

Articles Series Synopsis
This is a series of articles where we look at problems you can encounter when building Applications with the Hadoop Ecosystem. We will look at the three major technology stacks for Hadoop,
- Hortonworks
- Cloudera
- Apache Bigtop
In this article we will look at an issues for the Hortonworks Sandbox. The Hortonworks Hadoop testbed, the Hortonworks Sandbox VM. The Hortonworks Sandbox is based on Cento 6 which uses an older version of the Python, Python version 2.6 or lower.
The Python language is an excellent tool for creating scripts and utilities to perform routine functions for big data applications. However many usefull packages for Data Analysis and Data Science require newer versions of Pyhon generally 2.7 and above.
Beyond this Python is used to build massive web applications like Youtube.In the Big data context Python is the go to langauge for accessing REST endpoints to pull raw or Unstructured Data.
One such REST endpoint for unstructured data is the Twitter REST API. Python has an excellent client for the Twitter REST API Tweepy.
Centos Linux is an extremley stable version of linux and is massivley popular for setting up Internet hosting applications to run standard LAMP stacks think ‘cPanel’. This stability in Centos is provided by its battle hardened system scripts written in Python 2.6. So yo obtain a more up to date Python interpreter and packages we can’t just type yum upgrade python as that will break your system.
To use Tweepy on the Hortonworks Cento 6 based Hadoop Sandbox we need to keep the Python 2.6 interpreter for the Cento 6 system scripts and install a more up to date Python distribution in parallel with the Python 2.6 interpreter for the Centos 6 system.
Getting started
1 Download latest Stable Hortonworks Sandbox
HDP 2.2 : Ready for the enterprise
2 set up, run and create ssh file browser and ssh terminal
ssh details found on VM splash screen, password is hadoop

ssh details used to establish a ssh file browser
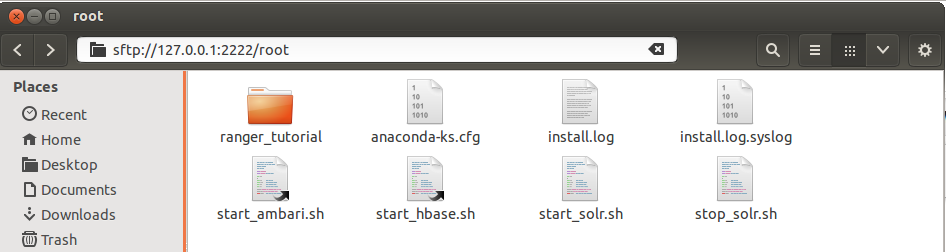
ssh details used to establish a ssh file browser
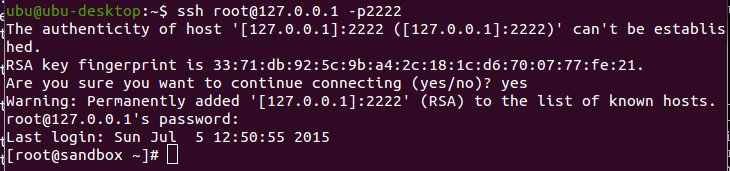
Hortonworks Sandbox is an excellent pseudo cluster, however as previously stated Centos 6 has an older version of python that it uses for all its system scripts. We cannot just upgrade the default python libraries as this will break all the system scripts.
Installing multiple Python versions for the Hortonworks Sandbox
What follows applies for Python 2.7, the steps are almost identical for Python 3.
Step 1 download Python 2.7 dependencies and extract the Python 2.7 tarball
Update the native toolchain
yum groupinstall "Development tools"
Update Python 2.7 dependencies below is a minimal list for what we wish to acjieve with Tweepy, many more would be needed for other work such as database development
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel readline-devel libpcap-devel xz-devel
Download Python 2.7 dependencies and extract the Python 2.7 tarball
wget http://python.org/ftp/python/2.7.6/Python-2.7.6.tar.xz tar xf Python-2.7.6.tar.xz
Step 2 configure the native runtime set up so we build Python 2.7 as a shared native library
Edit the linking configuration file /etc/ld.so.conf to include the line that includes the directory in red below
Contents of ‘ld.so.conf’
include ld.so.conf.d/*.conf /usr/local/lib
Then issue the following command in the terminal to update the runtime linker, this is a critical step that can possibly be needed to be run again at the completion of the python build if you run into shared libary linking errors at runtime
/sbin/ldconfig
Step 3 Configure the toolchain to build Python 2.7 and ‘alternative’ install
We need to make sure the new Python interpreter is built as an ‘alternative’ located at /usr/local/lib not /usr/bin/lib. We do this by configuring the toolchain with the -prefix flag and running make altinstall when we build.
We also need to make sure we build as a shared libary. We do this by configuring the toolchain with the -enabled-shared flag.
Change to the directory where we extracted the Python2.7 source
cd Python-2.7.6
Configure the toolchain as previously described
./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared
Build Python 2.7
make && make altinstall
Step 4 test Python 2.7
In a terminal type ‘which python’
![]()
this the python 2.6 interpreter for the system runtime
Now type ‘which python2.7′
![]()
Now type python2.7 and possibly you will get the following error
![]()
just reset the linker again with /sbin/ldconfig

This the python 2.7 interpreter we just built and installed, we will use this newer version of python for the many packages it has by default and Tweepy .
Install and configure Tweepy
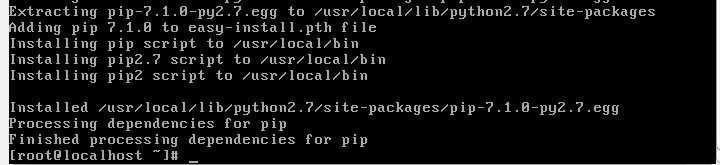
Instal pip with the newly installed python 2.7 interpreter
wget
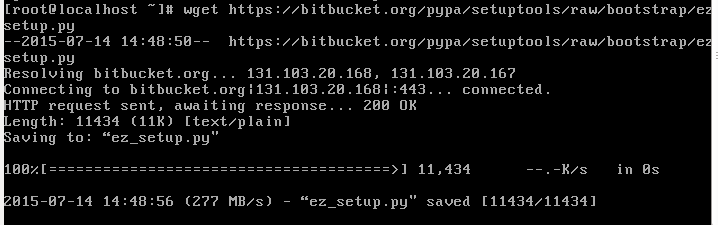
Run the downloaded script to install pip with the new python 2.7 interpreter
python2.7 ez_setup.py
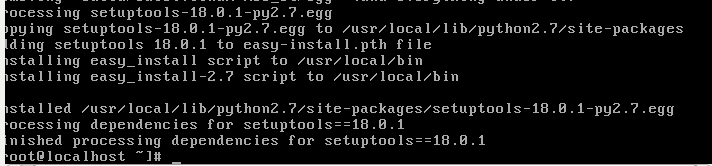
This installs setup tools so we can easily install python packages
We can then use them to install pip with
easy_install-2.7 pip
Finally we can Install Tweepy with pip
pip install tweepy
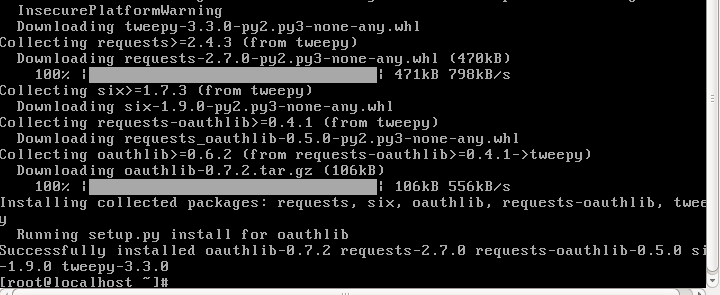
Now we have tweepy installed we are in a position with our updated python interpreter to exploit Tweepy to construct a small concise Twitter Stream Processor using the StreamListener object from Tweepy.
In the last article we talked about microservices, small focused applications with minimal resource usage and developed with minimal and coherent code. Python 2.7 and Tweepy allows us to create just such a microservice as we will illustrate with the following.
Create a Twitter Stream microservice with 15 Lines of code
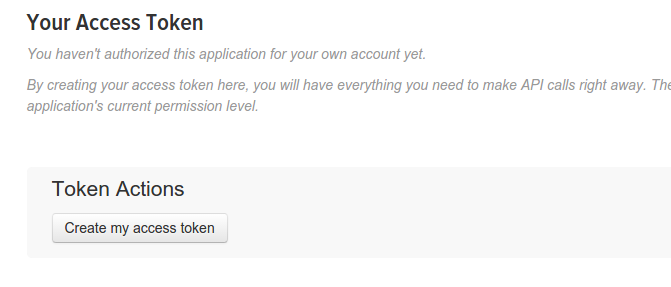
Tweepy provides access to the well documented Twitter API. We use OAuth to access the Twitter API. As in the last article you need to create an application on Twitter and obtain the client (application) credentials (“client key”, “client secret”).
Then we need to perform an extra step and generate the Access Token (“access_token key”, “access_token secret”). This follows as our Twitter Streaming microservice is not in a position to do the OAuth2 dance. The screen shot below shows the first step in generating the Access Token on the Twitter developer’s console.
Twitter stream micro service
class StreamProcessor(tweepy.StreamListener):
def __init__(self, api, numtweets=0):
self.api = api
self.count = 0
self.limit = int(numtweets)
super(tweepy.StreamListener, self).__init__()
def on_data(self, tweet):
tweet_data = json.loads(tweet)
if 'text' in tweet_data: print tweet_data['text'].encode("utf-8").rstrip()
self.count = self.count+1
return False if self.count == self.limit else True
auth = tweepy.OAuthHandler("client key", "client secret")
auth.set_access_token("access_token key", "access_token secret")
api = tweepy.API(auth)
sapi = tweepy.streaming.Stream(auth, StreamProcessor( api=api, numtweets=15))
sapi.sample()
Stepping through the code
Using Tweepy creating a twitter stream is a breeze.
Step 1 Create an authorisation flow for the Twitter API.
auth = tweepy.OAuthHandler("client key", "client secret")
auth.set_access_token("access_token key", "access_token secret")
api = tweepy.API(auth)
Step 2 Create a Twitter Stream Processor using the Tweepy StreamingAPI StreamListener type .
class StreamProcessor(tweepy.StreamListener):
…..
self.limit = int(numtweets)
def on_data(self, tweet):
tweet_data = json.loads(tweet)
if 'text' in tweet_data: print tweet_data['text'].encode("utf-8").rstrip()
…...
here we can see the key interface between the Twitter API and the Tweepy StreamingAPI. That is we are pulling the Twitter data in Json and checking for a non empty Json value for the Json key ‘text’. Then we output the raw serialised Json data in our chosen encoding “utf-8”. We can eventually pipe this output to HDFS however for testing we can output to a file.
Summary
Problem Outline.
Centos uses the stable enterprise standard code developd for Red Hat Linux. The Hortonworks Sandbox is a Centos 6 Box. While the stability of Centos is good for developing distributed java applications like Hadoop it has a drawback in that it needs to have Python 2.6 for its system scripts. This means we cannot exploit the power and utility of python for bigdata services such as the twitter micro service we built here.
Problem Solution.
As we have outlined in detail and tested with our Twitter streaming microservice.
- Download a later up to date version of Python source.
- Update the systems toolchain.
- Configure the toolchain to build Python as a shared libary
- Update the linker configuration with /sbin/ldconfig (this may be needed post build as well)
- Build Python with make altinstall (this step skips the symbolic links that would break the Centos system scripts)


