

Introduction
The next moment, you are going to do something very complex without a lot of effort. Ready? Try to identify what’s written in the following image.
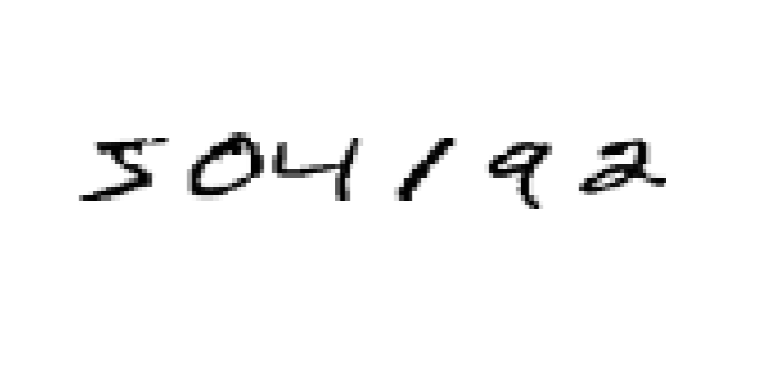 Most of us recognize the above digits as 504192. Easy, right? Behind that ease lies a very complex, efficient and massively parallel system that continuously identifies objects around us in real time. Yet, most of us do not appreciate the problem-solving ability of the human visual system. What may appear easy to humans, a problem recognizing characters is extremely challenging for a computer to solve. Think about it. There are no precise rules as to how to identify characters. It turns out that this seemingly simple problem is actually a difficult one! And yet there are many applications that directly or indirectly involve this problem. This is also known as OCR (Optical Character Recognition).
Most of us recognize the above digits as 504192. Easy, right? Behind that ease lies a very complex, efficient and massively parallel system that continuously identifies objects around us in real time. Yet, most of us do not appreciate the problem-solving ability of the human visual system. What may appear easy to humans, a problem recognizing characters is extremely challenging for a computer to solve. Think about it. There are no precise rules as to how to identify characters. It turns out that this seemingly simple problem is actually a difficult one! And yet there are many applications that directly or indirectly involve this problem. This is also known as OCR (Optical Character Recognition).
More formally, Optical Character Recognition is the process of recognizing printed or written text characters by a computer. Optical Character Recognition can be used in many scenarios like data entry for business documents, automatic number plate recognition, in airports for passport recognition and information extraction, automatic insurance documents key information extraction, converting handwriting in real time to control a computer and assistive technology for blind and visually impaired users.
Neural Network
Let us take a look at the various approaches to solve this problem. One of the most common and popular approaches is based on neural networks, which can be applied to different tasks, such as pattern recognition, time series prediction, clustering, etc. In 1957, Frank Rosenblatt invented the perceptron algorithm at the Cornell Aeronautical Laboratory. A perceptron acts as an artificial neuron and takes several binary inputs and produces a single binary output. A neural network is made up of many such neurons interconnected together multiplied by different weights. Following is one such model.
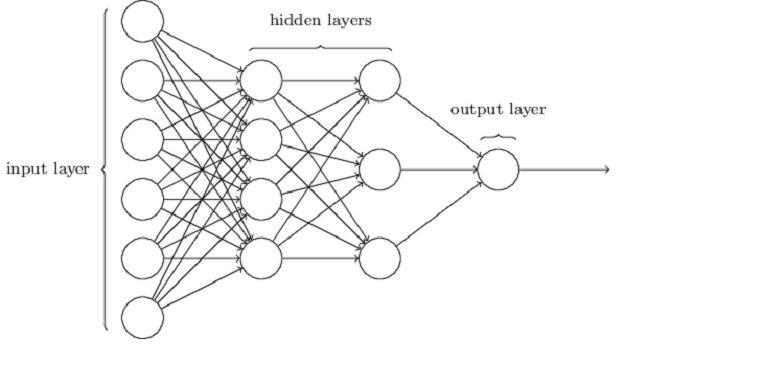
The leftmost layer is called the input layer. The rightmost layer is called the output layer while the middle layer is called the hidden layer. So how does the above model help us classify or rather identify characters?
Consider the input layer as the most granular layer where raw data is fed. In this case, the raw data is 2D image reshaped into a 1D array. The pixel values are multiplied by the weights and the data is propagated to the next layer. As the information reaches further from the input layer, the model gains an abstract understanding of the image with decreasing granularity. In the last layer, that is, the output layer, the text in the image is identified and converted to digitized text.
In order to correctly recognize the printed text, the model must be trained. Training is the process of adjusting the weights attached to each perceptron. In order to train the model, we need a labeled dataset. The idea is to randomly initialize the weights and feed the labeled data as input. The model then tries to predict and recognize the labeled training data. Since the weights are randomly initialized, the output is far from the actual values. So the weights are tuned and adjusted by backpropagation until the model’s accuracy improves. More the training data and better the quality of labeled dataset, better is the model.
Tesseract
Between 1984 and 1994, HP developed an open-source Optical Character Recognition engine famously known as Tesseract. As a first step, Tesseract does a connected component analysis in which the outlines are stored. The outlines are then gathered into blobs. Blobs are then organized into text lines which are further broken into words. Recognition then proceeds as a two-pass process.
In the first step, an attempt is made to recognize each word in turn. Each word that is identified with good confidence is passed into adaptive classifier as training data. Since the adaptive classifier may have learned something useful further down the page, a second pass is run over, in which words that were not recognized with confidence in the first pass are recognized again. During recognition, features of a small fixed length are extracted from the outline and are matched many-to-one against the clustered prototype features of the training data.
Following is the simplest code snippet demonstrating the performance of tesseract. Note that textract (another Python-based library) is a wrapper around tesseract:
import textract text = textract.process(‘sample_img1.png’, method=’tesseract’) print (text)
The snippet is tested with the following input image (saved as “sample_img1.png”)

 It is evident from the above result that tesseract is very efficient in character recognition.
It is evident from the above result that tesseract is very efficient in character recognition.
Applications of Optical Character Recognition in the Industry
Optical Character Recognition is widely used in many industries. Here are some simple use-cases:
- Scanning cheques: Cheques are scanned using Optical Character Recognition-enabled machines so as to extract basic information like cheque number, debit account number, branch code, etc. This saves a lot of manual time and efforts.
- Extracting information from Identity Proof: Many banks and insurance companies across the world use Optical Character Recognition to quickly extract customer details like Name, Phone number, Address, Date of Birth, etc. from the identity proof.
- Law firms: Many Law firms in the US use Optical Character Recognition to scan and digitally store the legal documents. This enables them to allow “searching” through the Legal documents.
- Invoicing: Optical Character Recognition systems are recently being used to scan and extract data from invoices. A typical invoice of a medical wholesaler may contain hundreds of entries which is quite cumbersome for a manual data entry process. Optical Character Recognition saves a lot of time by automating this process.
Conclusion
Many standard libraries in various programming languages have been developed by researchers which are highly efficient in Optical Character Recognition. As such one can use these libraries “out-of-the-box” rather than reinventing the wheel. These libraries provide great results and can be widely used in various applications as explained above.


