

Introduction
Neural Networks (NNs) are the most commonly used tool in Machine Learning (ML). By the end of this article, you will be familiar with the theoretical concepts of a neural network, and a simple implementation with Python’s Scikit-Learn.
Neural Networks in Theory
In Supervised Learning ML techniques, at first, the model must be trained on some data. Neural networks traditionally follow Supervised Learning, and the network improves its accuracy over iterations/epochs. A neural network is a statistical tool to interpret a set of features in the input data and it tries to either classify the input (Classification) or predict the output based on a continuous input (Regression).
Data Pre-processing
It consists of algorithms, such as normalization, to make input data suitable for training. Normalization is done to ensure that the data input to a network is within a specified range. A typical normalization formula for numerical data is given below:
x_normalized = (x_input – mean(x)) / (max(x) – min(x))
The formula above changes the values of all inputs x from R to [0,1]. There are various preprocessing techniques which are used with the aim of applying a linear transformation, or detecting and minimizing outliers and reducing the size of the input space.
Logistic Regression and Perceptron
In a nutshell, a Logistic Regression is a Classifier, where every input is a feature set and an output are an N-dimensional vector (for N classes). Every output value is in [0,1], indicating the probability of an input belonging to the corresponding class. A Logistic Regression model is a one-layered neural network. A perceptron is the same as Logistic Regression, but with a different activation function, producing an output in {-1, 1}.
When multiple perceptrons are used in layers, it essentially forms a neural network.
Bias and Variance
In a network, Bias can be considered as the DC component of a neuron: The output of the neuron is shifted by B. This can be understood clearly in the next section.
In terms of training, the bias and variance define the dataset: If a dataset has too many samples for an output, the network becomes biased toward it. Variance is the error produced due to the variety of samples associated with an output, and high variance implies that the algorithm models the randomness of the data and leads to overfitting. Thus, you will be staring at a trade-off between bias and variance: Bias-Variance Tradeoff
Weights
Every node in the neural network has a weight W associated with it. If the input to a neuron is X, then the output it produces is WX+B (B=bias)
A sample network is shown in the figure below. Each circle represents a neuron which has a weight W associated with it.
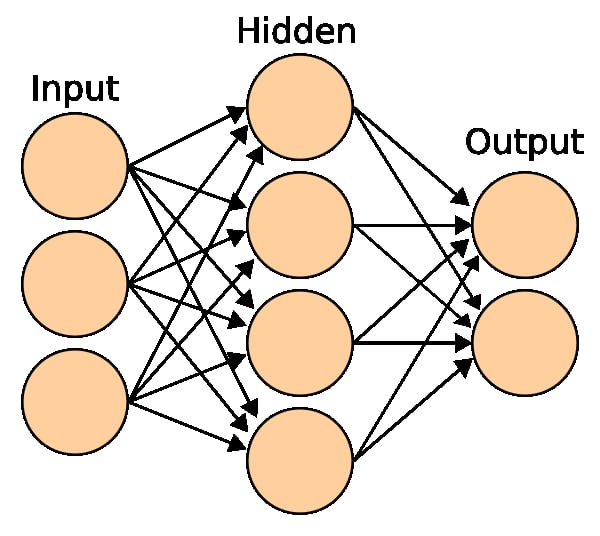
Activation Function
An activation function is what separates a neural network from a vanilla linear regression model. It defines a function, which enables the neuron to convert an input to an output value. The most common activation functions for hidden layers of a neural network are:
- Sigmoid: f(x) = 1/1+e^(-x). [Range: (0,1); slow convergence; non-zero mean-value]
- Tanh: f(x)=1-e^(-2x) / 1+e^(-2x). [Range: (-1,1); quick convergence; zero mean-value]
- ReLu: f(x)=0 (if x<0), x (if x>=0). [Range: R+; ReLu can lead to dead neurons]
- Leaky ReLu: f(x)=-ax (if x<0), ax (if x>=0). [Range: R; Used to avoid dead neurons]
In the output layer of the neural network, the softmax activation function is used for classification and the linear activation function is used for regression.
Training a network
Undoubtedly, the most important part of a neural network is the dataset. When building a model, you must have three partitions in your dataset:
- Training Data: For any implementation, the first thing required will be the training data. This is the data that your model iterates over continuously and updates itself to improve its accuracy.
- Validation Data: You should use some samples from your dataset which are NOT seen in the training data, this gives you an estimate of the model’s skill in terms of tuning the hyperparameters. The validation dataset is important in order to avoid overfitting the network.
- Test Data: The test data contains all samples that the model is likely to see in its usage, it can contain samples present in training data and validation data. This data is used to find the accuracy/predictive capabilities of the model.
You may either partition the dataset randomly (NumPy is helpful in such cases) or have the dataset split before you load the training, validation, and test data in your code. It is always good to use samples from the training and validation data in your test data.
Cost Function
The cost function of a network is used in the update process after every iteration. There is a variety of cost functions available such as Distance functions, Mean-Square-Error (MSE), Bernoulli log-likelihood, Exponential cost, etc. The cost function is application-dependent.
A Simple Implementation in Scikit-Learn
import sklearn
## import the iris dataset for classification
from sklearn import datasets
iris=sklearn.datasets.load_iris()
## print some data, to see the imported dataset
print("Printing some sample data from the iris dataset")
for training_sample in list(zip(iris.data,iris.target))[:5]:
print(training_sample)
## save the features and class
features=iris.data # split iris dataset into features and iris_class
iris_class=iris.target # class[X] is output corresponding to features[X]
## Split the dataset into training (70%) and testing (30%)
## Note that the shuffle parameter has been used in splitting.
print("Splitting the data into testing and training samples")
from sklearn.model_selection import train_test_split
ratio_train, ratio_test = 0.7 , 0.3
features_train, features_test,iris_class_train, iris_class_test = train_test_split
(features,iris_class, train_size=ratio_train,test_size=ratio_test, shuffle=True)
## data preprocessing: Before training the network we must scale the feature data
print("Data preprocessing")
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(features_train)
features_train_scale = scaler.transform(features_train)
features_test_scale = scaler.transform(features_test)
## The MLPClassifier and MLPRegressor are sklearn implementations of NNs
from sklearn.neural_network import MLPClassifier
iterations=1000 # define the iterations for training over the dataset
hidden_layers=[10,10,10] # define the layers/depth of the NN
print("Creating a neural network with "+str(len(hidden_layers))+"
layers and "+str(iterations)+" iterations")
mlp = MLPClassifier(hidden_layer_sizes=(hidden_layers), max_iter=iterations)
# an object which represents the neural network
# Remember to use the pre-processed data and not original values for fit()
mlp.fit(features_train_scale, iris_class_train) # fit features over NN
## Run the test data over the network to see the predicted outcomes.
predicted = mlp.predict(features_test_scale)
# predict over test data
## evaluation metrics and analysing the accuracy/output.
print("Evaluation: considering the confusion matrix")
from sklearn.metrics import confusion_matrix
print(confusion_matrix(iris_class_test,predicted))
# all non-diagonal elements are 0 if you get 100% accuracy
print("Evaluation report:")
from sklearn.metrics import classification_report
print(classification_report(iris_class_test,predicted))
#f1-score/accuracy
Conclusion
In this article, we built a simple Neural Network in sklearn for classification on the iris dataset. Depending on the development of a model, you should be tuning its hyperparameters and carefully choose an appropriate evaluation metric.
You should also consider reading about the Keras and Tensorflow Python libraries, which are two of the most commonly used libraries for developing neural networks.



{kind=link}