

Recently the CES 2020 concluded in Vegas and for those who aren’t aware, CES is the annual trade show for consumer electronics around the world. As such, it an excellent indicator of the direction consumer technology is heading towards in the coming years.
For exampple, the cover image presents to you Neon developed by Samsung’s STAR Labs which are Artificial Intelligence-powered virtual beings that look and behave like real humans. Unlike AI assistants like Siri or Alexa though, Neon isn’t programmed to be “know-it-all bots” or an interface to answer users’ questions and demands. Instead, the avatars are designed to converse and sympathize “like real people” in order to act as hyper lifelike companions. This includes being able to move, express themselves, and speak. They can also remember and learn things about their user, and speak in any language. CEO Pranav Mistry further explains the vision he has for his Neon.
“Neon is like a new kind of life. Neons will be our friends, collaborators, and companions, continually learning, evolving, and forming memories from their interactions.” – Pranav Mistry, Neon’s CEO.
Apart from Neon, there were various innovative products revolving around AI and specifically, Deep Learning.
So that’s wonderful but how is this relevant to the topic at hand you might ask.
Well, CES is often quoted to be the window to the future and that window has shown us that going into this new decade, it’s not going to be possible to talk about technology without in some part involving Artificial Intelligence or Machine Learning & Deep Learning (to be precise).

At Eduonix, we’ve thoroughly covered the officially supported Deep Learning API of Keras. If you’ve missed out, be sure to check the Keras series.
Articles from Kerass Series!
- Deep Neural Networks with Keras
- Functional API of Keras
- Convolutional Neural Networks with Keras
- Recurrent Neural Networks and LSTMs with Keras
Now because Deep Learning is such an active field, every once in a while something comes along that has the potential of changing the landscape in the field of Deep Learning. Facebook’s PyTorch is one such library. Since its stable release in early October 2018, many researchers have adopted it as a go-to library because of its ease of building a novel and even extremely complex graphs. So in the next few blogs, we’ll scuba dive into PyTorch starting with the one today!
Before we start with today’s agenda, however, it would be unfair for us to proceed before making a proper case for the readers of why this blog is worth any of their time. So here’s a little graph showing the unique mentions of PyTorch (solid lines) vs TensorFlow (dotted lines) in various global conferences (marked out with different colors).
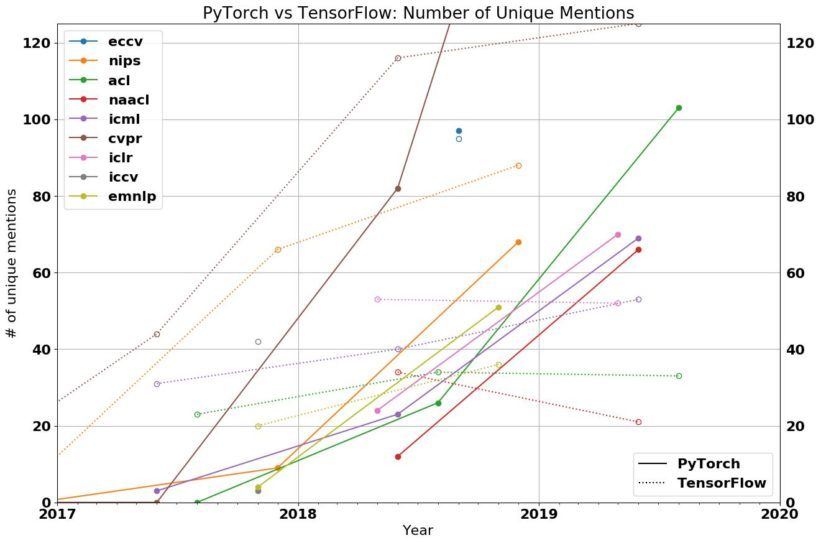
To put this into perspective, consider the tabulation below:
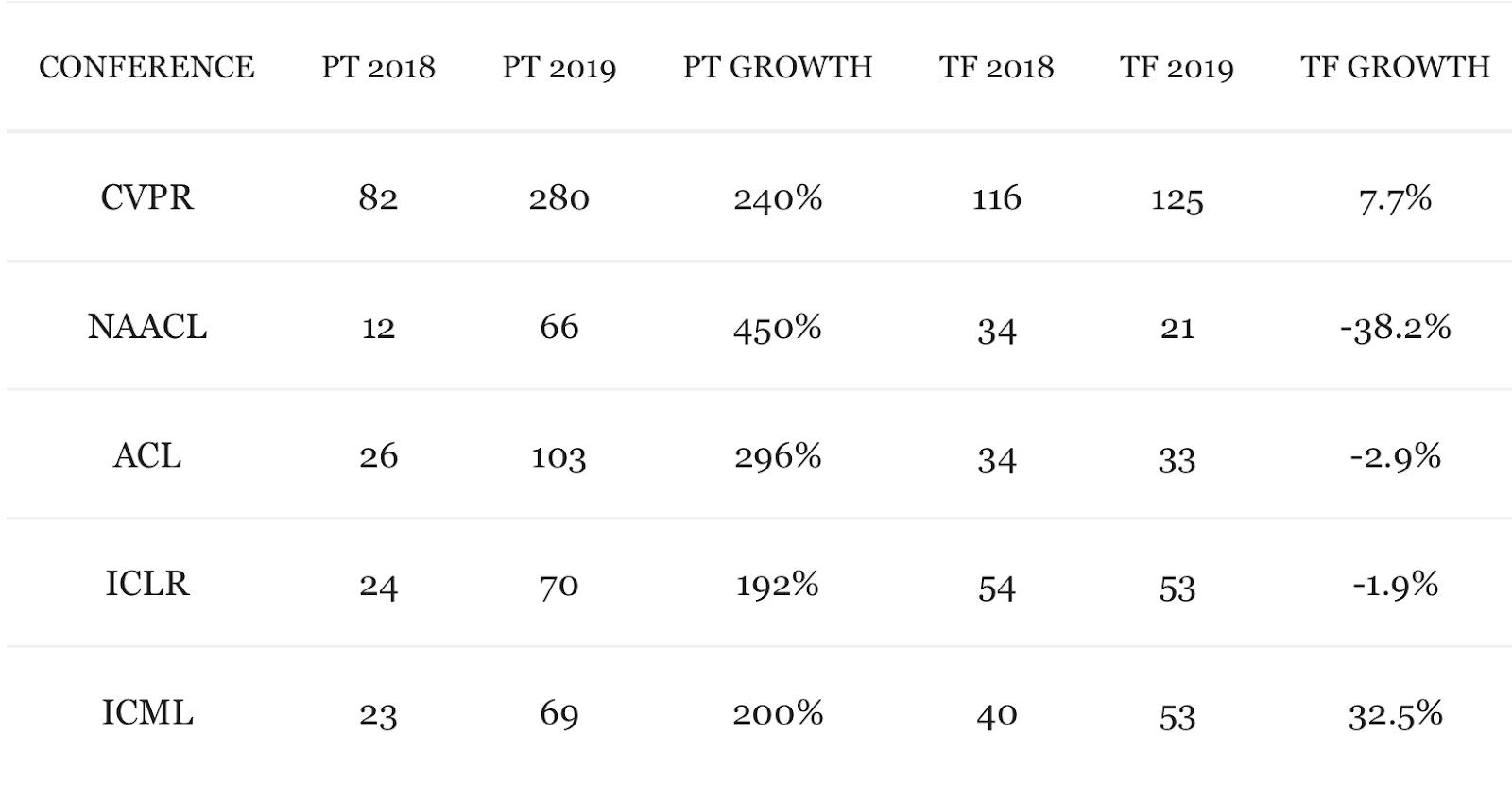
But hey! We get it. You’re not into research really rather just an Artificial Intelligence practitioner! Well, here’s another bit of data to put things into even better perspective for the practitioners:
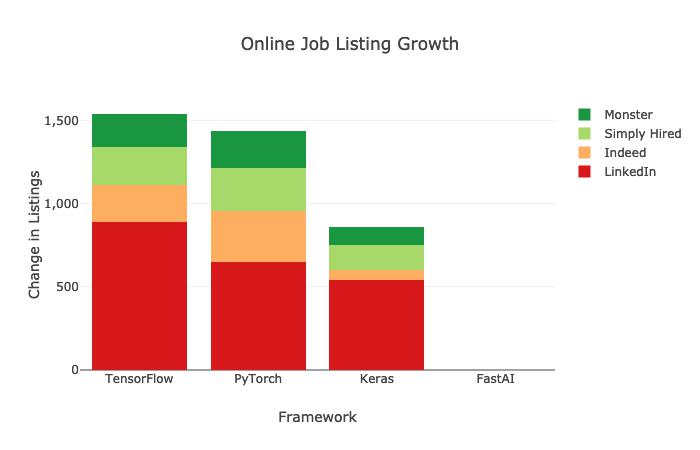
By the end of 2019, TensorFlow had 1541 new job listings vs. 1437 job listings for PyTorch on public job boards. Considering TensorFlow came out several years earlier than a stable release of PyTorch did and the research community, as well as the industry, had adopted TensorFlow as the de facto standard already by then, it’s now come pretty neck to neck between the two.
Read More: A Beginners Guide To Tensorflow – What Is The Big Deal?
A quick note to the readers: although it may seem like Keras is far out in the race, Keras is now officially bundled with every release of TensorFlow which means TensorFlow and Keras is very closely linked to each other. So your Keras expertise is not in vain but quite the opposite in fact!
We’d like to think we’ve made a pretty convincing case for the people working in the industry and also for the practitioners. But if you’re an enthusiast or a hobbyist, just here for the fun, we reckon you’d be just fine ignoring PyTorch since most of the research papers still do have TensorFlow versions of their code released along with the PyTorch versions for you to look at. But we implore you to make this investment today because we don’t know how long it is until TensorFlow versions of the code stop being released altogether by researchers and everything is just PyTorch within the research community. Maybe this year, or the next, who knows? But the dark horse is taking the lead that’s for sure!

Hold up! But what exactly is this PyTorch thing?
Finally! We’re glad you asked. So surprise surprise but PyTorch is not just a Deep Learning framework. The creators had two goals with PyTorch:
- A replacement for NumPy.
- A deep learning platform that provides maximum flexibility and speed.
Let’s start with the first one.
NumPy and PyTorch
We’re all familiar with NumPy and take it for granted because it’s one of the things that just happen to be there somehow in every Machine Learning program???
Well, the reason is that in Machine Learning or Deep Learning, we work with multidimensional arrays. For example, an image is often represented as an array of (height, width, number of color channels). So, for a grayscale (no color) image, we’d represent it as an array of shape (height, width, 1). Similarly, for a color image that would change to (height, width, 3). This is all very standard. It’s also standard to use NumPy to initialize these arrays. In scientific computing, these multidimensional arrays are called ‘Tensors’. I mean, it’s just neat because now instead of calling an image a multidimensional array, I can just call it a tensor.
It goes something like this, a scalar (a single number) has zero dimensions, a vector has one dimension, a matrix has two dimensions and a tensor has three or more dimensions. That’s it!

However, there’s a catch when you use NumPy arrays for computations. You cannot directly leverage the power of GPUs. PyTorch on the other end provides a framework to define tensors with direct GPU compatibility. So basically, PyTorch tensors are similar to NumPy’s arrays, with the addition being that PyTorch tensors can also be used on a GPU to accelerate computing. This is clearly an advantage over NumPy since Deep Learning heavily relies on GPU based model training.
Okay okay, that’s great. But how do I define a PyTorch tensor?
Right. Syntactically, defining a tensor in PyTorch is a breeze. But first, let us install the PyTorch library.
# Python 3.x pip3 install torch torchvision # Python 2.x` pip install torch torchvision # Anaconda conda install pytorch torchvision -c pytorch
Now, let us construct a randomly initialized tensor:
import torch x = torch.rand(5, 3) print(x)
Out:
tensor([[0.7799, 0.1989, 0.5753],
[0.4624, 0.5366, 0.7436],
[0.8719, 0.9631, 0.3204],
[0.8461, 0.0422, 0.3457],
[0.9910, 0.8967, 0.5962]])
Now, to construct a tensor filled zeros and of dtype long:
x = torch.zeros(5, 3, dtype=torch.long) print(x)
Out:
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
That’s how simple it is! Just like NumPy! In fact, you can use standard NumPy-like indexing on these tensors too!
print(x[:, 1])
Out:
tensor([0.1989, 0.5366, 0.9631, 0.0422, 0.8967])
The syntax for addition remains exactly the same as for NumPy. For multiplication, we can use the torch.matmul(x, y) and for division, torch.div(x, y) where x and y are PyTorch tensors.
Hey! You know what? That’s cool. But why should I adopt PyTorch when I’m already so comfortable with NumPy?
Ah! See that’s the thing. PyTorch is not expecting that you migrate over to PyTorch leaving NumPy. In fact, NumPy arrays and PyTorch tensors are interconvertible!
We use the from_numpy() method!
import numpy as np # define a NumPy array a = np.ones(5) # convert into pyTorch tensor b = torch.from_numpy(a) # change the NumPy array np.add(a, 1, out=a) print(a) print(b)
Out:
[2. 2. 2. 2. 2.] tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
Notice how changing the NumPy array changed the PyTorch Tensor automatically!
We’ve mentioned earlier that the entire power of PyTorch over NumPy lies in able to leverage GPU acceleration. But what is the syntax for it?
So let’s say we’ve got NumPy arrays and access to a GPU and would like to speed up our computations using PyTorch,
Here’s how we go about it:
import torch # check if a GPU device is available. If not, use the CPU device = 'cuda' if torch.cuda.is_available() else 'cpu' # The data is in NumPy arrays x and y, but we need to transform them into PyTorch's Tensors to leverage GPU speed. # So we convert them using earlier syntax and then we send them to the chosen device x_tensor = torch.from_numpy(x).to(device) y_tensor = torch.from_numpy(y).to(device)
Simple as that!
PyTorch seems a good choice for a GPU. But what if I don’t have one? Why should I use PyTorch then?
That’s a very valid question. So let us throw some speed tests your way.
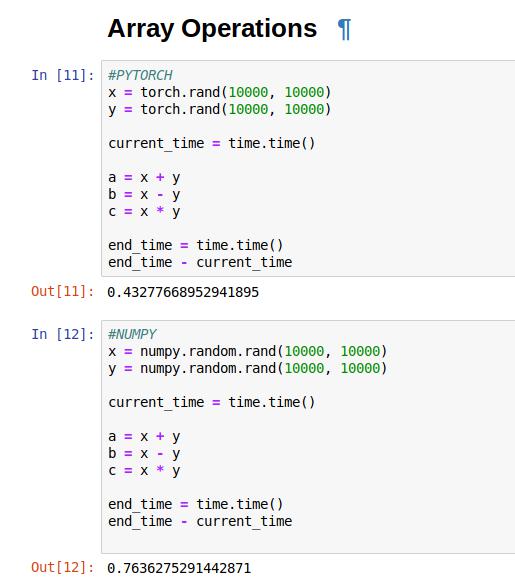
Clearly, PyTorch is faster than NumPy in basic mathematical operations. This is because of the faster array element access that PyTorch provides.
Let’s go for one more speed test. We’ll take a one-dimensional vector having size 10 billion random elements. And, try to access the middle element from both NumPy, as well as PyTorch.
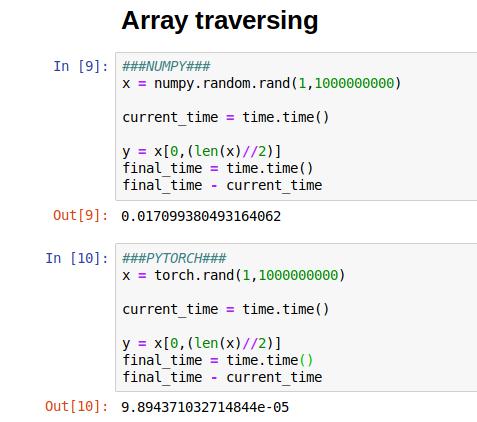
The result is decisive, PyTorch is clearly a winner in array traversing. It took about 0.00009843 seconds in PyTorch, while over 0.01 seconds for NumPy!
So should you completely ditch NumPy and use PyTorch everywhere? Not just yet. If you’re using TensorFlow, you’re probably better off using NumPy to avoid compatibility issues but if you’re using PyTorch to build your models, we highly recommend using PyTorch instead of NumPy.
Ha! Maybe I’ll just use both and convert them into each other as and when required!
While that’s a very possible thing to do, we recommend against such a practice because interconversion between these two data types is both computationally heavy, and complex. And it is best to avoid doing so.
So we talked about NumPy vs PyTorch with its basic syntax and compared the two on a variety of factors before coming to a conclusion. Now let’s move on and talk about why PyTorch has so rapidly gained popularity among the research community!
PyTorch as a Deep Learning Framework
PyTorch differentiates itself from other machine learning frameworks in that it does not use static computational graphs – defined once, ahead of time – like TensorFlow, Caffe2, or MXNet. Instead, PyTorch computation graphs are dynamic and defined by a run.
Woah Woah Woah! There’s too much happening! What does any of this even mean???
Alright. Let’s go over it nice and slow.
Dynamic vs Static Graphs
Generally, in the majority of programming environments, adding two variables x and y representing numbers produces a value containing the result of that addition.
For example, in standard Python:
x = 4 y = 2 x + y
Out:
6
However, this is not the case in a static graph environment like TensorFlow. In TensorFlow, x and y would not be numbers directly, but would instead be handles to graph nodes representing those values, rather than explicitly containing them. Furthermore, and more importantly, adding x and y would not produce the value of the sum of these numbers, but would instead be a handle to a computation graph, which, only when executed, produces that value:
import tensorflow as tf x = tf.constant(4) y = tf.constant(2) x + y
Out:
<tf.Tensor 'add:0' shape=() dtype=int32>
As such, when we write TensorFlow code, we are in fact not programming, but metaprogramming – we write a program (our code) that creates a program (the TensorFlow computation graph). Naturally, the first programming model is much simpler than the second. It is much simpler to speak and think in terms of things that are than speak and think in terms of things that represent things that are.
PyTorch’s major advantage is that its execution model is much closer to the former than the latter. At its core, PyTorch is simply regular Python, with support for Tensor computation like NumPy, but with added GPU acceleration of Tensor operations as we’ve seen above.
One of the many reasons for PyTorch gaining popularity is because, going back to the simple showcase above, we can see that programming in PyTorch resembles the natural “feeling” of Python:
import torch x = torch.ones(1) * 4 y = torch.ones(1) * 2 x + y
Out:
6 [torch.FloatTensor of size 1]
The choice of using static or dynamic computation graphs severely impacts the ease of programming. The aspect it influences most severely is the control flow.
In a static graph environment, control flow must be represented as specialized nodes in the graph. For example, to enable branching, TensorFlow has a tf.cond() operation, which takes three subgraphs as input: a condition subgraph and two subgraphs for the if and else branches of the conditional. Similarly, loops must be represented in TensorFlow graphs as tf.while() operations, taking a condition and body subgraph as input. In a dynamic graph setting, all this is simplified. Since graphs are traced from Python code as it appears during each evaluation, control flow can be implemented natively in the language, using if clauses and while loops as you would for any other program.
This turns awkward and unintuitive TensorFlow code:
import tensorflow as tf
x = tf.constant(2)
y = tf.constant(3)
w = tf.while_loop(
lambda x: tf.matmul(x, y) < 10,
lambda x: tf.square(x), [x])
into natural and intuitive PyTorch code:
import torch.nn
x = torch.tensor([2])
y = torch.tensor([3])
while x.sum() < 100:
x = torch.square(x)
The benefits of dynamic graphs from an ease-of-programming perspective reach far beyond this, of course. Simply being able to inspect intermediate values (like values being passed in and out of complex architecture model layers) with simple Python print statements (as opposed to tf.Print() nodes for TensorFlow) or a debugger is a big plus because computation graph in PyTorch is defined at runtime you can use our favorite Python debugging tools such as pdb, ipdb, PyCharm debugger. This is not the case with TensorFlow. At this stage, it is quite clear why a researcher would be inclined towards using PyTorch rather than TensorFlow!
Okay, I have begun to understand why PyTorch is gaining popularity with the research community but is that all the ways in which PyTorch is different from TensorFlow?
As a matter of fact, the answer is no. Apart from this, there are several other major differences when it comes to PyTorch than a framework like TensorFlow like in visualization support, pipelining support, deployment support, etc! But that’s nothing to worry about because we’ll go all of it in detail in the forthcoming blogs with the next blog being on how to define and train a Deep Neural Network with PyTorch!
We hope this has served as a basic introduction to PyTorch with the emphasis being on why the readers should invest time in PyTorch and the reason why it is gaining popularity with researchers around the world!
I hope that you liked it and we’ll see ya in the next blog!
More From The Series:
#1. PyTorch: The Dark Horse of Deep Learning Frameworks (Part 1)
#2. The Next Step: Building Neural Networks with PyTorch (Part 2)
#3. Marching On: Building Convolutional Neural Networks with PyTorch (Part 3)
Read More:
- Generative Adversarial Networks Series
- Understanding Computer Vision Techniques!
- DataOps: A Product of the Machine Learning Era
- Machine Learning on Mobile and Edge Devices with TensorFlow
- Beginners Guide To Use Dataset In TensorFlow?

")




