

Hello readers, today we are here to discuss about the K-Nearest Neighbors Algorithm (KNN Algorithm). KNN Algorithm is one of the simplest and most commonly used algorithm. It can be termed as a non-parametric and lazy algorithm. It is used to predict the classification of a new sample point using a database which is bifurcated in various classes on the basis of some pre-defined criteria.
What is KNN Algorithm?
KNN Algorithm belongs to the group of competitive learning, lazy learning and instance based algorithms. Competitive learning algorithms are those that use competition between data instances to predict decisions. This is how KNN Algorithm works. The instances here constantly fight to win so as to become the most similar to the given unseen data instance which helps in making predictions.
Lazy learning refers to the laziness of the algorithm. It will only build the model at the very last instance when it’s an absolute necessity. It is how KNN Algorithm operates. It works at the very last moment. It helps in using only the localised and the most relevant data instances to make the prediction. But being lazy always have repercussions. Here it makes it expensive to repeat the same process when there are larger and more voluminous datasets.
Instance-based algorithms makes use of instances to make the predictions. KNN Algorithm is one of the most extreme form of instance based algorithm as it retains all the training observations as part of the model. It does not assume anything about the data. It does the prediction from the very scratch and without any predetermined facts. This is the reason why it is called non-parametric as it is non linear and doesn’t follow a pre-defined path and does not assume the form of a function. It can be used for regression predictive problems as well as classification based predictive problems.
Few examples of usage of KNN Algorithm
- It is used to predict if the bank should give a loan to an individual. It will try and predict the chances of default and it will try to assess if the given individual matches the criteria of people who had previously defaulted or will he not default his loan.
- It can be used in technologies like OCR, which tries to detect handwriting, images and even videos.
- It can be used in the field of credit ratings. It tries to match the characteristics of an individual with the group of existing people so as to allot the credit rating to him. He will be allotted the same rating as has been given to people matching his characteristics.
- Being one of the simplest and fruitful algorithm in machine learning, it is highly implemented to develop learning based, intuitive and intelligent systems that could perform and take small decisions all by themselves.
- It makes things further convenient for learning and development and is helping nearly each and every type of industry that could use intelligent systems, solutions or services.
Some Advantages of KNN Algorithm Advantages –
- It is very accurate.
- It is simple yet effective.
- No pre-determined assumptions about the data.
- Can do both classification as well as regression.
Disadvantages
- Requires high memory capacity.
- Keeps all the training data.
- It can be a tad slow during making prediction.
- It is computationally expensive.
- It has the tendency to be sensitive to useless features and scale of the data.
How to implement it in Python?
To implement KNN Algorithm in Python, we have to follow the following steps –
1. Handle the data
It is the first step of implementation. Here we have to first load the file. It may be in CSV form or any other form. If in CSV form, we can open the data using the open function and then explore it using the reader function in the csv module. Once we have explored the data, it is to be split into a training dataset compatible for KNN Algorithm and also into a test dataset which will be used to test the accuracy of the given KNN Algorithm.
2. Checking for similarity
For prediction, we first have to ascertain the similarity between any two of the given data instances. It will be needed to locate the K most similar data instances in the training dataset for any given instance of the test dataset so as to enable it to make a prediction. Care must be given to also choose only those fields which are required. It can be done using the EuclideanDistance function.
3. Selecting the Neighbors
Once the similarity is ascertained, we can use it to collect the K most similar instances for the given unseen instance. getNeighbors function is used for doing this task. It will take the help of already defined Euclidean Distance function to choose the most common neighbours.
4. Seeking a Response
Once the most similar neighbours have been finalized for a given test instance, the next task is to create a predicted response which will make use of these chosen neighbours. This is done by allowing each neighbour to vote for its class attribute and the result will be the one with majority vote as the chosen prediction. getResponse function is used for accomplishing this task and it may return any one instance when it’s a draw. Further, you can also customize the return as per your needs. It may select an unbiased random response or no response at all if we customize it in that manner.
5. Testing the Accuracy
After placing all the required components of the algorithm in their rightful places, it is very important to test the accuracy of the prediction that will be made. The easiest way to ascertain it is to calculate the ratio of correct predictions is to total predictions made till date. This is known as Classification Accuracy. getAccuracy function is used here to return the total predictions made and also the percentage of correct predictions when compared total predictions.
6. Tying with the Main function
We have all the required elements for the algorithm. The last work is to tie them together with a main function. It is done using the Main function. The accuracy of the data, so generated is around 98%.
How to choose the factor K?
Finding the K is one of the trickiest jobs and you need to be very careful while doing the same. If you choose a smaller value of K, it will lead to the noise having a bigger role to play in the end result whereas a large value will make it computationally expensive. You can normally choose an odd number if the number of classes are two or you can use sqrt function to choose it more accurately.
K is a hyper parameter that must be picked so as to get the best possible fit for the given dataset. A smaller K will force the classifier to be more blind to the overall distribution whereas the higher K will result in smoother decision boundaries but with an increased bias in the result.
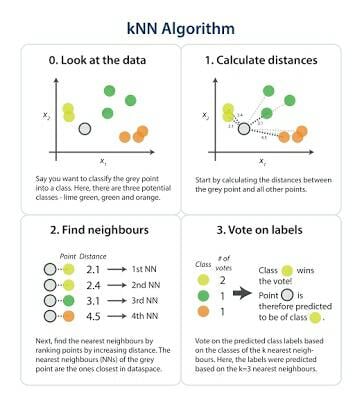
A short summary of how it works:-
- We select a positive integer K along with a sample.
- K entries are selected which are closest to the newest sample.
- The most common classification of these entries is found.
- The same classification is allocated to the new sample.
Wrap-Up
KNN Algorithm is one of the simplest and most versatile algorithm which can give competitive results even without much complexity. I hope this article has helped you in understanding this algorithm a bit better than you previously did, if not completely. You can use this algorithm to find answers to a variety of your complex questions and given its almost cent percent accuracy, you will not be disappointed.


