


Welcome, welcome, welcome!
A very warm welcome to all our readers to this very special blog that marks the end of what has truly been a long albeit an incredible journey!
We’ve built everything, right from the basic concept through to implementing a CycleGAN – one of the most complicated GAN architectures there is!
And oh my my! Even after 4 blogs, we’re still thinking, where do we even start?
Such is the impact GANs have left on the Machine Learning Community and the world in general.
More from the Series:
- An Introduction to Generative Adversarial Networks- Part 1
- Introduction to Generative Adversarial Networks with Code- Part 2
- pix2pix GAN: Bleeding Edge in AI for Computer Vision- Part 3
- CycleGAN: Taking It Higher- Part 4
In all the previous four blogs, we focused heavily on the concept and the details of implementation which left us a little out of time and space to bring forward the myriad of creative applications GANs have found since their introduction in 2014.
It’s like this, at Eduonix, we believe if our students are not properly exposed to the applications of a particular concept, they will always lack somewhere in their full potential to apply it themselves than they would have if shown a variety of diverse use cases.
For us, it’s pretty basic, creativity stimulates creativity.
So that’s our agenda for today. Our only agenda. And we’ll go all out making sure we cover maximum applications of GANs.
You might not think that programmers are artists, but programming is an extremely creative profession. It’s logic-based creativity– John Romero
Undoubtedly, GANs have proved Mr. Romero right. If to conjure a configuration where one neural network (Generator) tries to face off another neural network (Discriminator) in a virtual showdown, it is not creativity, we don’t know what is.
While solving Artificial Intelligence, and by that we mean, a completely self-sustaining, self-evolving algorithm or machine, is still a dream of the far future, GANs have made some incredible breakthroughs in Artificial Intelligence. Specifically, in Computer Vision.
Okay, enough introduction! Let’s get to the fun stuff!
Data Augmentation.
A question to the readers, what is the most important thing before starting work on a project or a problem statement?
Now, of course, each one of you will have different priorities for different things, but one thing in common which all the readers will agree on will be data.
But often in most practical settings, the problem starts with the data itself. Either there’s no relevant data or not enough of it.
Consequently, a lot of time is used up in making, sure enough, data is available for the problem we’re trying to solve.
In such cases, teams prefer to use a technique called Data Augmentation.
Data Augmentation is nothing but selecting images at random from the already existing dataset and performing operations like rotations to a random degree, flips, mirroring the image, blurring or sharpening the image, changing the color of the image by passing through color filters, etc. to artificially increase the size of the dataset.
This sounds like a pretty good workaround except, the augmented data is not data the network will never see. That is, it is not a completely new image. All the augmentation operations ensure that when the network is trained, it has generalized well enough to deal with cases where the input image is not in the ideal expected format like when images are skewed off by some angle or the external lighting of the testing scenario gives an apparent shift in color of the image. What it does not ensure, however, is significantly better feature extraction than it would have performed when it was trained on the dataset without augmentations.
But GANs have completely changed the game of Data Augmentation.
GANs are now being used to generate new different training samples rather than just performing rotations on the existing samples. This goes hand in hand with GANs’ uncanny ability to produce extremely realistic synthetic new examples from the existing ones, something we’ve seen throughout the four blogs covering different GAN architectures. We’ve shown a progression of GANs from 2014 to 2017 in their capability of generating realistic images.


New unique examples, mean better feature extraction, better generalization and hence better results as opposed to just better generalization by typical data augmentation techniques.
In a hybrid scenario, conventional data augmentation along with GAN based synthesis is used to boost both – better feature extraction and better generalization.
If it is still difficult to understand why one would go through so much trouble just to boost the performance, consider a scenario where an interior designing company wants to design an AI solution where a network which can identify most elements in a bedroom.
Two problems:
- There can be an astronomical of things in a bedroom which may vary from household to household
- The location of all these items might be different for different people.
The first problem can be countered by defining a finite number of broad categories like, ‘furniture’, ‘stationeries’ etc. But the only way to combat the second problem is to have a large database of bedroom pictures so that the network can map the general possible locations of the categories defined.
In cases where bedroom photos are limited or the collection procedure expensive, GANs can be used to generate synthetic bedroom photos.

Translations.
Solving for image-to-image translation is what we’ve pretty much based all of our GAN architectures on in the previous blogs. But even then, apart from the datasets used in the coding examples which included the Satellite to Google Map translation and the Horses to Zebras and Zebras to Horses translation, we’ve not really covered what other possible use cases for image translation models such as the pix2pix GAN or the CycleGAN could be.
In addition to that, we’ve also not looked at different types of translations other than image-to-image translations.
In this section, we’ll look at some new use cases where we can make use of translation GANs.
First up, are some use cases for image translation that we had not covered previously and these include:
- Cityscapes to Nighttime
- Painting to Photograph
- Sketch to Photo



This might still be something on the lines of what the readers already know to expect, but here’s something really mind-boggling for you guys!
Text-to-Image Translation
Yup. You read it right.
Yup. You understood it right too.
From only a short linguistic description, GANs have been shown to conjure realistic images perfectly matching those descriptions.
How in the world does that work?
Oh, we’ll come to it! But first, let us look at the results!

That’s really awesome!
It’s got us excited especially because generating photo-realistic images from text is an important problem and has such tremendous applications, including photo-editing, computer-aided design, etc.
Imagine if you could just describe how you want the photo to look, and your computer or your mobile phone would do that for you! No-fuss!
However, it is very difficult to train GAN to generate high-resolution photo-realistic images from text descriptions. Simply adding more upsampling layers in state-of-the-art GAN models such as the Vanilla GAN, pix2pix GAN or the CycleGAN for generating high-resolution images generally results in training instability and produces nonsensical outputs as can be seen in Figure 8. (c).
So if our Vanilla GAN, pix2pix and CycleGANs won’t do the trick? How was this problem solved?
The answer is in a paper by Han Zhang et al. titled StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
(https://arxiv.org/pdf/1612.03242.pdf)
Wait. Stack-what??
StackGAN sounds like a completely new GAN architecture except that it’s not. In fact, it has just two GANs stacked up in two stages, Stage I and Stage II.
To generate high-resolution images with photo-realistic details, we propose a simple yet effective Stacked Generative Adversarial Networks. It decomposes the text-to-image generative process into two stages
- Stage I GAN: it sketches the primitive shape and basic colours of the object conditioned on the given text description, and draws the background layout from a random noise vector, yielding a low-resolution image.
- Stage II GAN: it corrects defects in the low-resolution image from Stage I and completes details of the object by reading the text description again, producing a high- resolution photo-realistic image.
The results from each of Stage I and Stage II are presented below along with a third result comparing StackGANs with vanilla GANs

This concept was further worked upon by many researches in the community to come up with even more realistic images such as by Ayushman Dash et al (https://arxiv.org/pdf/1703.06412.pdf), results shown below:

You could go through the literature to find more such examples, there are many such as one by Scott Reed, et al. titled “Generative Adversarial Text to Image Synthesis”
(https://arxiv.org/abs/1605.05396)
Bokeh-Mode!
We’ve all wondered how a single-lens camera in our mobile phones can produce portrait mode photos like a professional DSLR!
Of course, we have a marketing name for that called, “Bokeh-Mode” but it would be interesting to know for the readers that in many phones, this Bokeh-Mode is just a GAN at work in the background!

So the next time someone tries to show off their Bokeh-Mode, just tell them it’s nothing special and that you can achieve the same results within half a day by an algorithm made by you on your laptop completely free of cost and watch their reaction!
Graphics Landscapes-to-Photo Translation
This is for all you gamers at heart! Imagine if you could convert any gaming landscape into reality or vice versa!
In this blog, we show a really creative application of CycleGAN applied to the Grand Theft Auto franchise where GTA landscapes are converted to photo-realistic landscapes!
Even though this might seem only just a fun thing to do and nothing serious, its applications are pretty wide in the gaming industry. Because we learned in the CycleGAN blog that you can achieve reverse translation too! This means a realistic landscape can be converted to a GTA landscape within seconds or even in real-time as we’ll shortly show you! And this is not just limited to GTA, any game could have their landscapes generated this way! This paves way for the design of ultra-realistic Virtual Reality and Augmented Reality games with significantly less effort!

Now as promised, we’ll show you the reverse conversion in real-time! That is, generating GTA landscapes from real city landscapes!
And what better way to show this than a video? So we’ve gone ahead and dug up a really cool video for you guys to watch!
https://www.youtube.com/watch?time_continue=20&v=lCR9sT9mbis&feature=emb_logo
Now that we’ve satisfactorily covered all possible varieties of translations, let’s move on to something even more fun!
Face Frontal View Generation
Let’s just admit it. In how many movies have we seen those ultra technicians that will give you a perfect face match based on a rundown CCTV footage of the criminal taken from like a mile away with the full face not even visible????
Like we’re living in 2019 and they’re living in 2099???
Well, we have news for you fellas. Those movies just might be able to get away from your criticism now.
Rui Huang, et al. in their 2017 paper titled “Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis” (it’s alright fellas the name isn’t important the concept is), demonstrate the use of GANs for generating frontal-view photographs of human faces given photographs taken at an angle.
The idea is, of course, that the generated front-on photos can then be used as input to a face verification or face identification system finally a fantasy come true for all those crime film directors living in 2099s!
Sarcasm apart here is the link to the paper should the reader want to go through it, we will, of course, show you some of their results right here!
(https://arxiv.org/abs/1704.04086)
Of course, methods of generating the frontal already existed pre-GAN area but the results weren’t half as good or accurate. In fact, some results hardly qualified as results because they did not generate a face at all!
We’ll show you!


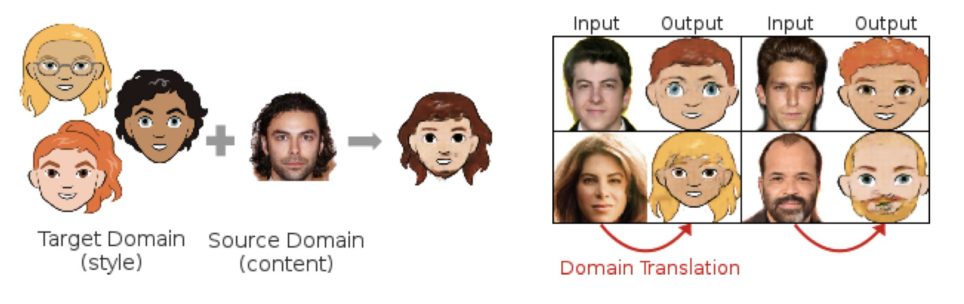
Photos to Avatars
![]()
Well, now you know where our cover page came from!
Emojis are a household name today in 2019. Even our parents and possibly even our grandparents know what emojis are and how they to use them. They’re concise, they’re expressive and above all, they’re just fun!
After Emojis, with the rise of social apps like Snapchat, came the Bitmoji’s and now the latest thing to arrive in this area are the Memoji’s and Animoji’s by Apple!
We’re sure explanations are not needed into what Animoji’s, Memoji’s and Bitmoji’s are, so we’ll just get to the point here!
To create a Bitmoji, there are several templates available and you can choose any and then customize various templates for hairstyles, skin color, add glasses to your Bitmoji, etc.
This gives us our Bitmoji which is accuracy to a degree since we’re the one that has created it, but not so much because it’s limited by the templates provided.
Now as you can expect, in various papers in post-GAN floated this idea of a direct Bitmoji translation using GAN architectures. Just show your photo and boom! You have a Bitmoji instead of going over all those templates and finding there’s none that matches you perfectly!
We’ve shown the results below for this and even though they’re not a hundred percent convincing, they’re still the way forward and after improvements, GANs will be the way to go for creating Bitmoji’s!
But this is not limited to Bitmoji’s. The internet is all abuzz with different ‘avatar’ creating websites. Especially cartoon creating avatars. But even that domain has been taken over by GANs!
A GAN architecture called the XGAN has seen tremendous success in creating fun cartoon avatars directly from photos! We’ve shown the results for those too below!

Speaking of Avatars, there’s something we cannot forget especially in 2019! The FaceApp fiasco!
The FaceApp offered to generate older images of a user after the user uploads a photo of themselves! Of course, it was a ploy to siphon off millions and millions of face images for personal data collection purposes, but before the general public was made aware of this, many had already used the app multiple times!
Nevertheless, we’re interested only in the technology they used which as you can guess, was undoubtedly GAN based!
Both face again and face de-aging can be performed by GANs as we’ll show below:


Motion Stabilisation & Super Resolution
One of the most widespread uses of GANs is seen in the way Motion Stabilisation and Super Resolution is carried out in imaging systems.
If the readers are able to faintly recollect, in the Functional API with Keras blog where we introduced Functional API to you, we had taken up the problem of the GoPro dataset de-blurring task. We’ve presented some samples from the GoPro dataset as a refresher below:

The dataset consists of thousands of such sharp-motion blur pairs of various natural scenarios such as the example provided above.
Motion blur can happen even with the best DSLR cameras today and along with fast switching hardware circuits, a software component is essential to digitally de-blur the motion spread image which GANs have obviously bossed.

Blurred – left, DeblurGAN – center, Ground Truth Sharp – right
taken from the paper “DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks.”
Such motion de-blurring or motion stabilization GANs are critical not just in handheld imaging systems like a camera but also help in the task of the future like autonomous driving and autonomous navigation. We’ve shown yet another image which presents the power of de-blurring GANs in boosting object detection of state-of-the-art object detection algorithms like the YOLO algorithm in autonomous driving/navigation applications.
Another task that we mentioned was photo super-resolution which is just sharpening of a dull or smooth image, enhancing its features and contrast. GANs have proved powerful in super-resolution tasks rendering almost all the previous super-resolution algorithms totally obsolete.
We’ve presented results for all of these discussions below:

restored image (middle) and the sharp ground truth image from the GoPro dataset (bottom)

Deep Fakes
Surely this thought might have dawned on the reader, “If GANs are so powerful, is it possible to misuse them?”
The answer, unfortunately, is yes.
Before we proceed further and tell you how we implore the reader to first go through this video:
https://www.instagram.com/p/ByaVigGFP2U/?utm_source=ig_embed&utm_campaign=embed_video_watch_again
“Imagine this for a second: One man, with total control of billions of people’s stolen data, all their secrets, their lives, their futures,” the video says.
This video is not real. Yet, this deepfake blinks moves seamlessly, and gestures like Zuckerberg would.
So what is ‘Deepfake’ and how is it created?
Deepfake is a GAN based technology used to produce or alter video content so that it presents something that didn’t, in fact, occur.
Deepfake video is created by using a GAN. Basically, the generator creates a fake video clip and then asks the discriminator to determine whether the clip is real or fake. Each time the discriminator accurately identifies a video clip as being fake, it is sent as critic feedback to the generator which then attempts to create better and even better deception when creating the next clip. As the generator gets better at creating fake video clips, the discriminator gets better at spotting them. Conversely, as the discriminator gets better at spotting fake video, the generator gets better at creating them.
This process goes on as we’ve learned in all our GAN blogs. And the result is a sinister and almost convincingly real deepfake video.
And clearly, this is not ethical.
The rise of deepfakes presents many dangers because as deepfakes are created by a GAN, they don’t require the considerable skill that it would take to create a realistic video otherwise which unfortunately means that just about anyone can create a deepfake to promote their chosen agenda. So while one danger is that people will take such videos at face value; another is that people will stop trusting in the validity of any video content at all.
This makes a lot of people nervous, so much so that Marco Rubio, the Republican senator from Florida and 2016 presidential candidate, called them the modern equivalent of nuclear weapons. Even though that is a bit exaggerated, the threat is unequivocally real.
For further reading and more intricate details, we’d like the reader to check out this wonderful article we’ve already on deep fakes (https://blog.eduonix.com/artificial-intelligence/deepfake-black-mirrorish-application-ai/)
Thank you, readers, it’s a wrap from our side!
As education institutions for whom empowering students to better the world is a founding cornerstone, we see it as our responsibility to warn the students of such malicious use of really innovative technology as we’ve seen in these 5 blogs.
There’s so much, so much, that GANs can be used to bring good, positive change to this world, one application at a time. And we hope that in these five blog series we’ve given you students all the possible tools to be thoroughly well equipped with GANs, right from the baby concepts through to implementation and its myriad applications!
In future blogs, we hope to bring you even more exciting blogs on various cutting edge Artificial Intelligence tools and algorithms!
Until next time!
Begin With Keras Series:
- Deep Neural Networks with Keras
- Functional API of Keras
- Convolutional Neural Networks with Keras
- Recurrent Neural Networks and LSTMs with Keras
Read previous blogs from GAN Series:
- An Introduction to Generative Adversarial Networks- Part 1
- Introduction to Generative Adversarial Networks with Code- Part 2
- pix2pix GAN: Bleeding Edge in AI for Computer Vision- Part 3
- CycleGAN: Taking It Higher- Part 4
Read More:
- Artificial Intelligence in Space Exploration
- AI Dueling: Witness the New Frontier of Artificial Intelligence
- Artificial Intelligence Vs Business Intelligence
- Role of Artificial Intelligence In Google Android 9.0 Pie
- How Smart Contract can Make our Life Better?
- Why Every Business Should Use Machine Learning?
Looking for Online Learning? Here’s what you can choose from!
- Deep Learning & Neural Networks Using Python & Keras For Dummies
- Learn Machine Learning By Building Projects
- Machine Learning With TensorFlow The Practical Guide
- Deep Learning & Neural Networks Python Keras For Dummies
- Mathematical Foundation For Machine Learning and AI
- Advanced Artificial Intelligence & Machine Learning (E-Degree)


