

Within Hadoop, MapReduce has been the widely used approach to process data. In this approach data processing happens in batch mode that can take minutes, hours or days to get results. MapReduce is useful when waiting for a long period for query results is not problematic. However when you need to get query results in a few seconds such a data processing model is no longer useful. Apache Tez is a project in the Hadoop ecosystem that was developed to address the need for interactive data processing. The project began incubation in February of 2013 and became a top level project in July of 2014. By using Tez as the data processing framework performance gains of up to 3 times over MapReduce are achievable. Apache Hive and Apache Pig are two of projects in Hadoop that have benefited greatly from performance gains offered by Tez.
Tez is not intended to be used directly by users but as an underlying framework to enable application development. Tez simplifies data processing by enabling data processing tasks to be modeled as directed acyclic graphs (DAG). By using DAG tasks that previously required several MapReduce jobs are now processed in a single Tez job.
Apache Spark is another data processing framework that has been developed to supplement MapReduce. It can be confusing deciding on which framework to use between Spark or Tez. The decision on which framework to use is best guided by the problem to be solved. When the objective is to process very large amounts of data spread across several thousand node cluster Tez is a better choice. When you intend to run a data processing workload that is cpu intensive and data volume is not very high, may be several hundred node cluster Spark is a better choice.
Tez can be run in local mode or on a cluster. Local mode is appropriate for developing and testing Tez jobs. Local mode offers several advantages that are ideal in a development but not a production environment. These are listed below:
It is easier to debug code because it runs as a single JVM
Running unit tests is very fast because resource allocation and launch of JVMs is not needed
When running in local mode data size should be kept small to avoid out of memory errors.
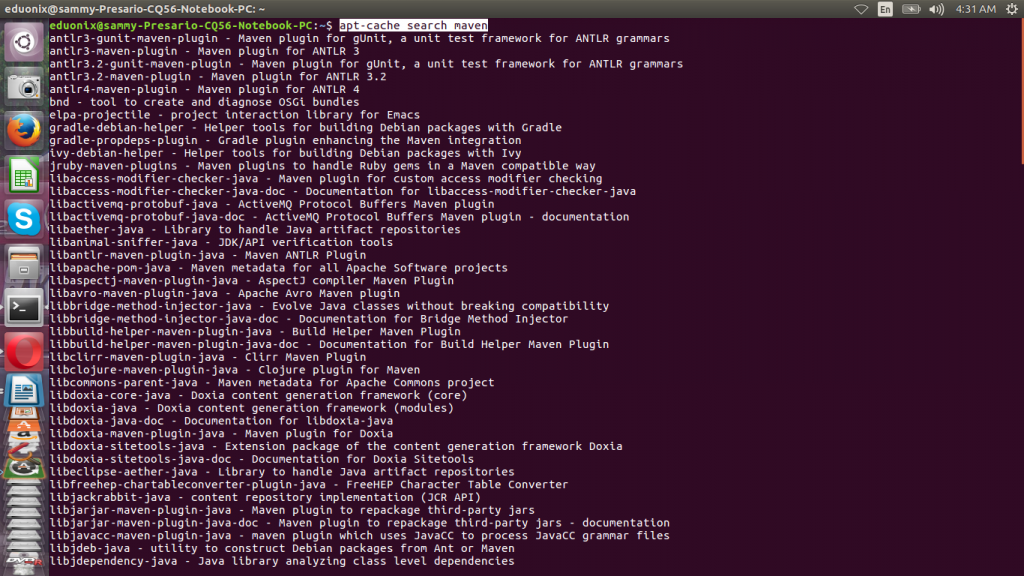
To install Tez you need at least Maven 3 and protocol buffer 2.5.0 with its compiler. Maven is needed to compile Tez source code. The commands below search, install and verify Maven has been installed.
apt-cache search maven
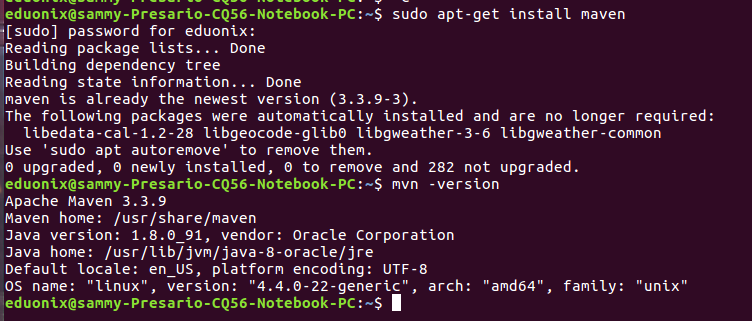
The commands below install and check Maven is properly installed.
sudo apt-get install maven mvn -version
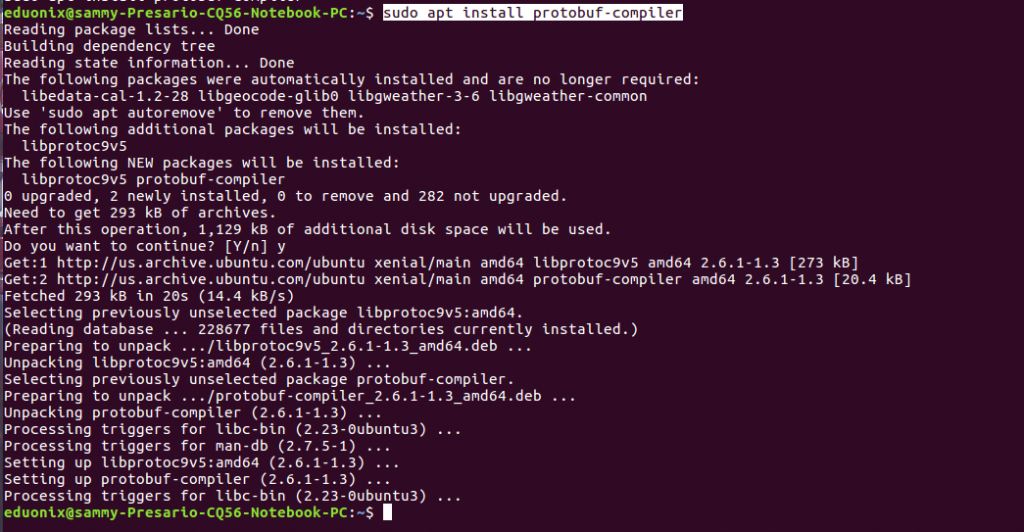
The command below installs protocol buffer
sudo apt install protobuf-compiler
Run protoc –version to check installation was sucessful.

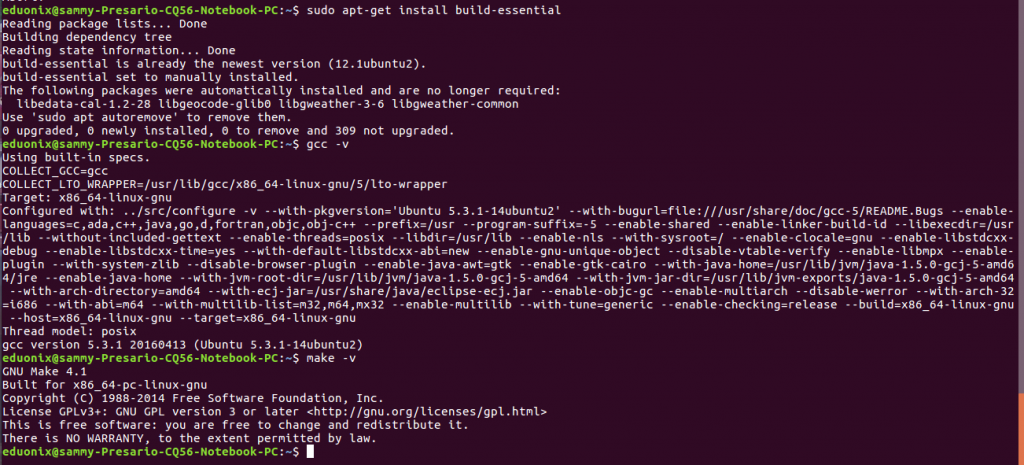
To install the compiler use the commands below
sudo apt-get update sudo apt-get install build-essential gcc -v make -v
Download Tez from here http://www.apache.org/dyn/closer.lua/tez/0.8.3/ or your closest mirror website. Move to the directory where it was downloaded and unpack it.
cd ~/Downloads sudo tar xzvf apache-tez-0.8.3-src.tar.gz
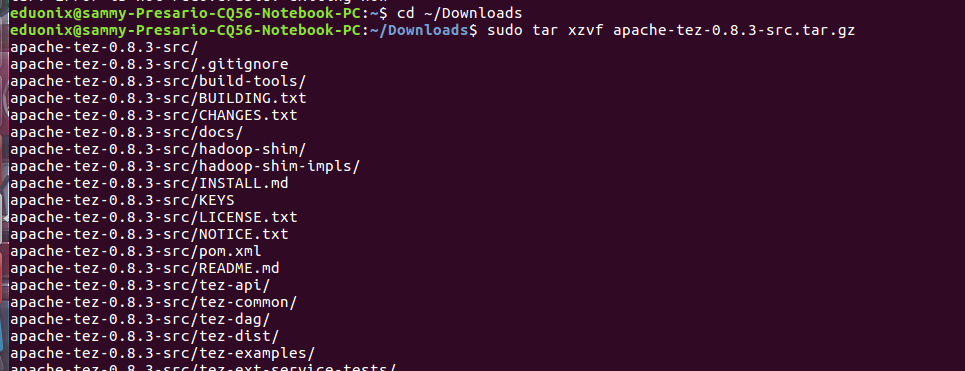
Before packaging the source code we need to edit pom.xml to make sure the Hadoop version referenced is correct. Run hadoop version to get the version running on your system.

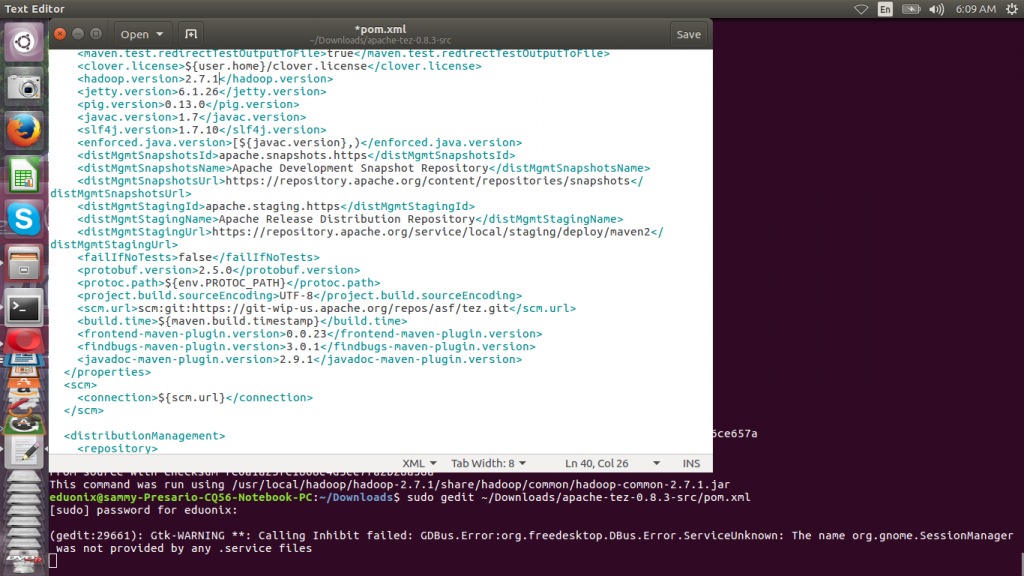
Run the command below to open pom.xml then change hadoop.version property to 2.7.1 version. Other properties such as pig and java version are set in this file.
sudo gedit ~/Downloads/apache-tez-0.8.3-src/pom.xml
Once all properties have been set we are ready to package the source code. This is done using the commands below. You can add -Dskiptests to skip unit tests. Compiling may take a while so you can be doing other tasks as wait for it to be complete.
cd ~/Downloads/apache-tez-0.8.3-src sudo mvn clean package -DskipTests = true
Once packaging is complete Tez tarballs will be placed in /tez-tests/target directory. To deploy Tez we just need to move the jar file onto HDFS and configure its properties via tez-site.xml. Create a directory on HDFS and move tez tarballs there. Use commands below
hadoop fs -mkdir /usr/local/tez_install/ hadoop fs -put ~/Downloads/apache-tez-0.8.3-src/tez-tests/target/tez-0.8.1-alpha.tar.gz /usr/local/tez_install/
Tez configuration needs to be done all all Tez client nodes i.e all nodes that submit Tez applications to YARN resource manager. Create configuration directories using commands below
sudo mkdir -p /etc/tez/conf/ sudo mkdir -p /usr/jars/tez
Under /etc/tez/conf/ directory create a tez-site.xml configuration file and add the lines below. The tez.lib.uris property points to the HDFS path where compressed jar files were uploaded. Change the value to the path that points to that directory.
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/usr/local/tez_install/tez-0.8.1-alpha.tar.gz</value>
</property>
</configuration>
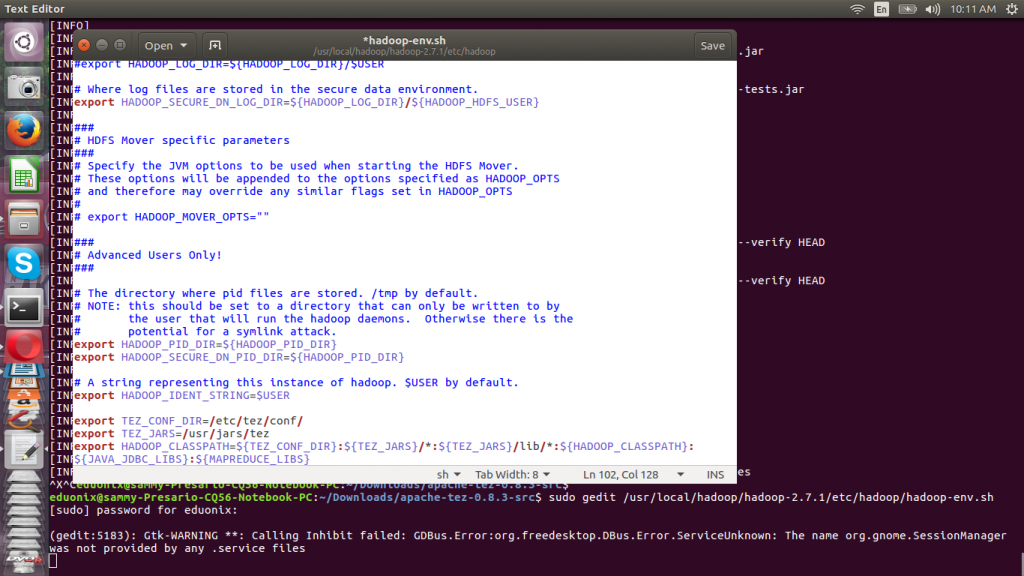
After configuring tez-site.xml we need to add tez libraries to hadoop classpath. Extract tez minimal tarball created when packaging source code to /usr/jars/tez. We edit hadoop-env.sh to point Hadoop to Tez configuration file and Tez libraries. The hadoop-env.sh configuartion file resides under /etc/hadoop sub directory of Hadoop main directory. Open the file and add the lines below
sudo gedit /usr/local/hadoop/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
export TEZ_CONF_DIR=/etc/tez/conf/
export TEZ_JARS=/usr/jars/tez
export HADOOP_CLASSPATH=${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*:${HADOOP_CLASSPATH}:${JAVA_JDBC_LIBS}:${MAPREDUCE_LIBS}
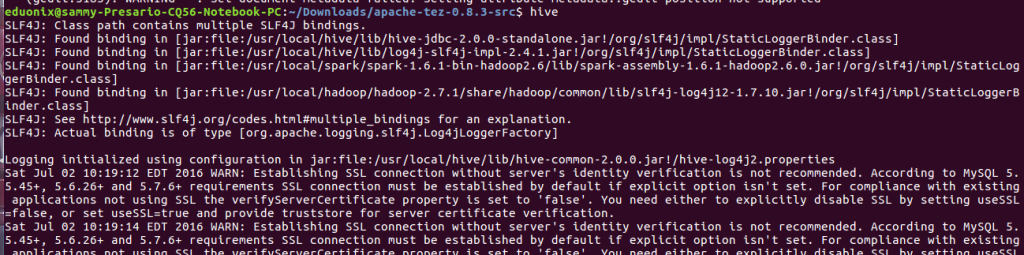
At this point Tez is installed and properly configured for use. To use Hive with Tez as execution engine invoke hive shell then set Tez as the engine using the commands below.
hive set hive.execution.engine=tez;
![]()
To use Pig with Tez you can pass the option when issuing the command or set the option in configuration files. In command line mode you just append -x tez to your command. Under /pig/conf there is a pig.properties file where you can set Pig to use Tez as its execution engine. Add this line to the file exectype=tez
sudo gedit /usr/local/pig/conf/pig.properties
This tutorial introduced you to Tez which is a data processing framework developed to solve shortcomings of MapReduce. The key benefits of Tez over MapReduce were discussed. Installation of Maven and its use to package source code was discussed. Configuration of Tez was also discussed. Necessary configurations to make Hive and Pig use Tez were discussed.


