

Continuing what started in the previous article: Text Processing Tools.
Following a Continually Growing Text File
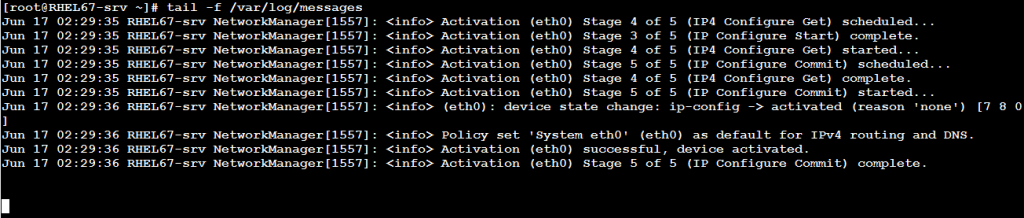
There will be cases wherein you need to monitor in real time any new appended data to a file. This is a common situation especially with log files. For this situation, the tail command is used with the –f option.
Example
The following will monitor the /var/log/messages file for new events logged to it:
Searching Files for Patterns
Also, there will be cases wherein you want to search for a specific pattern in one or more files. The grep utility and its different forms achieve this for you.
The grep Command
grep stands for global regular expressions print. grep searches the input files or the standard input if no files are provided for lines containing a match to the given pattern. By default, grep prints the matching lines.
Two other forms of the grep command are the fixed grep fgrep, and extended grep egrep.
Syntax
grep [OPTIONS] PATTERN [FILE...]
Where: PATTERN is the string to search for.
Common Options
-i – Ignores case.
-v – Inverts matching, i.e. causes grep to discard lines containing the matched pattern.
— – color Colorizes matched strings in the returned output.
-l – Returns only files names that contain matching lines.
-q – Quiet matching. This option causes grep to silently exit with zero status if any match occurs, and non-zero if no match found.
-n – Prints the line number of the matching line, in addition to printing the line itself.
-r – Recursive Search.
-w – Matching complete words only.
-A – NUM Prints NUM lines of the original input text after the matching line.
-B – NUM Prints NUM lines of the original input before the matching line.
Examples
- Consider the output of the ip addr command:
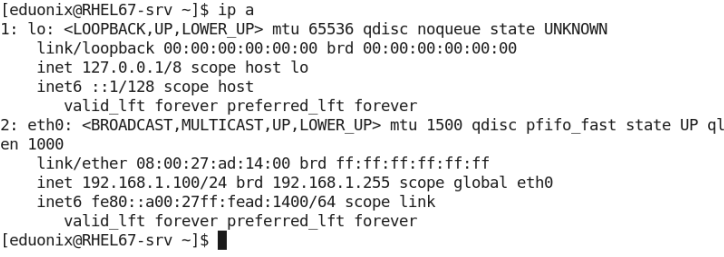
You need to extract the lines containing the IP address info. In the command output, the IP addresses appear in the lines containing the word “inet”. So, to extract the IP address info, simply search for the lines containing that word:

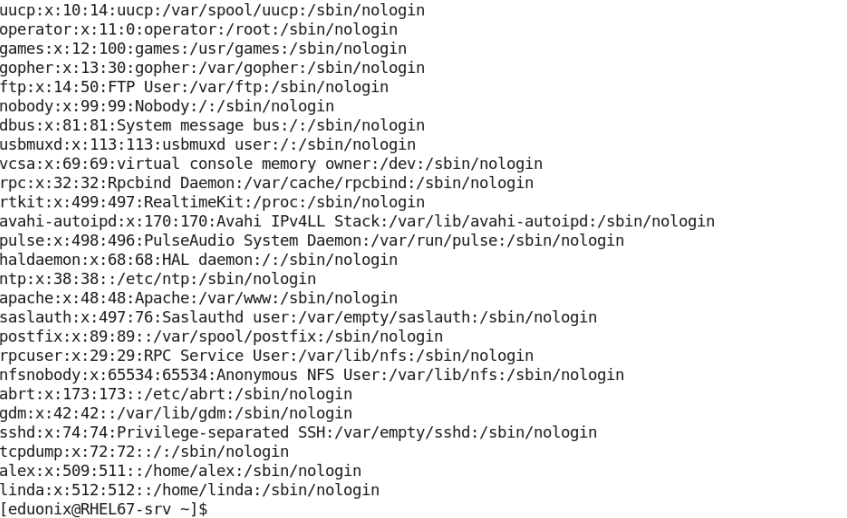
- Print the list of user accounts that are not allowed to login to the system.
grep nologin /etc/passwd
Users not allowed to login have their startup shell set to /sbin/nologin. So to get the list of users that could not login, simply grep the /etc/passwd file for the word nologin:
- In a given directory, list the files and directories that were last modified in June.

- The following command:
grep –i test file1
will match lines containing any of the following: test, Test, tEst, teSt, tesT, TEST, TEst, tESt, teST, TESt, TeST, TEsT, or tEST.
- Print Process info for processes matching a specific search pattern:
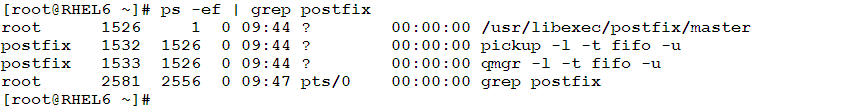
Matching the Beginning and End of Line
In some cases, you need to match line boundaries. For this reason, the grep command utilizes two special characters:
- The caret ^ matches the beginning of a line.
- The dollar sign $ matches the end of the line.
Examples
- You need to list only the sub-directories in a given directory. A simple trick to achieve this, is to search the long listing of the directory contents for lines starting with the character d.

- The following matches empty lines in a file:
grep ^$ /etc/sysconfig/network
xtracting Exreaving Specific Fields of Text
There will be many cases wherein you need to extract one or more fields (columns) out of an input file or text. One of the available options to achieve this is using the cut command.
The cut command prints selected parts of lines from each input file to the standard output.
Syntax
cut –d DELIMITER –f FIELDs [FILE]… cut –c RANGEofCHARACTERS [FILE]…
Examples
- The following selects only the user name and its corresponding startup shell from the /etc/passwd file:
cut -d : -f 1,7 /etc/passwd
- The following command generates the MD5 hash for the output of the date command, then extracts only the first 8 characters of the resultant hash:

Note : The last example presents a very simple, yet powerful way to generate random passwords.
Summary
To monitor the growth of a text file, use the tail command with –f option.
The grep command is used to search text files for specific matching pattern(s).
The cut command is used to extract fields or characters out of input text or text files.
That was part two talking about Text Processing Tools; followed by part three. So, stay here, we won’t be late.


