
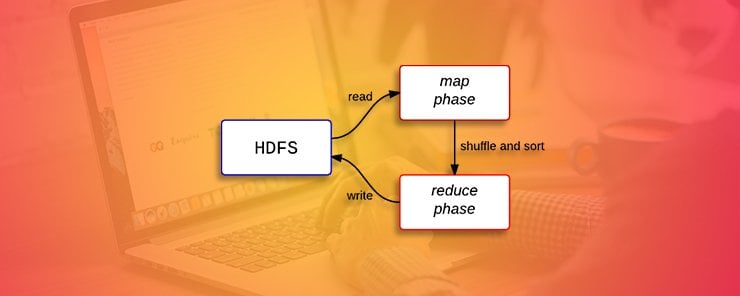
The philosophy behind the MapReduce framework is to break processing into a map and a reduce phase. For each phase the programmer chooses a key-value pairs which are the input and the output. It is the responsibility of the programmer to specify a map and a reduce function. In this article, it is assumed the reader already has Hadoop installed and has the basic knowledge of Hadoop. For a review of these concepts, please refer to our earlier articles.
To effectively write MapReduce applications a thorough understanding of data transformations applied on data is necessary. The key data transformations are listed below:
• The first transformation is reading data from input files and passing it to the mappers
• The second transformation happens in the mappers
• The third transformation involves sorting, merging and passing the data to the reducer
• The final transformation happens in the reducers and the output is stored in files
When writing MapReduce applications, it is very important to ensure appropriate types are used for the keys and values otherwise the input and output types will differ causing your application to fail. Because the input and output derive from the same class you may not get any errors during compilation, but errors will show during compilation causing your code to fail.
Although the Hadoop framework is written in Java, you are not limited to writing MapReduce functions in Java. Python and C++ versions since 0.14.1 can be used to write MapReduce functions. In this article, we will focus on demonstrating how to write a MapReduce job using Python. One approach that is widely used when using Python is using Jython to translate code into a jar. This approach becomes limited when needed features are not available in Jython.
In the Python code, in this article the Hadoop streaming API will be used to facilitate movement of data between the map and reduce functions. The Python sys.stdin function will be used to read data and sys.stdout will be used to export data.
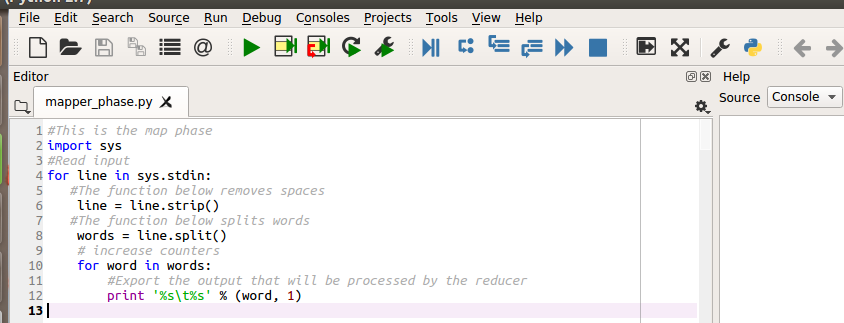
The mapper function will read data, split and export it. There will be no intermediate computations in the map phase. The map phase is shown below, save it as mapper_phase.py and make it executable using this command chmod +x /home/sammy/mapper_phase.py
#This is the map phase
import sys
#Read input
for line in sys.stdin:
#The function below removes spaces
line = line.strip()
#The function below splits words
words = line.split()
# increase counters
for word in words:
#Export the output that will be processed by the reducer
print '%s\t%s' % (word, 1)
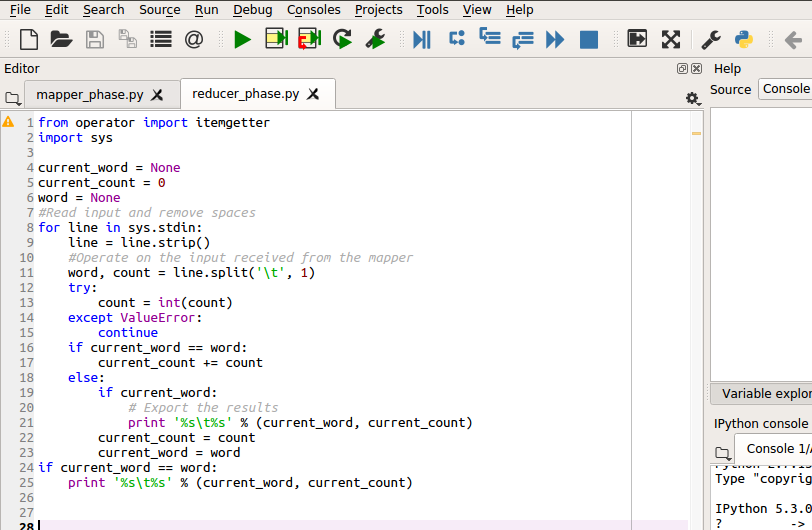
The reducer will read the output of the mapper, count the number of times each word occurs and export the results. The reducer code is shown below, save it as reducer_phase.py and make it executable using the command chmod +x /usr/sammy/reducer_phase.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
#Read input and remove spaces
for line in sys.stdin:
line = line.strip()
#Operate on the input received from the mapper
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
# Export the results
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)
In order to test the mapper and reducer code, we will use the text available here http://www.gutenberg.org/files/5000/5000-8.txt, so you should definitely download it. Before we can use the text it has to stored in HDFS. Create a directory and move it there.
hadoop fs -mkdir /usr/local/hadoop/text_data hadoop fs -copyFromLocal ~/Downloads/davinci.txt /usr/local/hadoop/text_data hadoop fs -ls /usr/local/hadoop/text_data

To run our MapReduce job, we need to specify the location of the hadoop-streaming jar, the mapper, reducer, input and output as shown in the command below.
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar \ -file /usr/sammy/mapper_phase.py -mapper /usr/sammy/mapper_phase.py \ -file /usr/sammy/reducer_phase.py -reducer /usr/sammy/reducer_phase.py \ -input /usr/local/hadoop/text_data/text.txt -output /usr/local/hadoop/text_data-output
In the previous section, we demonstrated how to write and test a mapper and a reducer. In the next section, we will discuss what happens when running a MapReduce job.
A MapReduce job is a work unit that needs to be completed. It is made up of data, MapReduce program and configurations that control how it runs. The job is split into map and reduce tasks. YARN handles the scheduling of tasks on different nodes when you are running a cluster.
The input provided to a MapReduce job is divided into splits. For every split, a map task is created to run the specified map function on all the records in the split. Many splits reduce the processing time but increases the demand on load balancing. Preference is given to running the map task, where the data is located to conserve bandwidth. When this is not possible, the job scheduler selects a node within the same rack and when this is still not possible a node outside of the rack is selected. The optimal split size is equal to the block size.
The output of intermediate tasks is placed on the local directory instead of HDFS to avoid the inefficiency of replicating intermediate results. Reducers do not benefit from data locality because their input is obtained from the output of multiple mappers.
Bandwidth availability limits most MapReduce jobs so it is good practice to minimize data transfer between mapper and reducer. An optimization to this problem is using a combiner function to process the map output and feed it to the reducer.
In this article, we introduced the MapReduce framework for data processing. We identified the different ways in which data is transformed as it is processed. We demonstrated how to write a mapper and a reducer in Python. Finally, we discussed the details of data processing.


