

The use of containers in application deployment has resulted in flexibility when managing deployment. However this flexibility has led to an increase in the number of components thus necessitating the need for a framework of managing the components. Aspects of applications that need to be managed include scheduling, networking, component movement and resource use. Kubernetes provides a framework for application logging, monitoring, load balancing, scaling and authentication.
By using the management tools availed by Kubernetes, you will be able to manage the different components and the entire stack. Kubernetes is architect-ed so that administration is done through kubectl or RESTful API calls. The two states that are possible in Kubernetes are actual state and desired state and it is important to understand the difference between the two. Kubernetes will always aim to ensure the two states are in synchrony as instructed by the administrator. At times the two states are not synchronized, but there is a constant effort to synchronize them.
The first concept is a cluster which is a group of nodes that can be virtual or physical machines that have Kubernetes set up. The diagram below shows a simplified architecture of Kubernetes.
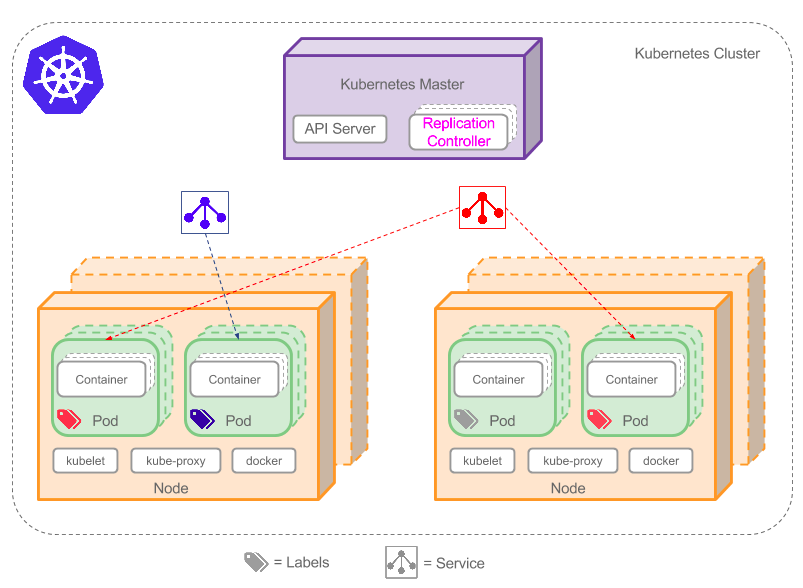
The second concept of Kubernetes that we will discuss is the master. The master can be looked at as the central control point of a cluster. The master is made up of several components. The first component of the master is the core API server and is responsible for maintaining the RESTful service, cluster definition and state. The second component of the master is the scheduler which is responsible for scheduling pods on nodes. The default approach to scheduling is distributing pods across the cluster and replicating pods on different nodes. The default scheduling can be changed by controlling resources that are allocated to containers. Ensuring pod replication is running properly is the responsibility of the replication scheduler. The replication controller ensures the actual and desired state are synchronized. For example, if the replicas defined in the controller are 5 and desired actual state is 3 running pods, then two more pods will be created. If the number of pods running is more than what is desired, then the controller will always work to reduce them. The last component of the master is etcd which is a distributed configuration store. The store is repository of state from where it can be monitored.
The third concept of Kubernetes is node, which was previously referred to as a minion. Just like the master the node is made up of several components. The first component is the kublet which is responsible for updating state and starting workloads. The second component is kube-proxy which is responsible for load balancing and ensuring traffic is directed to the correct pod. The last component is the Domain Name System (DNS) which is responsible for creating logs and checking the status of pods.
Pods are abstractions that help in the organization of containers that have similar network and hardware requirements. Docker is the most commonly used container environment but other environments can also be used. To reduce network latency, data is stored close to where processing happens. Another approach to reducing network latency is storing data that is accessed by many applications on shared volumes. The relationship between nodes, pods and containers is that a pod holds one or more containers and one or more pods operate on a node. Pods can be looked at as the basic units that support deployment, scheduling and scaling.
The recommended approach to creating pods is using a deployment. A deployment contains the information needed to update pods and replicas. A deployment object only needs information on desired state and the deployment controller will take over updating of state. Examples of situations in which deployment is useful are listed below.
- Pausing and resuming deployment
- Rolling back to an earlier deployment when instability happens
- Starting a replica set and pods
- Knowing if a deployment was successful or not
Pods can be created using a deployment or without using a deployment. When your pod has multiple containers or you would like to avoid using a deployment to manage pods the kubetctl create command is used by passing a YAML or JSON configuration file which contains specifications.
Another technique used for organization is labels. Labels can be used as a foundation for service discovery, and grouping operations and management activities. Labels are key-value pairs which help Kubernetes know the resources and operations to use.
Services are another important concept in Kubernetes. Services enable abstraction of access and applications thereby insulating the user from complexities involved in access. Other applications and users are able to easily access pods on a cluster. The service takes care of issues such as keeping track of relationships that exist between pods, for example due to creation and destruction of pods, IP addresses are not stable so the service is relied upon to maintain the correct relationship.
Another important concept in Kubernetes is replication controllers, which are responsible for managing nodes and images. A replication controller ensures availability of the required number of pods. If pods managed by the replication controller are deleted, terminated or they fail the replication controller automatically creates other pods but this is not the case with pods that are created manually.
In this tutorial, we introduced application aspects that require management and how Kubernetes help in application management. We discussed the different components that make up Kubernetes and how they are useful. Because of this behavior a replication controller is the recommended approach even if only a single pod will be used.


I saw your blog it is really good and very much interesting too, thus i like your information what you have posted so please update latest information too.
It is really a great and useful piece of info. I’m glad that you shared this helpful info with us. Please keep us informed like this. Thank you for sharing.
I read your articles very excellent and the i agree our all points because all is very good information provided this through in the post.
Really nice information you had posted. Its very informative and definitely it will be useful for many people