

Natural Language Processing (NLP) is the branch of artificial intelligence that gives computers the ability to process, understand and draw conclusions from natural languages like speech or text. It combines linguistics and computer science to analyze the structure of the language and create models that can separate the important features from a text or speech. It can be viewed as teaching a language to a computer in the same way a child learns it. With the increasing human-to-machine conversation, the NLP is rapidly advancing, and many new techniques have evolved in this field. It is ingrained into our daily lives as its applications can be found in many different technologies around us.
One of the most popular applications of NLP is sentiment analysis. Sentiment analysis is a technique in natural language processing used for detecting the sentiments underlying any text. It analyzes the input texts and identifies the sentiments within the text. It uses an ML model or any classifier algorithm to classify the texts into different classes according to the respective emotions. Generally, the input texts are classified as positive, negative, or neutral. Sentiment Analysis has a wide range of applications, including product review analysis, monitoring social media responses, and so on. It analyzes a large number of customer reviews, thus helping the company in improvising the product accordingly. It can also be used to determine the underlying emotions in a text or speech (like angry, sad, joyful, etc.). Sentiment analysis works on the concept of feature extraction. It extracts certain features (or words) from sentences and uses them to determine the sentiments underlying that text. This article demonstrates a simple sentiment analysis tutorial in the python programming language to classify movie reviews as positive or negative.
Sentiment Analysis in the Python Programming Language
In this tutorial, we will implement a simple model for classifying the text inputs into positive or negative sentiments (binary classification). The model uses a Support Vector Machine (SVM) classifier for classifying the texts into two classes or sentients (positive and negative).
Dataset Used for Training and Testing the Model
The dataset used here is the IMDB Reviews dataset containing 50,000 movie reviews, commonly used for binary text classification. The reviews are classified into two classes or labels as positive or negative.  Importing the Required Libraries
Importing the Required Libraries
The external libraries required for this tutorial are Pandas, Numpy, and SciKitLearn. The use of each library in this tutorial is stated below.
- Pandas – Used for reading and performing basic operations on the dataset.
- Numpy – Used to perform mathematical operations on arrays for feature extraction.
- SciKitLearn – Used for label encoding the attributes, splitting the dataset into testing and training samples, and creating the SVM classifier for sentiment analysis.
 Data Preprocessing Before Implementing the SVM Classifier
Data Preprocessing Before Implementing the SVM Classifier
Before implementing the classifier algorithm for analyzing the sentiments of the text data, the data must be preprocessed as the computer only understands numerical data. Hence, various text preprocessing techniques need to be applied to the text data to convert it into a machine-readable format. These include tokenization, lemmatization, stemming, etc. Moreover, various encoding techniques like Bag of Words (BoW), Bi-grams, n-grams, TF-IDF, and Word2Vec are used for converting text data into a numerical representation. 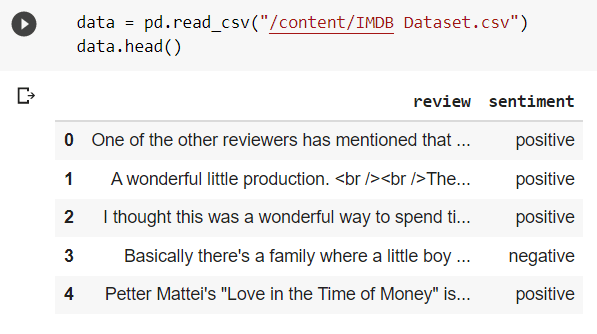 Then the preprocessed text data is converted into document vectors (DocVecs). This can be done by various techniques like Doc2Vec, Sent2Vec, n-gram embeddings, LDA, etc. Here, the preprocessed sentences are converted into document vectors by first obtaining the word vectors of each word and then adding and normalizing them to generate the sentence vectors. The following code snippets show the generation of document vectors from the text data.
Then the preprocessed text data is converted into document vectors (DocVecs). This can be done by various techniques like Doc2Vec, Sent2Vec, n-gram embeddings, LDA, etc. Here, the preprocessed sentences are converted into document vectors by first obtaining the word vectors of each word and then adding and normalizing them to generate the sentence vectors. The following code snippets show the generation of document vectors from the text data.
 The sentiments are label encoded with the help of the LabelEncoder package from the SciKitLearn library. Here, “1” represents a positive sentiment while “0” represents a negative sentiment. Further, the sentence vectors are added to the dataset as an attribute for each review, as shown in the following code snippet.
The sentiments are label encoded with the help of the LabelEncoder package from the SciKitLearn library. Here, “1” represents a positive sentiment while “0” represents a negative sentiment. Further, the sentence vectors are added to the dataset as an attribute for each review, as shown in the following code snippet. 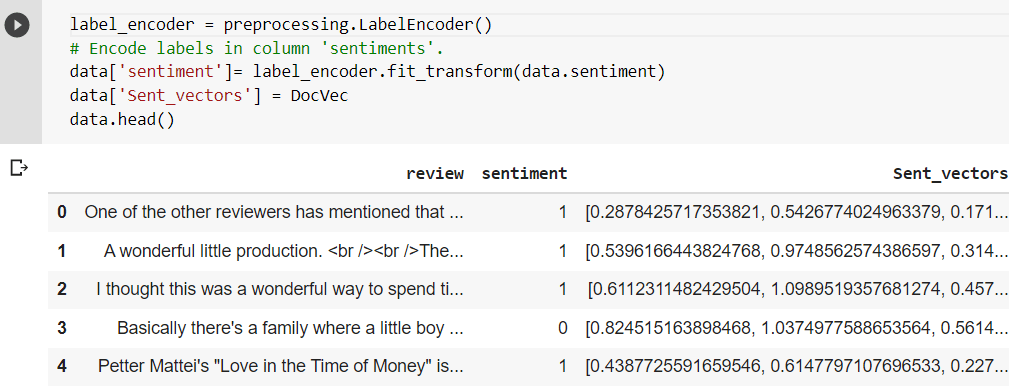 Now the text data is present in a machine-readable format (or in vector form) and is ready to be fed to the classifier algorithm.
Now the text data is present in a machine-readable format (or in vector form) and is ready to be fed to the classifier algorithm.
Splitting the Dataset into Training and Testing Samples
The dataset is then split into training and testing samples with the help of the train_test_split() method. The training and testing samples each have 75% and 25% of the original dataset, respectively.  Building, Training, and Testing the Sentiment Analysis Model
Building, Training, and Testing the Sentiment Analysis Model
The following code snippet builds and trains the SVM classifier for classifying the text into two sentiments – positive and negative (1 and 0; 1 representing positive sentiments and 0 for negative sentiments).  Here, the linear kernel for SVM is used as it is best suited for text classifications or linearly separable data.
Here, the linear kernel for SVM is used as it is best suited for text classifications or linearly separable data.
The model can be evaluated by obtaining the accuracy score, precession score, and recall score. The model has a pretty good accuracy of 77.28%, a precession score of 76.35%, and a recall score of 75.84% Further, the predicted sentiments can be compared with the actual ones for better evaluation.
Further, the predicted sentiments can be compared with the actual ones for better evaluation.  As observed from the above snippet, the model has predicted the first ten sentiments accurately. We can also plot the confusion matrix on a heatmap for an even better analysis of the accuracy.
As observed from the above snippet, the model has predicted the first ten sentiments accurately. We can also plot the confusion matrix on a heatmap for an even better analysis of the accuracy. 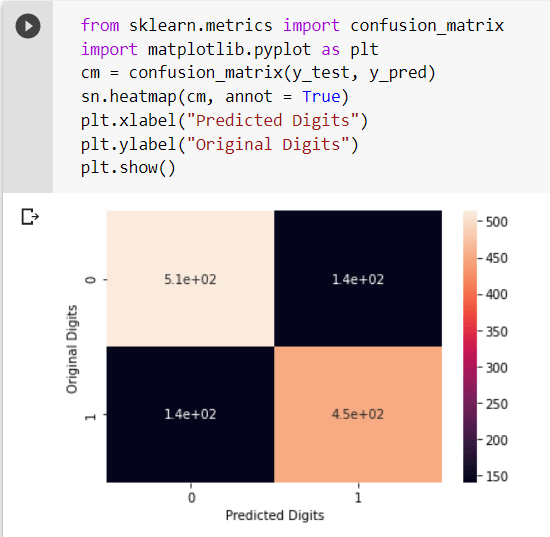 Conclusion
Conclusion
Sentiment analysis, in Natural Language Processing, is an advantageous technique used for extracting sentiments from texts. It can also be referred to as classifying texts into different classes or labels based on their underlying sentiments or emotions. It has many applications like analyzing customer reviews and monitoring social media responses. It analyzes a large number of text reviews very conveniently. With the growth of artificial intelligence and the increase in human-machine interaction, sentiment analysis is becoming an important application of natural language processing. This article has demonstrated an example of sentiment analysis on the IMDB Reviews dataset using the SVM classifier. It classified the reviews into positive or negative sentiments. There are several other techniques for sentiment analysis to be explored. Some of these include sentiment analysis using TensorFlow, Naive Bayes algorithm, Decision Tree algorithm, and many more.
Also Read: Text Preprocessing In Natural Language Processing


{kind=link}