise mutual information |
| Part-of-speech tagging | tag | n-gram, backoff, Brill, HMM, TnT |
| Machine learning | classify, cluster, tbl | decision tree, maximum entropy, naive Bayes, EM, k-means |
| Chunking | chunk | regular expression, n-gram, named-entity |
| Parsing | parse, ccg | chart, feature-based, unification, probabilistic, dependency |
| Semantic interpretation | sem, inference | lambda calculus, first-order logic, model checking |
| Evaluation metrics | metrics | precision, recall, agreement coefficients |
| Probability and estimation | probability | frequency distributions, smoothed probability distributions |
| Applications | app, chat | graphical concordancer, parsers, WordNet browser, chatbots |
| Linguistic fieldwork | toolbox | manipulate data in SIL Toolbox format |
NLTK was introduced with the following goals in mind
- Simplicity
To provide a framework in order to get rid of tedious work-load of text classification and make this process more intuitive. - Consistency
To provide a framework with consistent interfaces and data structures. - Modularity
To provide components that can be used and understood easily without the need to go through the entire toolkit!
Though this toolkit comes with a wide range of functions, the user has to consider the fact that it is not a stable system but a toolkit, and it will continue to evolve with the field of NLP. Even though the toolkit is efficient enough to support meaningful tasks, it is not highly optimized for runtime performance which involves complex algorithms, or implementations in lower-level programming languages such as C or C++. This would make the software less readable and more difficult to install.
NLTK has been implemented for a lot of real-world applications which are instrumental for their growth. Text classification is commonly in use and helps in getting rid of redundant data and retain the useful stuff.
Here is a small code snippet which will help you understand it much better in Python-
Before installing the NLTK library, one must have Jupiter installed in their systems to utilize them.
Installing NLTK-
- On a Windows or Mac machine, you can install NLTK library in Jupiter terminal
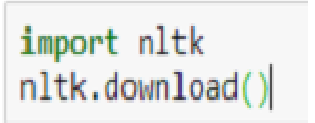
- Text Tagging

- Output

- Parsing a tree from the text

Output
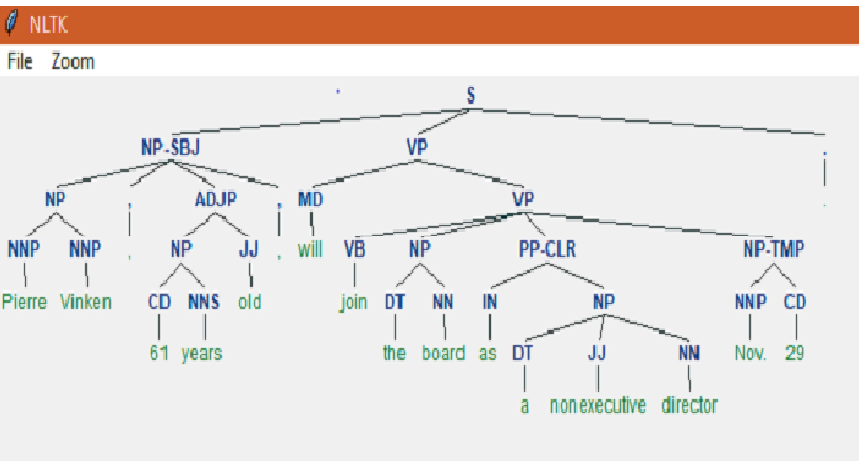
Conclusion
NLTK has a long way to go as more and more unstructured data is increasing day-by-day. NLTK is been updated on an everyday basis to tackle the real-world datasets that consist of irregularities and anomalies in data. To counter more complex datasets, we need more modules and libraries that can deal with this issue.


{kind=link}